Judgemental Predictions are Low-Signal, High-Skill
A Simple Example
Section titled “A Simple Example”Say you want a web application to catalog information about North American fish populations. You’d probably realize that you need at least one software engineer and one expert in marine biology.
You would not ask the marine biologist to attempt to write the software themselves, because it’s unlikely they would have the expertise. You’d probably be willing to pay a lot more for a well-functioning application than a poorly organized spec sheet.
Now imagine instead you want a forecast of, “What are the chances that fish populations around New York will collapse before 2030?”
It seems obvious that you’d probably want a domain expert here, but it’s less obvious if you’d want a forecasting expert. You may have the option of hiring a superforecaster, or better yet, a team of superforecasters.
One problem is that the result of the superforecaster would look nearly identical to the one by the domain expert, or one by anyone off the street. The result could be about as simple as a probability, like “42%”.
Would you pay much more for the superforecaster to tell you “42%” than for the domain expert to tell you, say, “58%”?
The main conflict I’m raising here is that judgemental forecasts by themselves often don’t come with much information to signal how valuable they are. The result of 5 hours, 10 hours, or 500 hours of work by radically different groups of people would itself look near identical. This could mislead someone to believe that it is an easy job; “I don’t see why that superforecasting team is getting paid so much money to produce 10 guesses. I’d agree to make 10 guesses for only $10.” But looks can be deceiving.
Different forecasts can appear to be equally trustworthy, but in reality, some should be valued hundreds of times (or more) as much as others.
Forecasts can be “low-signal”, but possibly, very “high-skill.”
Is Judgemental Forecasting High-Skill?
Section titled “Is Judgemental Forecasting High-Skill?”Philip Tetlock has done a fair bit of work around answering the question of how good people are at Judgemental Forecasting, and in what conditions. His book Expert Political Judgement laid out evidence to suggest that political experts generally performed poorly at judgemental forecasting around political topics. The book Superforecasting highlights how the top talent in large forecasting competitions were able to repeatedly outperform the rest. The top 2% of forecasters in this work were labeled “Superforecasters.”
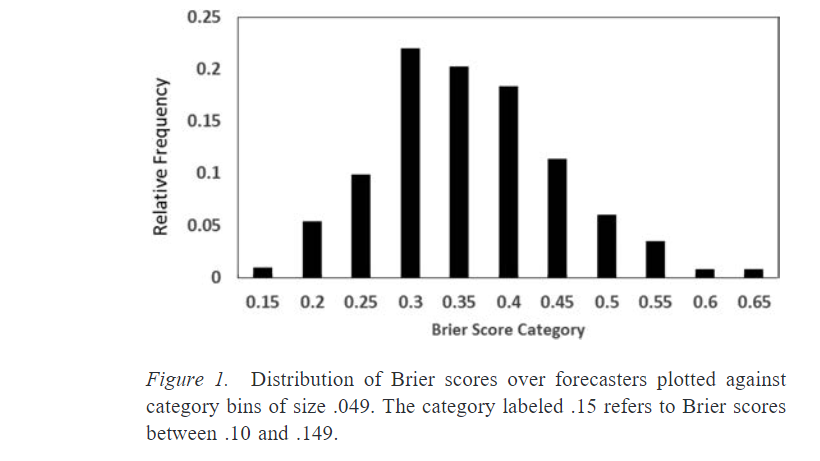
The above is a graph of the average brier score for forecasters in one of Philip Tetlock’s studies. Some forecasters clearly did significantly better than others. AI Impacts discussed this graph and related results in this post.
For this set of questions, guessing randomly (assigning even odds to all possibilities) would yield a Brier score of 0.53. So most forecasters did significantly better than that. Some people—the people on the far left of this chart, the superforecasters—did much better than the average. For example, in year 2, the superforecaster Doug Lorch did best with 0.14. This was more than 60% better than the control group.12 Importantly, being a superforecaster in one year correlated strongly with being a superforecaster the next year; there was some regression to the mean but roughly 70% of the superforecasters maintained their status from one year to the next.13
In the graph, the mean is around 0.4, and the best 2% probably averaged around 0.2. This is a highly significant difference.
A specific caveat not typically discussed is that one of the main predictors of superforecaster accuracy is just the boring work of keeping one’s forecast updated over the duration of the experiment, as David Manheim described in this comment. I think there are two considerations here. One is that consistent updating is an important attribute at times. Many “bad” forecasters are bad because they refuse to update their forecasts systematically, and that does make their averages worse. The second consideration though is that this may be bad for the “Judgemental Prediction is High-Skill” “hypothesis”. More research here would be very interesting.
A different challenge around forecasting being considered “high-skill” is that the learning curve appears to be currently much lower than it is for other acknowledged high-skill activities. It’s clear that someone needs years of medical training to become a good doctor, even if they are brilliant. With judgemental forecasting, there may only be a few weeks of obvious and explicit training. The Good Judgement Project has shown that select training is useful, but they have a very limited amount of it. [2] The rest of forecasting skill is so-far unteachable.
But there are many high-skill activities that are difficult to teach. It’s quite clear that some people do far better than many others at sales, management, stock picking, music, acting, and sports, while there is relatively little crucial academic knowledge for these areas. I think we can still consider these activities “high-skill”.
Financial trading firms and consulting firms arguably do some work very similar to judgemental forecasting. They both also hire from several different undergraduate majors and don’t have a necessary follow-up multi-year training program. One thing they do filter highly for is intellect and academic success. They often pay very well for “top” talent, despite the lack of course relevance.
Defining Low/High-Signal, Low/High-Skill
Section titled “Defining Low/High-Signal, Low/High-Skill”I’m using these terms loosely, but wanted to give possible more specific interpretations.
Low/high-signal refers to the ease at which most recipients would be able to ascertain quality. High-signal skills would be ones where it’s easy to evaluate quality. Someone who’s amazing at running quickly could prove their ability in a few minutes by running quickly, or a few seconds by showing a trustworthy website with records of their recent abilities.
If you can select someone for a job based on a 1-3-day interview, even if they have a poor resume, that’s a sign of it being high-signal. Much of software engineering works this way.
If a public speaking presentation begins with 4-8 minutes of an introduction on all of their accomplishments, it is a sign that a lot of explicit signaling is necessary, and thus a signal that their work is relatively low-signal otherwise.
Low/high-skill refers to how sensitive output quality is to input skill. Most jobs on assembly lines are explicitly crafted to not be sensitive to changes in skill. An amazing assembly-line worker may only be a very small amount more productive than an average worker. Some other jobs clearly do have high sensitivity to skill. A runner will produce a result almost directly commensurate to their own ability.
Here’s a quick attempt at a rough breakdown:
Low-Signal, Low-Skill: Virtual assistant work
High-Signal, Low-Skill: Assembly line work, Retail positions
Low-Signal, High-Skill: Product Management, Managerial Consulting, Medical Professionals, Teachers
High-Signal, High-Skill: Software engineering, Musicians, Athletes
Expertise is a weak signal of Judgemental Forecast quality
Section titled “Expertise is a weak signal of Judgemental Forecast quality”Sometimes judgemental forecasts can seem to be much higher signal than they actually are. Before the explicit research on judgemental forecasting, people highly respected individuals who seemed to be good at it. Psychics, religious predictors, politicians, and political pundits would fall into this category.
Yet, now we know that these were rather weak signals.
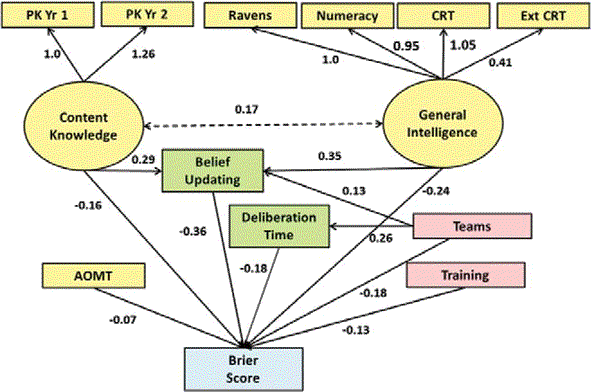
I think the lack of correlation between content knowledge and judgemental forecasting accuracy in particular is still highly unintuitive to most people. In the graph above it’s labeled as explaining a rather small faction of accuracy. The book Expert Political Judgement focussed on what was essentially this topic (though in arguably biasing settings) and similarly came to the conclusion that seeming experts really weren’t that great at doing forecasting.
Say I am trying to get a sense of “What are the chances that the US will go to war with Iran in 2020?” One thing I may first do is to go to the most recognized political scientists and see what they think. A few may have written extensively on this topic, so I think I could easily assume that those are the ones to listen to.
If I were skeptical of them for whatever reason, my first instinct would be to try to read from them and a few other sources, and then make up my own mind.
If a friend disagreed with me, our first instinct to resolve the disagreement may be to spend a long time arguing back and forth on the political details.
Yet, written expertise is a poor signal of judgemental forecasting, so I shouldn’t highly trust the experts when they make predictive claims. I shouldn’t necessarily believe my own intuition that much more, as I don’t have significant evidence that I actually would do well at similar questions. If my friend could destroy me at arguing the details, this should also give me a relatively minor signal.
None of these people (the academic authorities, myself, my friends who are great at debating) would likely have adequate signal to show they are highly-skilled at the specific practice of judgemental forecasting. If I want a great judgemental forecast, I really should go to prediction markets or other teams of proven forecasters.
If I wanted a well-made cake decorated like a pumpkin for Halloween, I wouldn’t try to make it myself, or purchase it from an authority in Halloween history, or get it from a friend who could argue very eloquently on how cake making should be done. I’d go to a professional with clear experience making great custom cakes.
It would seem weird to treat my important judgemental forecasting choices with substantially less evidence than my cake purchasing choices.
Future & Implications
Section titled “Future & Implications”I think we’ve just really just seen the beginning of valuing and integrating judgemental forecasting. The historic brier/log score is arguably a pretty good signal. One great thing about it is that it’s a single metric. I may have to spend some time going through an engineer’s codebase to get a good sense of how good a job they did, but a simple brier score on a set of forecasts would give me most of the useful information on forecast-specific quality.[3]
Above I defined “Low-Signal” as something like “Low-Signal in general, for most people, so far”. With the right theory and metrics, perhaps forecasting can be very high-signal.
I’d also imagine that forecasting may require significantly more forecast-specific knowledge in the future. Prediction markets and prediction tournaments have so far been made for relatively new or casual users. For example, the questions on these platforms are typically binary instead of continuous. As this happens I’d expect this learning curve itself to be a useful signal to filter out the non-dedicated forecasters.
As forecasting setups are crafted for the sake of potential power users, they may include lots of more powerful but complicated abilities. I’m building Foretold along these lines. One thing I’ve realized is that while many people are poorly calibrated with binary probabilities, they seem significantly more awful with arbitrary probability distributions (I started this way!), at least at first. A few people on the site seem to have gotten a fair bit better over time.
Take-Aways
Section titled “Take-Aways”-
- There’s still a lot of interesting things we have to learn about specialized judgemental forecaster teams. It’s not obvious how to best think about this as low-skill or high-skill yet, though it seems like it’s relatively high-skill, especially with teams.
-
- Content knowledge and confidence are mediocre signals of judgemental prediction quality. This means that you shouldn’t highly trust the forecasts of most people who are highly knowledgeable and/or confident.
-
- Related to point (2), just because you are confident in something, doesn’t mean that you should be. Unless you have rigorous knowledge that your forecasting is at the level of teams of superforecaster, you should probably expect superforecasting teams to do quite a bit better than you on questions where you both compete.
-
- Related to point (2), if you have the choice to listen to either academic experts, or teams of superforecasters that listen to academic experts, almost always go with the teams.
Further Reading
Section titled “Further Reading”The Elephant in the Brain describes a lot of useful types of signaling.
The Case Against Education argues that a lot of academic degrees exist primarily for signaling purposes.
AI Impact’s summary of “Evidence of Good Forecasting Practices” is quite good.
Some examples of current expert judgements:
- “
If this were really the case, it could take away
[1] There are technical ways around this if one really tries, so it is possible that they could be “high-signal” with the right work, but we almost never have this work, so in almost all current cases “low-signal” applies.
[2]
I think one reason for this is that the education required for top-level forecasting performance overlaps heavily with things many humans already currently know. The best forecasters generally seemed well studied in technical topics and select worldly information. But it’s not clear exactly what knowledge is most helpful for political forecasting, and it also seems that it’s possible to do poorly even with huge amounts of knowledge. After all, the experts surveyed in Expert Political Judgement arguably knew more about political information than even the superforecasters, but performed worse.
[3] This does leave out information like how useful their comments were. That would have to be dealt with separately.