QURI Priors
Earlier, unpublished writing from the
Quantified Uncertainty Research Institute,
posted as-is — 39 drafts, oldest first.
Pre-AGI Singletons
AI · Dec 2017 · 2,513 words
If all violent conflicts were decided by games of Go, then Google could conquer the world.^1 While we don't live in that world, is not obvious how much harder it would for Google or another single organization to become a world dominant force.
Singletons were discussed in Superintelligence^2 as an end-all state from which the resulting leaders (human and/or machine) would control global future activity. The main argument there is that an AGI (artificial general intelligence) would allow it or its creators the ability to manipulate or overpower other human actors. In the case of a multipolar scenario (multiple actors with similar AGIs), it seems likely that eventually one agent will eventually outmaneuver the others. Once one superintelligence begins to dominate, it seems incredibly difficult for anyone else to stop it.
The idea of AGI seems like a solid proof of a more general singleton argument. If a sufficiently advanced AGI were developed (compared to other actors and to existing technology), a singleton seems quite straightforward. But of course, this doesn’t mean that a singleton won’t happen before an AGI is created. If narrow capabilities are powerful enough, it may be quite possible to create a singleton before AGI creation. We call these “Pre-AGI Singletons.”
So the resulting question is when can we expect a singleton to occur. And to answer this we should probably ask what technology may be necessary to make one.
A singleton-desiring agent doesn’t need to control the entire world right away, they just would have to get started on something with a very likely progression to that outcome. The real goal in an uncertain world isn’t to have immediate power, but instead to have power in high probability in the future. If an agent is on a long-term but inevitable road to this power, then the future of humanity has mostly been decided.
Because of this, we may want to categorize singletons with probabilities. A 20% singleton agent would describe an agent that is estimated to produce a singleton with a 20% probability^3. A singleton-seeking agent would estimate its’ own probability, and do what it thinks to maximize that probability in the future. Given the significant perceived rewards of a singleton, this may be it’s only pre-singleton goal.
The main strategies for increasing an agents’ singleton chances include:
- Increasing their own capabilities. (Capability amplification)
- Decreasing the probabilities of other agents producing singletons first. (Threat reduction)
- Preventing other organizations from stopping actions 1 and 2. (Interference reduction)
If these three goals can be achieved, then an agent’s singleton probability will increase in time. If they can be ensured, than the agent’s singleton probability would be very high.
The Hidden Singleton Motive
The Messianic Secret refers to a motif where Jesus commanded his followers to hide the fact that he considered himself the Messiah. Revealing oneself to think themselves the messiah was a pretty radical act against other authorities, so it would make sense to keep that secret until they could be pretty sure they would be successful.
Likewise, an singleton-intent agent would probably want to hide their intent until their chances were extremely good. Their intent would be a threat to other singleton-intent agents, who would be incentivized to stop them.
A singleton-intent agent not wishing to reveal itself as such would have to limit itself to reveal-limiting actions. Actions that increase its capabilities would have to either justified for other purposes or hidden. It would probably be difficult to completely hide the work needed to become at least a 1%-singleton agent, so it seems more likely that some kind of false front would be needed. The benefits of increasing general capabilities may be generic enough that many fronts would be believable, and even pragmatic without the singleton motive.
Actions that would harm or prevent other actors may be harder to disguise. Anonymous hacking attacks seem preferable, although they may have to be extremely anonymous.
If a singleton-intent agent gets more desperate or certain, it could be expected to do more revealing actions. Their desperation could be caused by either a sense that either other organizations may stop them, or a sense that other organizations may be getting close to making a singleton themselves.
If one were to witness an agent do something that revealed it may be singleton-intent, then this could be evidence that either the agent is very confident in its own likelihood, or that it’s very worried that another singleton-intent agent is very likely to succeed. Either of these cases would be very concerning for an external observer.
It’s not clear what organizations, if any, are singleton-intent at this point. Some explicitly state that they are aiming to create AGIs, but it is not obvious what their strategy would be if they either do or get close enough to make a singleton. As singleton-allowing technologies become more obtainable, more organizations may acquire the goal.
It would seem like singleton-intent agents in many cases would attempt to identify and estimate the chances of other actors either being singleton-intent or eventually becoming singleton-intent, and what their probabilities of success are. Given that each organization would want to adjust it’s perception by others, but care a lot about it’s understanding of others, one may expect an arms race of surveillance, espionage, misinformation, and security.
Types of Singleton-Intent Actors
Global Alliances
If a singleton were inevitable, the least deceptive or antagonistic actor may be a global alliance. Carrick Flynn at the Future of Humanity Institute discussed the idea of an “IGO for Common Good,” a research organization that would act as a cross-collaboration between many nations.^4 This is one of the few actors that may not need to keep its intent a secret. There would have to be a very significant amount of global coordination in order for a global alliance to succeed, given that it would be competing against all other actors.
Governments
Perhaps the most likely actor type to create a singleton is a national government. Governments have very large pools of resources, intelligence on other actors, and expertise keeping projects secret. If a government desires to create a singleton, it would probably want to keep both its desires and its capabilities a secret.
It may be so secretive as to significantly sacrifice recruiting potential in order to appear to have fewer capabilities. To clarify, AI development highly depends on great talent, and one productive way to obtain great talent is with announcements of capability (for instance, writing papers on Alpha Go). However, if an organization is confident in its ability to get top talent without publicity, then it may be reasonable for it to strategically appear naive. This may be the case with some governments, who would have competitive advantages of hiding research and paying extra for it.
Corporations
The main advantages corporations may have over governments are leadership and talent. Many top tech companies are led by founding CEOs who have become very experienced at leading large technical projects, and who have been able to create decision structures with very little bureaucracy. On the talent side, several top tech companies may have comparable or more AI and engineering talent than most governments.
If a corporation were able to establish a singleton, it seems unlikely it would continue to be beholden to shareholders. As shareholder control is only enforced by governments, and a singleton would eventually control of those governments, then the corporation would not have to be accountable to shareholders post-singleton. Perhaps a “corporate singleton” could better be looked at as a sort of coup of executives and select parties within a corporation, rather than considering it to represent corporations as we formally know them. A corporate singleton would be an adversarial goal to most shareholders, so would likely be done in secrecy from them.
Private Organizations
If a small group had enough money, it may be able to hire many researchers with a false front purpose. Right now there are over 2,000 billionaires with total assets of over $7 trillion.[^1]
Setting up a sophisticated AI lab may be achievable to the wealthy. DeepMind, one of the primary AI research facilities, was purchased for £400 million, then has had losses of £54 million in 2015 and £164 million in 2016. Their head count is reported to be only 400; if each cost $500,000 including expenses, that would total $200 million per year. In comparison, Jeff Bezos has been personally spending $1 billion annually on funding Blue Origin[^2].
As an aside, Blue Origin was an interesting example of a secretive technology product. It was kept secret for three years and only discovered because of its’ purchase of a large amount of land in Texas[^3]. An AI lab may not need many resources outside of humans and compute, so may be able to be much more secretive. The creator of an AI lab may also have much greater incentive to keep it private than Jeff Bezos did with Blue Origin. To be specific though, it was secret from the public; it is possible government intelligence was familiar with it.
Rogue Agents
A “rogue agent” is one that doesn’t fit into one of the other categories. These are thought to be smaller or more private organizations funded by individuals or small groups. Rogue agents would be expected to generally have less money than governments or corporations, but there may be many more of them, and they would have the advantage of significantly more secrecy.
A different possibility would be that a very small team without significant funding could simply develop the necessary technology themselves. This team would have to be either incredibly skilled or lucky, or both.
Tactics
A singleton-desiring agent would generally seek a strategy that promises accelerating returns, in order to increase its chances of success. The powerful thing about AI development is that it could be useful to improve almost all tactics for success, many of which could then help efforts to improve AI. The most obvious feedback loop is that between AI and capital. If narrow AIs could be used to gain capital, then that capital could be used to improve and expand on those AIs. Narrow AIs and capital could also be used on threat reduction and interference reduction. This process may be much slower than AI “FOOM” scenarios, but it may be similarly difficult to stop after it reaches a threshold.
Capability amplification
The most obvious way to dramatically improve one's capabilities is by advancing useful narrow AIs. Narrow AIs and infrastructure development that makes it easier to create better narrow AIs and infrastructure development would be broadly useful and may lead to accelerating returns. Otherwise, the goals would be to create narrow AIs that help implement the other tactics.
Income generation
Companies and small groups would likely be constrained by income. In comparison, global alliances and governments may already be funded enough for potential revenues from narrow AIs to not be relevant. For instance, the annual budget of Russia is around $200 billion. It could borrow money if needed.
AI in general is considered to be one of the top, if not the top, most exciting focuses for established and new tech companies. It’s expected to help make a lot of money. This could be from competing in the stock market, producing new media content, being sold as a service for other applications, augmenting robotics, the list is very long.
Perhaps the most difficult aspect of narrow AI income generation is that the largest opportunities will be competitive. A narrow AI working on the stock market would have to significantly outcompete all other AIs doing the same. It may come out that successes there aren’t defensible; perhaps, similar to types of algo-trading algorithms, degrees of intelligence may not matter much after a certain point. Of course, with even a few-month advantage, a large amount of money be be possible to obtain.
-------------------------- The following is more notes for future writing than actual writing ----------------
Threat reduction
Talent poaching
Manipulative coordination
Offensive cyberattacks
Public Revealing
Interference reduction
Plan Secrecy
Computer security
Offensive cyberattacks
Political manipulation -> Terrible attacks
Social manipulation
System breaches
Singleton classification
To help understand the possibilities of singletons, let’s consider a few terms. We can call an antagonistic effort to create a singleton a singleton attack. This is defined as an explicit attempt to prevent counter-attack vectors. Attack vector amplification itself is not an attack, but the effort to prepare one. So for instance, a chemical weapons group could spend years making advanced substances, but it would only be the execution of them that would classify.
Because any attack is uncertain, the specific level of certainty probably matters a lot before the attack happens. Discovered failed attacks would likely come with severe social costs, so trade-offs would have to be weighed before they are executed. Therefore, for attacks that haven’t happened yet, it can be useful to prepend their descriptions with the percentage chance that they are perceived to be successful. For instance, one may wait until they have a “20% singleton attack” before execution. If it becomes possible that other actors may have high-possibility attack vectors, the threshold may go down for other organizations.
An AGI may enable a 100% singleton attack, but if even 0.01% singleton attacks are possible before, they may be attempted.
Attack Vectors
Ending
Singleton Attempt:
Singleton Attack Vectors:
X% Singleton Attack:
What are the likelihoods of singleton-
Pre-AGI attack vectors
There could be many kinds of control vectors.
If machine learning comes out to be essential for a singleton, then this may entail something like:
- Amassing an accelerating amount of compute power and talent.
- Removing compute power and talent from competing organizations.
- Preventing military involvement.
If a group could manage to do those three things, it could be on a pretty good trajectory to becoming a singleton.
[^1]: https://en.wikipedia.org/wiki/The_World's_Billionaires [^2]: https://techcrunch.com/2017/04/06/amazons-jeff-bezos-sells-1b-in-stock-annually-to-fund-space-company-blue-origin/ [^3]: https://www.wsj.com/articles/SB116312683235519444?mod=googlenews_wsj
Comments from Nuño Sempere
Restored with permission (Nuño's comments, with Ozzie's replies).
On “I wrote this document a few months ago. I wrote it to explore ideas, but stopped working on it once I got to some specific details I thought might be…”:
Nuño Sempere: Consider that, if starting from this point you can get to an info-hazard, other people might be able to take the same steps.
Exhaustive Futurism
Futurism · Oct 2018 · 941 words
Question: What should things in this table be called?
Common Dimensions of Historic & Futuristic Analysis
Elements
- Things that will change. Partition?
- Types
- Organizations
- Demographics
- Physical things
- Ideas
- Innovations
- Events
- Element-specific Subdimensions
Time
Relationships/Impacts between elements
Knowledge
- Total amount
- EV of existing / new knowledge
- Subdimensions for specifics of research effort.
Intro Resources:
Similar to:
- https://en.wikipedia.org/wiki/Category:Fields_of_history
Field Names:
- Technology-driven power differentials
- Technology-enabled power grabs
Previous technologies and technology differentials have allowed specific groups to gain power.
- Military technologies / techniques helped the Romans, Mongols, etc. grow substantially.
- The industrial age led to European countries overthrowing and colonizing much of the rest of the world. (guns & steel)
- Nuclear weapons helped the US win WW2 and led to the main power struggles of the cold war.
- The use of Tanks very much changed war from the early WW1 days.
- The use of cannons and similar removed the utility of castles.
Technological Determinism
Exhaustive Futurism
Entities: Actors / Collectives / Ideas / Technologies
For each, estimate
- How much improvement is correlated with EA values
Recommended Frames / Dimensions
- Comparative Differences of Agents (Power)
- Existing State Actors
- US
- China
- Russia
- Saudi Arabia
- Iran
- North Korea
- Specific inter-state actors
- USA
- Parties
- Republicans
- Democrats
- Libertarians
- Government Departments
- Executive
- Legislative
- Judicial
- Surrounding
- Lobbyists
- External influence
- Media’s influence
- Issues
- Polarization
- Climate Change
- Authoritarianism
- General government effectiveness / efficiency
- State Actors by Government
- Democratic Governments
- Dictatorial Governments
- Government Agendas
- Economic
- Left
- Center
- Right
- Social
- Left
- Center
- Right
- Nonstate actors
- Global alliances
- Powerful individuals
- Coorporations
- Startups
- Large coorporations
- Large coorporations with AI emphases
- Terrorist groups
- Media Agencies
- NGOs
- Open Phil / Good Ventures
- Effective Altruists
- DAOs
- Uncontrolled AIs
- Industries
- Academia
- Law
- Health
- Trade
- Groups by Wealth
- Poor
- Middle Class
- Rich
- Ultra-Rich
- Groups by ownership
- Citizens
- Governments
- Generic Lens:
- All tools & strategies for power
- Gender
- Men
- Women
- Transgender
- Age
- Young vs. Middle Age vs. Old
- Religion
- Catholicism
- Protestant Churches
- Islam
- Judaism
- Athiests
- Cults
- Interests
- Risks
- Climate Change
- Nuclear Proliferation
- Biorisks
- Animal Cruelty
- Cause Prioritization
- Blockchain Governance
- General
- Polarization
- Truth & Reporting
- High-integrity media
- Low-integrity media
- Rationality
- Absolute Differences
- Coordination abilities
- General expected stability levels
- Decisive Strategic Advantage
Ways of gaining power
- Technology development
- AI
- Weapons
- Financial
- Stock market
- Coorporations
- Theivery
- Thought crime
- Blackmail
- Hacking
- Social influence
- Political influence
Related research
- There’s lots and lots of military futurism / sci-fi.
- This could meant that work in the area seems unscientific.
- Known organizations?
- US Military Intelligence
- British Intelligence
Existing Frames
- AI and National Security
- Naively wouldn’t focus on power grabs from other groups, which would eventually be an issue of National Security.
- Too much focus on military national attacks.We need to catch groups before they have too much power.
Sources of benefit:
- Identify the main trends to notice for generic decision making
- Many ideas you may not have thought to consider.
- Find what areas may be the most modifiable, change those areas
There’s a conflict between specificity vs. generality
Question: How effective is Open Phil? What areas are they leaving out?
Question: How effective is it to change academic opinion?
What are the ways of changing academic focus / emphasis? / research
https://www.wsj.com/articles/paying-professors-inside-googles-academic-influence-campaign-1499785286
- Think Tanks
- Convince funding
- Convince owners
- Convince researchers
- Academia
- Convince Academics
- Change funding
- Change university emphasis
Dimensions of Historic & Futuristic Analysis
Futurism as a field generally attempts to understand the future, but the future is highly multidimensional. One may ask how futurist research can most effectively cover all potential territory and ensure that there aren't any large areas underexplored. I think one way to begin is with a good ontology.
Ontologies can be used to help map out the space of existing and possible futurist research. On a high level, I think it's useful to begin the ontology by identifying a few distinct axis or dimensions.
Below is one first draft at a dimension outline. I hope it could eventually be improved, but find it useful for now. I wouldn't be too surprised if other organizations have made similar attempts that I don't know about. One thing I noticed when doing this is that creating an ontology for the future is probably very similar to creating one for the past (somewhat obviously in retrospect), though I imagine in practice they may be used differently.
The outline is below. I'll explain the main parts underneath it.
- Time
- Causes of change (Changers) (Elements)
- Recipients of change (Changees) (Elements)
- Change type
- Subdimensions for specifics of elements
- Researcher Knowledge
- Types
- Total amount
- Expected Value
- Existing or expected knowledge
- Subdimensions for specifics of research efforts
- Elements (As changers or changees)
- Types
- Organizations
- Demographics
- Physical things
- Ideas
- Innovations
- Events
- Relationships between Elements
- Element-specific subdimensions
Elements
Elements are things that may either cause effects of be impacted. Basically, anything that could be a noun could be an element. Some specific examples could include:
- China
- Chinese business interests
- The impact of Chinese business interests on stability in Ghana
- Self driving vehicles
- Democracy
- Norwegian woman who enjoy opera
Because there are so many different types of elements, many subdimensions would only apply to a specific selection.
This is probably the simplest dimension. Time is very one-dimensional and easy to understand in the context of history and the future. For example, one could analyze "modern aggriculture per decade from 1800 to 2000."
inputs / outputs.
influencers/ influencees
changers / changees
impactor/ impactee
Decision Value Research Agenda
Forecasting · Systems · Nov 2018 · 2,035 words
Decision Value Technologies Research Agenda
Corresponding Video: https://www.youtube.com/watch?v=X_NvXIFoZG0
Status: In-progress. Seeking feedback on the large details in particular (naming, groups, missing areas, overall utility). Also would be interested in which specific aspects excite people, or if there are references that would be particularly useful for some of this that I probably don’t know of. I may ‘reframe’ the agenda significantly, though I imagine a lot of the overall approach will remain.
Notes: Currently this is an individual project by Ozzie Gooen. It is not apparent how much it will actually be carried out.
Introduction
We can call the total value of information to an agent for its future decision making "Decision Value." Technologies that assist in this aim could thus be called “Decision Value Technologies.” We think that it’s possible and tractable to build software technologies to help optimize decision value. This will require a lot of engineering effort, but also a lot of original theoretical work to properly ground and guide that engineering.
The decision value technologies research agenda seeks to optimize the ability of organizations to optimize decision value, with the larger aim of optimally benefiting future sentient life. The research will focus on principled approaches of combining human intuitions and formal calculations in order to understand how to best use concepts like decision value and expected value.
Agenda Rigidity
Work on decision value should aim to be maximally useful. Constraining research with a rigid scope would likely limit this intention; therefore, any laid out intentions should be considered as a useful framework for research guidance, rather than as an exact plan. The following is considered a best current guess at a plan to optimize decision value on research on decision value, but it is expected to change dramatically to maximize effectiveness.
Key Research Approaches
There already exists a lot of research that has to do with decision making, but we feel like there are some important gaps. Here are a few ideas we intend to focus on that we feel are particularly tractable.
Principled / Probabilistic
We seek to ground our work in Bayesian theory and epistemology. The research will focus on “principled” approaches, in contrast to “pragmatic tools”. This is similar to choosing “neat” research in the neats and scruffies distinction.
Engineering-Oriented
One focus is on the development of software tools to augment humans in using advanced estimation and decision making techniques. Eventually, this may include machine learning, with the goal of advancing the use of narrow but safe intelligence for human intelligence improvement.
Rapid Experimentation
Rather than focus on formal experiments, we seek to engage in lots of individual and technical experimentation. This is in the vein of some Silicon Valley groups and engineering research.
Self-Use
If research goes well, then hopefully it can be recursively applied to improve prioritization for future decision value research. The research effort itself could be a good testbed for ideas that it produces. If research doesn’t go well, it should be canceled.
Research Domains & Methods
On a high level, one can look at research through three important dimensions: domains, methods, and projects.
Research Domains
- Epistemology
- Questions
- If one agent sees a prior of another, how much should that agent update?
- Are there structured approaches for understanding magnitudes of uncertainty and how they propagate in systems?
- This could look like a combination of category theory and Bayesian statistics.
- If we have uncertainty about what calculations to perform, can we use simple models but add uncertainty to the results in a structured manner?
- How can one best handle overconstrained* beliefs?
- Categorization
- This domain seeks to understand how categorization systems can be used to best optimize decision value. This includes issues around ontologies, knowledge management, and practical tools.
- Questions:
- How can one best estimate the decision value of a given ontology to a given agent?
- How can an organization work together to optimize their primary ontologies?
- Can we find patterns or high-level ontologies that agents can use to maximize decision value?
- What web collaboration tools would be most effective to allow groups to build useful ontologies?
- Can ML systems help teach us to make better ontologies or make them for us?
- Estimation
- Estimation really lies at the heart of what is expected to make up decision value research. We're mostly interested in estimation that includes the use of human intuitions combined with calculation. There already exist many mathematical techniques for estimation in the case of certain input, but there is significantly less literature in cases where many of the inputs come from human intuitions.
- Questions
- Overarching: How can a large group of people best estimate a single variable?
- How can an agent best adjust for model uncertainty?
- How can a group of people best share a knowledge base of common priors?
- What are the best probability distributions and techniques for humans to describe their intuitions about important variables?
- How do we probabilistically combine the results of multiple models, especially in cases where they share multiple parameters?
- What are the best ways for probability distributions to be entered and stored in software systems?
- How can forecasting be best used for maximizing decision value?
- Optimization
- Optimization here describes the use of estimation in order to optimize certain variables, the main ones being variants of expected value.
- Questions
- What are good ways of discussing things around expected value and decision value?
- Instead of treating estimation as a constraint optimization problem, perhaps it should be an expected value optimization problem. How should this work best in practice?
- What common patterns can we use to estimate things in ways that will optimize decision value?
- Descriptive Expected Value
- Most attempts at optimizing human utility so far have typically focussed on things that are relatively simple to understand, like income and commuting convenience. However, many people take actions that make it seem like they care a lot about things that are much more difficult to measure. These should be better understood if one would want to better use numbers to help humans. "Descriptive expected value" is meant to attempt to best model agent's actions as optimizations of utility functions, rather than "normative expected value", which more attempts to make decisions using possible utility functions.
- Questions
- Can we better understand human actions in terms similar to expected values, and use this knowledge to better optimize their utility?
- How can we numerically estimate:
- The expected value of important but strange things to humans, like signaling and identity preservation?
- The expected value agents gain from making decisions to be strategically incorrect about things?
- What models of expected value maximization best explain why people and organizations have things that seem like biases and irrationalities?
- Are there ways to model subsystems of the brain, to act as alternatives to treating entire people as "rational agents"?
- Feasibility
- Questions
- How can individuals, organizations, and large networks best adapt practices to better maximize expected value? Where will the incentives correctly align to make this possible?
- Historically, why have tools such as Bayesian analysis, prediction markets, and probability distributions, seen so little adoption in comparison to what one might expect?
- Existentialism: Attempting to optimize for expected value can seem "cold-hearted." How far can humans reasonably go in this dimension, and how can they feel comfortable with it?
Research Methods
- Historic Analysis
- Summaries & Meta-analyses
- Finding, collecting, and documenting existing research most useful for decision value.
- Conceptual Research
- Mathematics and philosophical study would be considered "conceptual research."
- Statistical Analyses
- This encompasses most of the work that could also be called "data science." While statistical analysis could be done in scientific experiments, it could also be very useful to do on existing data.
- Scientific Experiments
- This includes formal scientific experiments.
- Technology Development
- The main aspect here is web application and software application work.
- Direct Applications
- This includes attempting to directly apply decision value research to fields where it would be high in expected value. This can be called "applied" decision value research, as opposed to "theoretical" decision value research. This research agenda is focussed on optimizing theoretical decision value research, so all direct applications would be considered based on how much they would help the theoretical research. There are two main ways this could occur: one, to better test the theoretical ideas in order to improve them, and two, to be used to optimize prioritization and strategy on the theoretical research.
- Advocacy & Training
- The main benefit of decision value research would be from other people, optimizing for global wellbeing. The main groups that would seem to use the research to optimize this are expected to be specific organizations involved in charity and high-leverage global issues.
Research Domain / Method Matrix
Each combination is rated from 0-5 for how much emphasis we expect it to have under this agenda.
| Epistemology | Categorization | Estimation | Optimization | Descriptive Expected Value | Feasibility |
|---|
| History | 1 | 1 | 1 | 2 | 1 | 2 |
| Summaries & Meta-analyses | 1 | 1 | 2 | 1 | 1 | 1 |
| Conceptual Research | 2 | 3 | 4 | 3 | 2 | 1 |
| Statistical Analysis | 0 | 1 | 1 | 1 | 1 | 1 |
| Formal Scientific Experiments | 0 | 1 | 2 | 1 | 1 | 0 |
| Technology Development | 0 | 2 | 5 | 3 | 2 | 1 |
| Direct Applications | 0 | 1 | 3 | 2 | 2 | 2 |
| Advocacy & Training | 1 | 1 | 2 | 2 | 1 | 1 |
Benefits / Costs / Risks
Benefits:
- Improved decision making
- Research would allow people close to it to make better decisions.
- Positive signaling
- Researchers and research users can signal that they have thought about things thoroughly. This could be useful for convincing others if one is confident enough to rigorously test their beliefs.
- Consequentialist encouragement
- Research may encourage users to adopt consequentialist principles
Costs:
- Opportunity costs
- (funding, talent, attention)
- Information hazards
- We could make bad groups more effective
- Risk of negative signaling
- We could make ourselves look bad if we do poor work
- If we do provocative work (rate external groups), it could upset other groups.
- Risks of worsening decision making
- If we do a poor job, we could, on the whole, make groups make worse decisions
- Risk of Negative Founder effects
- We could displace better people who would come along after
Risks to effectiveness (distinct from risks that could make the project net-costly):
- Challenges getting funding
- Intractability
- Perhaps all of this territory is very difficult to make progress on and isn’t worthwhile because of that.
- Ozzie-specific
- Current “bus-factor” of 1.
- Not enough experience for either good work or signaling
- Personal accident or different job opportunity
- Short Timelines
- Other global problems may happen too quickly for research to be useful.
Key Research Influences
Key Academic Influences:
- Management
- Peter Drucker
- Douglas Hubbard
- LEAN
- Bayesian Epistemology
- Forecasting
- Consequentialism / Utilitarianism
- Strategy Research
- Effectiveness Research
- GiveWell / Open Phil’s writings on expected values.
- FHI’s work on Macrostrategy
- Automated/factored reasoning research
- OpenAI & Ought
- Logical Induction
- Cybernetics
- Crowdsourcing
Key Technology Influences:
- Ontology Tools
- Probability Tools
- Forecasting Tools
Explicit Non-Coverage
“Decision Making” Research
- Psychology
- There are large departments aimed at understanding decision making. These are typically focussed on “descriptive” decision making, rather than “normative” decision making. In their descriptive studies, they typically don’t study the specific issue of how human preferences could be best numerically estimated in terms of expected values or similar.
- Business
- There are many popular business-focused books and managerial courses. Most of these study “best practices” for businesses, based on historical information. In contrast, our work is aimed to be more normative, theoretical, and statistically principled.
Data Engineering & Data Science
While software engineering, data engineering, and data science are all useful in decision making, they are also already very well studied, and also don’t optimize decision value in a systematic or explicit way.
Advanced Decision Theory
Logical Fallacies and Cases of Poor Decision Making
Rather than focus on the possible and frequent errors of existing decision making, we mainly seek to understand optimal normative decision making. In some ways, this is a much smaller space.
Online Debate Platforms
Several debate platforms have launched in the last few years. These could be useful, but typically do not focus on probabilities and are not principled in the ways we will focus on.
Concept and Mind-Mapping Software
Mind-mapping software can be quite difficult to make, and also typically does not focus on probabilities and mathematical integrations.
Comments from Nuño Sempere
Restored with permission (Nuño's comments, with Ozzie's replies).
**On “How can one best handle overconstrained* beliefs?”:**
Nuño Sempere: This seems interesting, and is also something I might have thought about before
On “What are the best probability distributions and techniques for humans to describe their intuitions about important variables?”:
Nuño Sempere: Interesting
On “and how can they feel comfortable with it?”:
Nuño Sempere: This seems interesting, but also maybe \not that hard to solve\ by creating better ideologies
Hybrid General Intelligences
AI · Nov 2018 · 4,227 words
Hybrid General Intelligences (HGIs) are agent-acting systems made up of human talent, methods, and narrow AIs, understood with a focus on their collective intellectual capabilities. While it should be obvious that their intelligence is “general”, as that is true for human intelligence, the phrase helps understand these systems in terms similar to Artificial General Intelligences (AGIs). I believe that it’s possible (>5% probability) that HGIs have the potential to recursively self-improve at significant rates (enough that would seriously concern us). While they may not be as impressive as AGIs, they may be more important to consider on a short time-scale.
Definitions & Capabilities
Any organization now would qualify as at least a very basic HGI. Generally, the more easily modeled the organization is as a strategic agent, the better the frame of HGI. This is important insofar that it’s useful to think about HGIs in conversations like, “what are the main agents we should be concerned with, and what are their goals?” If there’s a powerful organization, but it’s much better modeled as a few competing subagents, then the primary reference perhaps should instead be those subagents.
To help put some numbers on intellectual abilities, we may think in units of “Neumanns” or “VNs.” Here, 1 Neumann-year is equivalent to the strategic abilities of John von Neumann for one year. John von Neumann could be a good candidate for this, not just because of his general intellectual ability at topics around mathematical strategy, but for the frequency and magnitude of his work. While he did not do much direct strategy work, I think it’s fair to reason that he could have been at least decent at it if he tried.
Ability to improve strategy is more important than direct strategic ability in the limit of people; if you put 30 Steve Jobs equivalents together, they may be great individually, but may do a poor job scaling their abilities 30 times. Some evidence for this lies in the fact that few organizations have co-CEOs, and no prominent ones have more than 2 people in that position. Even having a COO is considered a risk because of egos and incentives.
This is obviously incredibly speculative, but let’s imagine a table of the strategic capabilities of the following organizations.
| Facebook | 0.1 to 3 | Mark Zuckerberg and Sheryl Sandberg seem highly intelligent. I would imagine they have 3-20 very close strategical confidants. |
|---|
| US Defence Department | 1 to 14 | The US Defence Department is perhaps the largest unified-ish department in the US. The intelligence may be quite distributed on many different operational problems. |
| Chinese Government | 2 to 25 | The Chinese Communist Party is very large, technocratic, and homogeneous. |
| Average VC-backed startup | 0.05 to 0.2 | In many of these situations, the founders do most of the strategic work (in their spare time), perhaps with one or two business advisors. |
| Hedge fund, managing $1B | 0.1 to 1.5 | Hedge funds typically manage $50-300M per employee. This work seems quite scalable, as long as you have the necessary vision / interesting trading strategies. I think the average hedge fund employee may be something like 0.02 to 0.2 Neumanns. |
If such a table is reasonable, here’s one approach to classify HGIs based on their Neumans.
| HGI Ability Level | Neumann Count (Augmented) |
|---|
| Prosaic | 1-20 |
| Weak | 20-100 |
| Strong | 100+ |
The next factor is that of “amplification.” We could imagine that strategic talent combined with very basic levels of methods and tooling would act as a neutral point, with an “amplification” factor of 1. At this point it’s important to distinguish different types of Neumanns. We could imagine “Unaugmented Neumanns” to mean the neumanns an organization would have if it were amplified with a factor of 1x, or pre-amplification. “Augmented Neumanns” means the equivalent Neumman count post-amplification.

This distinction is important for understanding changes in amplification; even with a constant set of inputs (Unaugmented Neumanns), an HGI could output increasing total neumanns.
Understanding HGIs
HGIs are made up of three basic elements: talent, methods, and narrow AIs.
Methods:
The specific methods and business practices used by organizations seem very important. We consider all technology that doesn’t primarily AI-based to be under “methods”. Some examples of techniques that could be useful in a considerable HGI include:
- Forecasting on a sophisticated software platform
- Using powerful knowledge management tools for shared information
- Creating and collaborating on useful ontologies
- Managing lists of expected values and similar for important factors
- Understanding & using Bayesian analysis and probabilistic graphical models
- Correct epistemologies
- An effective culture
- Epistemic humility
- An intense work ethic
- Honesty
- A focus on quality
Talent:
Talent consists of the humans involved in an intelligence effort. Some kinds of talent I imagine would be valuable include:
- Forecasters with different areas of expertise
- Operations support to organize knowledge work
- Innovators of different types to come up with new ideas
- Researchers and research assistants
- Engineers to build relevant software
- Note that internal software is far cheaper to make than external-facing software, so it’s sometimes possible to make surprisingly powerful tools for relatively small efforts.
- Engineers to make AI systems
There is a bit of a fine line between “talent” and “methods”, for instance, would group training count as “improving talent” or “implementing methods”? I don’t think the specifics here matter too much for the general argument.
Narrow AIs:
This covers most use of AIs to augment individual or group decision processes. I’ve separated this from the methods because I suspect it will be a crucial factor for the next 30 years of HGI progress. This is the one area we should expect strong exogenous effects.
The work that Ought is doing seems like one useful way that somewhat narrow AIs could help with general reasoning.
MHGIs (Method-Focussed HGIs)
It seems like there’s more progress to be made with methods and narrow AIs than with talent. I could imagine alternative HGIs focussed either on methods or narrow AIs, so wanted to give them some attention. This means that these HGIs could have significantly more advances in either methods or narrow AIs. For the sake of shortness, I’m going to call Method-focussed HGIs, “MHGIs,” and AI-focussed HGIs, “AHGIs.”
The below diagram represents the abilities of a MHGI; I predict that in order to be powerful it would have to have much better methods than we currently have, and somewhat more advanced narrow AI’s than we currently have. The blue triangle represents the capabilities of a powerful example MHGI, with distance towards the elements proportional in size to ability in that area.
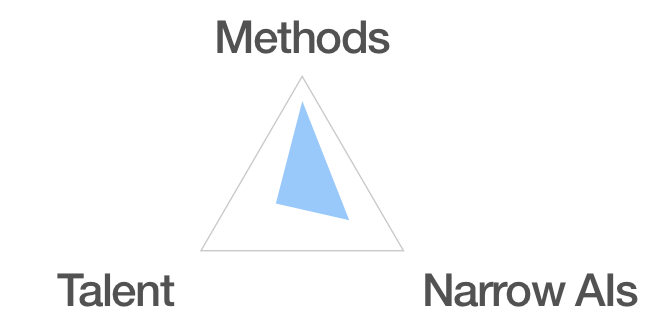
I think that method-focused HGIs could have a lot of potential and may be relatively safe. Strong methods could lead to introspectibility, more similar to principled Bayesian approaches to reasoning than more black-box neural net approaches. However, it may also be less likely.
There’s a story about the hypothetical development of an MHGI on the bottom of post that you may want to skip to if that seems most interesting.
Can methods combined with weak narrow AIs self-improve?
My current thinking is that there are some relatively straightforward (though expensive) ways for a research team to become quite a bit more intelligent & capable. I don’t see any obvious bounds outside of cost and willingness. I would imagine that many of these techniques will be useful for improving the system itself, leading to feedback loops. I would give a >20% chance that most of the value that would come from a well designed $2-million dollar MHGI effort would come from recursive improvement. This is covered a bit in the “story” section.
Little Interest
I don’t know of any external actors who seem interested in and capable of making a method-focused HGI anytime soon. A MHGI may require creators to both be knowledgeable and excited about fundamental decision-making tools such as Bayesian epistemology, probabilistic programming, forecasting, expected value maximization, and perhaps even philosophies like consequentialism. In fact, some of these things have very long histories of seeming to be dramatically overlooked, so perhaps even if groups were to publicly proclaim MHGIs as a possibly powerful tool, very few others would listen. Outside of the Effective Altruism / rationalism communities, I know of no obvious groups who care a lot about more than two of the above-mentioned tools.
Some of the work around DAOs may be related. These are autonomous organizations theoretically managed by clever voting methods and prediction markets. However, I have not seen this work focus on recursive method improvements, and generally do have high expectations of the feasibility of basically all DAO-related projects.
Value-convergence towards consequentialism
If it were true that the creation of a powerful MHGI would require its creators to use principled approaches to decision-making, then it may feature value-convergence, rather than orthogonality. I would expect there to be a strong bias towards consequentialist thinking. It’s hard to me to imagine what a strong system that optimizes without a strong consequentialist utility function would look like, especially for the goals that many actors seem to have. Much of utilitarianism/consequentialism is simply the application of mathematical optimization to high levels of decision making instead of lower levels, so a human-led system of principled decision making may well resemble or converge on somewhat consequentialist beliefs.
A slow takeoff
A MHGI seems like it would have a relatively slow takeoff (~3-20 years). Humans would be doing much of the work and may do many of the most innovative steps.
Alignment problems, but relatively safe ones
A powerful MHGI may be given some sort of utility function, and thus may have similar challenges as have been discussed for AGI with utility functions. However, it would be running on a longer time scale, and humans would be in-the-loop in many situations. I imagine there will be problems with incentives, but think that these could be expected to generally be fixed.
The most important question to ask an MHGI at every stage of its development may be something like, “would it be higher-EV for us to focus next steps on safety or on capacity?” A gradual and intentional ramp up could occur until it was no longer deemed expected to be safe.
Hypothetically this could be a good testing environment for understanding similar issues in AGIs.
Possibly high visibility
It may be possible to bring in talent from a wide and diverse set of experts, perhaps for forecasting or other interventions. Methods may also require a large number of people, and correspondingly a large amount of money. Therefore it’s likely that the program would eventually become quite apparent to outsiders. It may be very difficult to do in secret.
A substantial moat
A MHGI may require a lot of resources and time. Because of the current lack of interest, it seems possible that if there is any major success, it would be difficult for others to quickly catch up. This is especially the case if the methods could be kept secret, though this may be challenging. This monopoly gravitation may mean that groups that develop MHGIs would feel relatively secure, and wouldn’t have to take as many dramatic measures to prevent other MHGIs as may otherwise occur.
AHGIs (AI-Focussed HGIs)
Rather than being method-focused, HGIs may be able to become very powerful mainly with advanced narrow AIs. Unlike MHGIs, I have less certainty about how these could be created or what it would look like. There could be many ways to augment human reasoning ability using narrow AIs, and is not yet obvious which specific approaches will be the most useful.
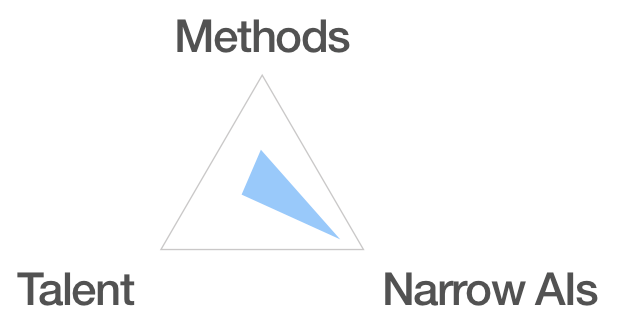
Riding the wave of AI progress
I imagine that AHGIs would focus on developments close to that of public AI progress. How much is somewhat a matter of available budget and innovation. This could make things both “democratic” and unstable. It may be hard to tell what types of AHGIs are possible until new public innovations are announced. Once those do happen, it may not be obvious how much of an edge any single player could have and maintain. If one actor is able to take some recent breakthroughs, innovate on them, and create an AHGI, it may only be a short while until either independent competitors or the public research community catches up.
This lack of a “moat” may encourage AHGIs to take more risky and aggressive strategies, to better ensure their possible rivals will not stop them. On the flip side, they may be able to develop faster (faster takeoffs) than MHGIs, being similar to AGIs. If this is true, while competition could come soon, their additional intelligence may make it relatively easy to prevent competition.
AHGI vs. Intelligence Amplification
The concept of AHGI is really meant to emphasize a system that uses multiple humans, some powerful methods, and narrow AIs, to have powerful strategic capabilities. There are some scenarios where AHGIs could look much like this, but others where they wouldn’t. One could imagine a case where the important strategic actors would look much more like a few very smart individuals with a few really powerful in-house AIs. For these, a better concept may be that of “intelligence amplification”, which is more individual-focussed than group-focussed.
For discussion, we can regard HGIs as requiring at least 2+ people working closely together, in an organization that would be usefully thought of as an agent.
HGIs as Agents
I think one of the key aspects of categorizing an HGI as such is to identify it as having agency. When I imagine a human with “intelligence amplification”, I imagine one person agent with additional AI. But if I imagine “a dedicated team following a written down decision optimization procedure”, then any individual in that team seems less important. The system itself would gain a sort of agency. Of course, parameters could be controlled or decided by a particular human, but on the whole, most decision-making would come from a collective.
One could also think of what I call an HGI as a “*recursively-self-improving strategic organization assisted by A*I”. In this case, one should still focus on the organization more than any individual within it.
If we can consider HGIs as agents, then we may be able to refer to them as “having goals.” So we could say things like, “The HGI will desire X, and seek to use methods A, B, and C, to get X.”
Instrumental Convergence
If we think any kind of HGI could gain more abilities than existing human groups, I think we should consider that their abilities may lead to them acquiring more abilities. If this seems high-EV, I would expect it to be the default action for these groups.
There’s already a lot of “instrumental convergence” between many human actors. Many humans seek status, money, and power, even if they have different goals (Effective Altruists included.) I think this makes sense pragmatically; these things do seem very useful for achieving many sorts of different goals.
Likewise, I would assume that most HGIs would desire goal-content integrity, resource acquisition, cognitive enhancement, technological perfection, and self-preservation (some of the goals stated for AGIs).
HGI Singletons
It seems possible that a powerful HGI may be able to create a singleton in ways similar to an AGI. I’ve written about this a bit before in my similarly-private post on “Pre-AGI singletons.” One potentially nice property of an HGI creating a singleton is that it could provide a safe period to deliberate next steps. A powerful HGI may be safer to create than a powerful AGI. I would imagine HGIs to generally desire to create AGIs (instrumental convergence), but if one were to have a singleton first it could take time and be careful when attempting to create one.
A story of an (M)HGI’s development
A multi-millionaire entrepreneur commits $100 million to build a powerful MHGI. It begins in the highly experimental state, where it’s not at all obvious what it will be useful for in the initial stages. This entrepreneur leads the venture, hiring a team of:
- 10 engineers for web tooling & data collection
- 3 operations staff
- 3 machine learning engineers
- 4 strategy analysts from RAND or similar
- 10 junior researchers (relatively inexpensive but intelligent humanities or technical graduates)
- 1-2 library science specialists or similar for ontology creation
- 1-4 experienced superforecasters or equivalents
- 4 managers to run things
These people would be chosen in part for their willingness to work in a pragmatic and extremely honest way, similar to Bridgewater. I estimate a team of this size would cost between $5-15 million per year.
Phase 1: Initial Infrastructure & Basic Testing
The engineers begin making shared numeric multidimensional knowledge bases for structured data. Tools that can organize structured data, like “what has the GDP been like for every country in every year for the last 30 years?” This would be similar to Google’s Knowledge Vault and Wolfram Research’s backend data infrastructure for Wolfram Mathematica, though it would allow for probability distributions instead of just raw numbers, and be focused more on user input (similar to WikiData). The engineers would then work with the researchers to fill this with important historic data.
Rather than just being about historic data, this tooling would later allow for predictions on future data. The machine learning engineers would use various tools (DataRobot and similar comes to mind) to do lots of trend analysis to predict future probability distributions from this historic data. These would be somewhat wide.
The experience forecasters would help train the researchers to begin making forecasts on the future probability distributions. Those from ML systems would produce distributions with low resolution (though high calibration). There are many areas where these could be narrowed with human judgment. These forecasters will try to narrow many of these distributions.
Initial testing would be done on generic global events that would happen in the near term. Many kinds of things would be tested, for the purposes of better understand what the system could do ok with.
Phase 2: Meta-use
After 4-10 months of setup, researchers will start using the system on itself. They would set a goal, such as “legally maximize profits from this system over 10 years.” People will start work on investigating strategies and using the platform to estimate the success of those strategies. Meta-questions start being formed. Some examples of meta-questions include:
- What is the EV of spending 5 quality-adjusted research hours estimating this variable? (EV based on an evaluation by person X after 3 months)
- What is the EV of adding feature Y to the application?
- What is the EV of researching topic Z to better understand how to estimate EV?
- What are the EVs of every possible action that could be taken to improve this organization?
- Examples include employee habits, culture, practices, hiring, etc.
All the employees would also be rated on several metrics based on their expected and existing EVs to the system. This would be broken down into specific things they do, making it somewhat clear how they can improve.
Eventually, the use of EVs will be replaced with other ways of doing structured reasoning that are expected to be more pragmatic.
If human forecasters can be effectively combined with many small AI systems and used with a secure technical architecture to structure the knowledge, they may be able to be very effective at in total estimating many parameters with degrees of accuracy hard to beat by any single human.
Inefficiencies and poor clarity of incentives and value creation are traditionally major hurdles to productivity. One goal with this is to make sure that employee work incentives are aligned as closely as possible to expected value maximization. The usefulness of their work will be estimated as precisely as feasible, and those estimates will be made known to various people. This setup will probably make some people uncomfortable; therefore the hiring process would be selecting for people who would accept it, and salaries may increase to help compensate for that.
Phase 3: Resource Generation
After 2-25 months of phase 2, the system would determine that some resources would be optimally spent on efforts to gain money. This is done by targeting the financial industry. The comparative advantage of such a system in the financial industry would initially be medium to long-term trades, where historic data and expectations about the global future matter more. A hedge fund is set up to do trades. After 6-24 months, the group makes some significant profits.
Phase 4: Global Influence
The really important aspect of this story is how such a system would rise to power, rather than what it would do with it. There are many ways it could go once it has power, that is for another document.
The system would effectively be following the stabilize-reflect-execute strategy, so the execution should be understood to be difficult to predict.
How should knowledge of HGIs change our decisions?
- We may want to attempt to make a strong HGI for EA purposes. Even if we fail to make something that’s very self-improving, any work in this area could still be useful for our strategic efforts. We would also like to be in a place whereby if strong narrow AIs were to make HGIs far more promising, we could quickly take advantage of that.
- We may want to watch out for others making HGIs and consider risks they would create.
- If we think that HGIs are more much more likely to be important than AGIs, then perhaps we may not have to worry about AGI-specific issues as much.
The skeptical take
There’s definitely an outside-view voice in my head that thinks this is all extremely unlikely. It’s basically ranting something like,
“
Here’s a techy who’s really into rationality, Bayesian reasoning, and forecasting. Of course he’s going to say that those specific things will happen to be the most important things in the world, even though basically every single organization outside of the EA/rationalist community is not at all interested. Probabilistic programming is mostly hype, forecasting has almost never been successfully used within organizations, and expected values sound nice but aren’t actually used by major strategists. Recursive improvement would require not only that these things rationalists love could be done well together (which hasn’t been shown yet), but that they would magically create a hyperintelligence in a way barely even specified.
The whole thing is named “HGI”, like he’s trying to get some quick fame, riding on the popular wave of Superintelligence, even though the proposed entity is really just ‘A smart organization.’
”
I think such views should be taken into consideration. The outside view of much of this work is probably quite pessimistic.
That said, it could of course be the case that even if we are pessimistic, the expected value could still be positive of working on it further.
Primary Open Questions (please leave comments in response)
Much of this document is highly speculative. This work is mainly around trying to find useful frames and hopefully getting feedback.
- Is the above framing (HGIs, MHGIs, AHGIs) a useful one? If it is, could it be improved?
- Should future versions work be public? Are there any specific parts that should not be public? If it should not be public, should it be shared with anyone in particular?
- Should we expect MHGIs to be relatively safe?
- Should we expect MHGIs to both require and encourage consequentialist-leaning beliefs?
- How feasible is recursive self-improvement in MHGI and AHGI systems?
- What does the space of possible HGIs look like?
- What should the expected timelines be for HGIs?
- What kinds of actors do we think may attempt to make HGIs in the future, if any? Will they generally be aligned with EA principles?
- Should EAs try to build MHGIs for our own use? If so, what should the strategies be?
Primitive vs. Weak vs. Strong HGIs
Interesting Links:
https://www.mergersandinquisitions.com/start-hedge-fund-hiring-team-organization/
https://www.winton.com/research/how-big-is-the-hedge-fund-industry
https://alphacution.com/top-hedge-funds-aum-per-employee-trading-strategy/
Understanding Forecasting Systems for EA purposes
Forecasting · Systems · Jul 2019 · 1,690 words
Benefits of Forecasting, in General
- Empirical Accuracy
- Forecasting with a track record can align incentives on accuracy.
- Over time, data will be collected on empirical accuracy, giving a better sense of how much trust to have.
- Aggregation systems could improve group ability. These will get better over time. Currently Foretold uses a very simple aggregation method, but this will be improved.
- Openness
- Having formal forecasts on important questions is a convenient way of providing useful information to a bunch of people, even if the only forecasters are internal.
- Tracking
- Seeing the results of many people could be interesting. Understanding when & why forecasts change can be useful for a better understanding of what is important.
- Calibration Practice
- Calibration abilities often fade (according to direct discussions with Douglas Hubbard), unless they are continuously used. An ongoing forecasting effort could help with this.
Benefits of Remote Forecasters
- Skepticism and calibration
- Experienced forecasters are generally calibrated. If they have enough information to make a good forecast, then they can be expected to be less biased than experts, who are often less well-calibrated. This could be specifically useful in areas where others would be expected to be particularly biased. For instance, the question “When will we complete this project?” is one where bias could be expected, but the question “How many views will the Apple.com website have in 2024” would likely have less (assuming the group is not related to Apple).
- Crowdsourcing research
- Forecasting is a way of outsourcing research work. This is best in situations that don’t require a ton of domain expertise. One advantage of crowdsourcing is that it can be scalable and simple, but one disadvantage is that it could be expensive. One remote forecasting full-time equivalent is probably expected to be less effective than one in-house full-time equivalent because they will have much less context. In some cases, we could bring in forecasters with very specific domain expertise, and that could help in these areas.
- We probably won’t have access to the best remote researchers in the beginning, but can work to get that if it seems particularly useful. It may take some time if we have to pay them significant amounts. The existing Superforecasters were relatively inexpensive but still cost significant amounts.
- Recruiting
- If we attract a bunch of people to help in forecasting efforts, then this could be useful to identify ones that are particularly good or interested in different efforts. This could be useful for identifying future hires or encouraging other smart people to apply for positions.
Costs of Forecasting
- Question ideation & discussion
- Coming up with specific questions that external forecasters can understand is surprisingly difficult. Once you make one version, you may get pushback or further questions from forecasters. For example, if you ask “What are the chances that nuclear war will happen by 2025?”, you may get flooded by a series of questions on which specific types of nuclear weapons would count as being part of a nuclear war.One issue here is that most people are used to relatively vague terminology, but once things are pinned down to a specific question, users demand much more specific terminology. This could be a surprise for many people. That said, one benefit is that it could force you to recognize vagueness and make other discussions more clear.
- External forecasters may have many domain-specific questions for their forecasting efforts. If the question writers are responsive, this could be highly valuable, but this also presents a significant distraction.
- Resolving questions
- Questions can be difficult to resolve. If the question isn’t already clearly posted on a website, the answer may require a significant amount of research and/or evaluation.
- If questions are to be resolved in the far-future, then the question itself presents a type of debt that one should prepare to pay off in many years. This could be difficult to track and ensure that the resources will exist to adequately resolve it. In some worst cases, it’s possible an organization could take on a significant amount of “resolution debt” before it has experience understanding the cost, and get left with a surprisingly high amount of work without adequate resources to deliver. That said, this could, of course, be mitigated with forecasting on these costs and capabilities.
- Information Liabilities
- Forecasting important questions often create informational openness that may be unusual to many groups. For instance, the accurate answer to the question “Will our project run over schedule?” is typically one highly guarded by a few managers, but in forecasting systems is exposed more broadly. I believe this is one main reason why forecasting systems are currently used by very few groups.Forecasting can be seen as a very transparent tool, similar in style to organizational practices at Bridgewater. Some people really dislike these kinds of practices.
Possible Best-Practices for Question Organization
- Focus on highly similar & structured questions.
- Defining questions, debating the specifics, and resolving them can take a significant amount of time. The more similar different questions are, the cheaper they will be for all involved. For example, instead of having a custom success metric for each nonprofit, if there were one universal, but slightly worse metric, it could be a good first-pass. This also helps with organization; keeping a high-level overview in your head of 100 different questions could be very hard, but if they are all specific variations of each other it is much easier.
- Keep things nonsensitive
- Questions that must be private or questions that would raise controversy or hurt feelings can be liabilities.
- Security
- While the chances shouldn’t be high, there is always a chance that someone’s account could be breached or similar, so data will never be 100% secure.
- Controversy / Pain
- There are some questions that would anger specific people or groups. For example, the question, “How likely is Startup X to fail in 2 years” could put the founders of Startup X on edge. In some of these cases, there are very similar questions that could get around these issues.
- Privacy
- When in doubt, questions like this could be private.
- You could even use pseudonyms for specific names, to be extra careful. We may eventually add some extra tooling to make this painless.
- Generality
- “How many of these 50 YC startups will fail in 2 years?” is likely to be protested less.
- Grade on curves
- Rather than ask, “How much value will organization X create?”, you can make a rubric for organizations which maps their value to a score of A-F or similar, with most groups getting a C or better. Even if the mapping is clearly stated, it’s very easy to make this less visible and have people worry less.
- Focus on the best items
- Many awards only give awards to the very best participants. Similarly, you could forecast things like, “how likely is this group to be in the top 3 of the rankings”?, or just reveal the top few results.
- Questions should be interesting to other groups and to forecasters
- Forecasting can be expensive. If the results of these forecasts are useful to more people, that’s generally more efficient. Likewise, if you can come up with questions that would be useful to multiple EA organizations or similar, those would be particularly interesting.
- Forecasters find some questions more interesting than others. While I don’t have a great model here at the moment for the specifics, I think you can imagine what kinds of things they may prefer to work on. Especially for volunteers, this could matter a lot.
Possible Groups of Forecasters
- EA-related volunteers / part-time consultants
- There are a few handfuls of EAs who have expressed interested in volunteer work, some would be willing to spend more time if paid. A few of these are experienced/well ranked on Metaculus or The Good Judgement Project.
- College Groups
- One particularly interesting type of volunteers could be those in college groups. It could eventually be interesting to have competitions between different colleges for forecasting value.
- Full-time forecasters
- We may eventually hire some forecasters to spend 20+ hours per week on forecasting. Here it would be more of a job than a hobby. This could get expensive but could be very reliable. These forecasters would likely be remote.
- Organizational employees
- Individuals inside an organization can be used to make forecasts. This is good for short things in areas they are well knowledgeable on. It can also be useful to help the organization become better calibrated. However, it’s probably unlikely that participants will spend a whole lot of time on forecasting unless it is seen as official work or is strongly integrated into the culture.
- External EA experts/employees
- It could be useful for various individuals at different organizations to directly participate in shared forecasting efforts. This could be particularly beneficial in order to better understand what a diverse set of community members thinks on various issues. It may also be good if some individuals have specific but highly applicable expertise.
Useful Tools for Forecasting
- A domain-specific dictionary.
- Lots of terminologies may be similar between questions, but be vague. It can be good to have a defined list of terminology somewhere for repeat use.
- You can see one example of this at the AI Dictionary.
- A “resolution counsel”
- There could be some questions that require judgements by individuals. For instance, “In 2025, on a scale from 1-10, how good of a job did the new CEA do?”, or even specific questions that may still have some hidden assumptions like, “In 2022, will project X have been started?”. In these cases, it can be useful to specify who is responsible for answering the questions. The less the questions are, the more important that a robust and respected counsel is established.
- The Parallel Forecast team is currently putting together a resolution counsel for AI purposes.
- A “knowledge graph”
- As terms are defined, it may be useful to establish a significant knowledge graph of information, similar to that in Wikidata. Foretold currently has a little support for this, but will have more, later.
Considerations for Time-Scoring
Forecasting · Methods · Sep 2019 · 634 words
“Time-scoring” is the simplest phrase for discussion around how to score forecasts for questions that last some time. This corresponds to the “Agent-Question” scoring layer.
First, I want to lay out a few different clusters of situations where people/researchers may care about scores. I think that there are many kinds of scenarios that are likely to work best with different scoring systems. Identifying the main distinctions that require different scoring systems seems useful.
Scenarios:
1. Iterated vs. single-shot
Iterated scenarios are those where users will make updates to their forecasts based on either new information, new forecasts, or more thought. In these situations, users will be expected to gain information over time.
Single-shot scenarios are those where users make single predictions with or without discussions by others. These predictions are made without seeing each other’s predictions.
2. 1-person, small group, very large group.
1-person scenarios are those where only one person makes forecasts. In these cases, there may be no market for them to compare against (unless we have an AI that’s decent).
Very large groups would should have some amount of competition on all questions at roughly all times.
Small groups are in-between and can be hard to predict. There can be some questions where only 1 person makes predictions, and others where lots of people make predictions. Markets may be relatively inefficient for long periods of time.
3. Multiple timescales: 1min, 3 hours, 1 year, 30 years
4. Things we may be able to trust:
- The market will be relatively efficient.
- The question writers will be not be corrupted to favor specific participants.
- Goodwill; players generally want the project to go well.
5. Multiple question quantities:
1-5 questions (Key important indicators)
5-20 questions (A cluster of important questions)
20-400 questions, scattered
- User Skill
- Amatures vs. Experienced users
- Many “good” users vs. a few “expert” users.l
Cases to handle well:
- People shouldn’t be incentivized to wait until the end to predict.
- People shouldn’t be required to keep on forecasting (with the same exact value), once they make one forecast.
- People shouldn’t be incentivized to make many of the same, or near-the-same forecasts.
- People shouldn’t be disincentivized from contributing useful forecasts, from their expected perspective.
- People should be incentivized to share information that would be useful for others
- Making a contribution which strictly improves the aggregate at the point it was made should not give negative points (unless at a later time it makes the aggregate worse)
- Making generally useful predictions should generally result in positive scores.
- The score should be combinable with other factors (such as when clients will read the predictions).
- If 2-4 people provide a lot of value predicting, with no one else predicting that sum total should get positive points.
- Users shouldn’t be incentivized to track the aggregate too much.
- Actually, there could be clever ways of doing this where it’s not very computationally expensive.
- Users shouldn’t be able to copy the inputs of a respected user and get free points.
- If the aggregate exactly matches one really good player, that player should still get EV.
- Users should be incentivised to become more trusted by the system.
- For example, currently, the better your past performance, the more you influence the aggregate. But the more you influence the aggregate, the closer your predictions will be to the aggregate, and as a result you will get fewer points. This creates an incentive for not revealing how good you actually are, e.g. by using different accounts
Assumptions:
Certainty will increase in time.
Models:
- Continuous forecast, then take the integral/average
Ozzie-Forecasting High-Level Thoughts
Forecasting · Systems · Oct 2019 · 3,218 words
Ozzie’s Forecasting High-Level Thoughts
Useful work:
Foretold: foretold.io/login
Foretold inputs: https://observablehq.com/@oagr/foretold-inputs
Introduction
I’ve spent a fair bit of time in the last few years (especially the last one) trying to make sense of the forecasting space and how it can be best applied for EA purposes. I’m currently working on an application to help with forecasting.
At this point I have a bunch of models and opinions on the topic. There’s no one linear thread; rather there’s a long list of things that follow a few clusters.
My current plan is to spend a few more evenings on this document, then share it to several relevant parties for feedback, to later be posted to the EA forum or similar. Feedback at any stage is highly appreciated.
This document uses lots of simple examples and does not have many citations. It is not meant to be as formal as a proper book or paper, but rather as a time-effective method for me to share a lot of concepts. My primary project at the moment is in making and advancing Foretold, which I believe to generally be more time-effective for me.
Previous Material
My LessWrong series on “Prediction-Driven Collaborative Reasoning Systems” has a few posts on my thoughts on how advanced predictions could work.
I had a double-crux with Vaniver in July 2019 about related issues, a transcript of which was posted to LessWrong.
Part 1: High-level Ideas & Patterns
Pattern: “If you have a hammer...” / Strategic Advantages
From Wikipedia:As Abraham Maslow said in 1966, "I suppose it is tempting, if the only tool you have is a hammer, to treat everything as if it were a nail."[[2]](https://en.wikipedia.org/wiki/Law_of_the_instrument#cite_note-maslow66-3)
The “Law of the hammer” is generally considered specific to a cognitive bias, but if it can also be altered for responsible individuals to be a useful pattern. There are cases where you may find a few uniquely great tools; in these cases, it could make a lot of sense to pay a lot of attention to ways you can modify all types of problems into version that could fit your tools.
Example: AI Pathfinding
Humans normally do pathfinding intuitively. We can quickly imagine what a good path for an entity would be from a glance at a diagram. AIs (especially pre-NN) generally don’t have this ability. However, they are very good at simple calculation. This has been used to solve pathfinding problems in ways that never would have come up as possibilities to humans. Instead of intuiting good answers, AIs could first make a simple list of every possible option, and then try simulating each one.
Example: Digital vs. Analog Electronics
Say you want to make an electronic controller for opening a chicken coup when the sun comes up. You could design an elegant solution with analog electronics; this would involve doing math for resistors and capacitors to make it operate as you’d expect.
Alternatively, you could write a small digital program with a microcontroller. This may seem wasteful; the microcontroller has far more complexity and circuit components in it than any reasonable analogue solution. However, you know microcontrollers really well, and because there are so many they’ve gotten quite cheap.
Rather than use “many custom setups” for different problems, you eventually realize that microcontrollers are almost always simpler overall, and overtime stop using analogue components almost all-together.
This is basically what has happened in industry.
Example: Functional Programming
Functional programming techniques are very elegant and powerful for pure code, but much less so for non-pure code. Therefore, a lot of work is done to isolate non-pure functionality from pure-functionality, and then optimize each separately. After this is done the pure code can often be significantly optimized.
Relevance for Forecasting:
If we get really good at forecasting and related methods, we may be able to get creative at using them for areas that we normally wouldn’t think of right now. We would also want to strongly distinguish questions where forecasting would be helpful from those where it won’t be, so we can be sure to handle the former accordingly. These are general tools and with some work we may be able to get a whole lot of our current problems to fit into their required shapes.
This is not to say that there aren’t many currently-obvious uses of forecasting, but rather that in the future there may be many more obvious uses.
“Generalist” Research
There is a spectrum in how accessible research is for nonspecialists. Here I call research that is accessible to generally smart people “generalist” research, which is different from “specialist” research. “Generalist” refers to domains (bio, physics, etc), rather than methods (statistical analysis, literature review, etc).
Example: Data Science
Data science is one example. Many “data scientists” get good at “data science”; a set of methods, different from a specific domain to apply them. There are large areas of work where any competent data scientist would be useful, but of course there are other areas where you would need a data scientist deeply trained in a specific topic. The work where any competent data scientist would be useful would be considered “generalist”, while the other would be considered “specialist.”
Example: Open Philanthropy Project
Many of the main staff at the Open Philanthropy Project have done cause analyses for many different areas. They are often quite new to the areas they are investigating. Despite that, they seem to have done a competent job at doing prioritization in very different areas. The Open Philanthropy Project has developed a network of specialists to get advice from, and later did hire some domain experts for specific areas. However, it was generalist competence that led to doing these steps.
Example: Many Entrepreneurs
Many of the most successful entrepreneurs were relatively new to their future field. Their comparative advantage is generally in entrepreneurial activities, rather than the specific domains they wind up applying those to. Some examples would include Uber, AirBnB, Dropbox, Stripe, Twitch, SpaceX, Tesla, etc.
Claim: Generalist Research is very important and large.
Much of prioritization would fall under generalist research. I believe that people could prioritize things significantly better, that would both be directly useful, and would also speed up the valuable research.
Many of the main EA problems I can think of strike me as rather general; namely, the strategy and prioritization for many important fields. Right now I get the impression that there’s a ton of useful prioritization and strategy work to be done in EA areas.
Relevance for Forecasting:
I think that superforecasters and other smart forecasting communities can do an obviously good job at some important aspects of generalist research. It’s not yet as obvious how useful new forecasting tools can be for specialist research, but even if it were only useful for generalist research, that could be great if we think there is a lot of useful generalist research to be done.
Systematic vs. Nonsystematic Thinking
(Maybe “Formal” vs. “Informal” thinking?)
I want to highlight a gradient of reasoning methods.
Relatively Systematic Methods:
- Formal mathematics
- Formal ontologies & taxonomies
- Explicit decision calculations
- Tables of data and estimates
Relatively Nonsystematic Methods:
- Loose group brainstorming
- Most blog posts, essays, and popular books (non-textbooks)
Reflection:
Nonsystematic methods are good for small groups with high trust and without a very large amount of time. However, as group size and research time expands, then systematic methods provide higher scalability (or surface area.)
As our research endeavors expand, I expect we should get better and focus more on systematic methods.
Innovation: Research vs. Development / Horizontal vs. Vertical Efforts
Research and development are more of a spectrum than two binary options, but it’s an important spectrum.
There are times in some R&D efforts where research is the primary bottleneck, and other times where development is the primary bottleneck. Sometimes research is needed for development, but sometimes development is needed for research.
Pro-Development Example: Microprocessors
The introduction and advancement of microprocessors has led to highly significant advances in other areas. Hypothetically, it would have been possible for the original staff of Intel to have instead decided to do more research into computation. They could have written extensive reports on interesting developments that computers would allow, or performed experiments to see how useful simple computers were in different situations.
Thankfully they didn’t focus on these tasks. By spending a great deal of time and money improving microprocessors, Intel enabled many other research & development groups to make significant advances in many domains. At the time, advancing development seems like a much larger bottleneck for the innovation process than more traditional research would have been.
An alternative frame: Horizontal vs. Vertical Efforts
Horizontal efforts describe identifying new techniques and principles around forecasting. Vertical efforts describe creating an end-to-end value chain of forecasting efforts and iterating on it. Vertical efforts are similar to an “Agile” focus on doing a simple job at all parts of an effort up to user engagement, while keeping the breadth of functionality more limited.
Horizontal efforts are obviously a bottleneck if there is no viable vertical effort.
Generally, research institutions focus on horizontal efforts, but startups allocate most resources on vertical efforts.
Relevance for Forecasting:
It’s not obvious if the most useful path in forecasting work is in research or development. Similarly, it’s not obvious if the most useful path is in horizontal or vertical efforts.
I personally think that vertical efforts are quite possible, and also that if they are possible they present the largest bottleneck. The corresponding strategy would look something like making a forecasting system that provides an initially-small amount of value to EA purposes, and then spending a lot of time scaling it up.
Others close to this work disagree. Existing efforts to make predictions for EA purposes have not gone very well and may not be exciting to scale. This is a dilemma we’ll be keeping track of.
Part 2: Understanding Human vs. AI Forecasting
Judgemental Forecasting vs. Statistical Forecasting
There are several ways to divide forecasting methods. One distinction I like is to consider “statistical vs. judgemental” techniques, where “statistical” techniques include AI methods.
When Effective Altruists talk about “forecasting”, they often refer primarily to judgemental techniques. Superforecasting was mostly about judgemental methods, for instance. Yet judgemental techniques represent a small minority of the forecasting literature. One could arguably include most of data science and AI into “forecasting.”
This doesn’t mean that we should ignore judgemental methods, but rather, that we really shouldn’t ignore non judgemental methods, especially when considering the future.
I think that AI represents the most exciting advancements in data science, so will reframe this distinction to “human forecasting vs. AI forecasting”, which I believe will approximate the distinction of “statistical vs. judgemental” techniques over time.
Human forecasting is general & weak. AI forecasting is narrow & strong.
Humans can use intuitions to forecast on a very wide variety of general questions. By this I mean that humans can forecast to some degree of accuracy on almost any question they could understand. AIs typically use significant data sources to get quite good (typically better than humans, where applicable) at narrow/specific questions.
General vs. narrow forecasting is very equivalent to general vs. narrow intelligences; regarding AI. Forecasting in general is probably AGI-complete, so we can expect humans to be better at at least some questions until AGI.
Therefore, for a long time, we should expect human forecasting to be important relative to AI forecasting. But in general, where we have the option to use AI instead of judgemental techniques, we should go with AI.
Human forecasting is slowly getting better. AI forecasting is quickly getting better.
The Superforecasting studies took several years and were perhaps the most notable advance in judgemental techniques in the last 10 years. The results are interesting, but still not fantastic. There are only around 125 active superforecasters working part time for relatively expensive amounts for around 10 clients. If others took the lessons from these studies, I could imagine human forecasters improving accuracy rates by around 10%. There aren’t many studies going on now that seem to improve accuracy or effectiveness further.
Meanwhile, AI development has a very large industry behind it and major advances are happening every year, which are often entering use in industry shortly after.
I’m quite sure that superforecasters forecasted the economic efficiency (dollars generated via predictions per dollar spent) from AI forecasting vs. judgemental forecasting per year, AI forecasting would be forecasted to do dramatically better.
AI forecasting & human forecasting work well together in financial systems
Warren Buffett is a great example of a “judgemental” value investor. He decides if companies are overvalued or undervalued based on principled analyses of their fundamentals. He does not make most of his decisions primarily using advanced AI tools.
Jane Street is a strong alternative example. Over the last 20 years, I imagine many people would agree that computer systems have become much more effective at stock trading. I imagine they would also agree that humans haven’t become similarly that much better at stock trading.
However, value investors still exist (and occasionally flourish) in the market with algorithmic traders. For now both seem quite important.
Important forecasting questions are very similar to financially-traded questions
Consider the following two sets of questions. Which do you think would be more amenable for combining lots of AI systems and human judgement?
Question Set #1:
- The GDP of Russia in 2030
- The GDP of the United States in 2030, conditional on a Democratic candidate being elected in 2024
- The total number of AI papers published in 2025
- The average global temperature in 2030
Question Set #2:
- The time-discounted expected value of Apple over the distant future.
- The time-discounted expected value of JPMorgan Chase & Co. over the distant future.
I think without prior knowledge, it shouldn’t be obvious what question set #2 has any strong net advantages over question set #1.
Question set #1 contains questions we may want to forecast for general use. Currently these questions are typically forecasted in relatively judgemental methods, and done with very little automation.
Meanwhile question set #2 currently has tons of advanced automation, AI, and collaboration.
The only real difference that I can tell is that question set #2 happens to have a very significant market available, with a lot of money at stake, and question set #1 does not have anything like that. Because we know that advanced methods are used successfully for question set #2, I think we can assume that they could become a large part of solving questions in question set #1, and that this may be needed for us to do a similarly good job with the questions in question set #1.
Part 3: Misconceptions on Forecasting
Misconception: Many things are impossible to predict
Saying that some things are “impossible” to predict treats prediction as a binary ability. It’s instead a gradient called predictability. “Impossible” vs. “possible” is the wrong type signature.
There’s no generic “time threshold”, after which we cannot predict things. Different types of things have very different predictability. The weather isn’t very predictable 3 weeks out. Global population is relatively predictable 5 to 10 years out. Interplanetary orbits are predictable 10,000 years out.
Predictability is a predictable thing. Forecasters can forecast the certainty we can get on different variables conditional on us spending resources to forecast them. With sufficient forecasting work, we could make elegant tables of what kinds of things are the most effective to forecast.
On “Predictability”
I’m using predictability as a fuzzy term. I’d like to provide a clearer definition / split later on.
Misconception: The Good Judgement Project has shown we can’t predict things after 2 years
The Good Judgement Project has found that geopolitical events they have studied seem to be “somewhat predictable up to two years out but much more difficult to predict five, ten, twenty years out.”[AI Impacts].
It’s clear that the kinds of questions asked by the GJP are not very predictable 2+ years out. It’s not clear how well this applies to other questions. Obviously many things 2+ years out are predictable, like population sizes.
There was likely some selection effect of questions. They have historically posed “interesting” questions that seemed significantly uncertain and difficult.
Second, my impression is that GJPs claims were about resolution; not calibration. The forecasters should generally be well calibrated, it’s just that their resolution is very low on many political events. This is fine and can itself be very useful. As Philip Tetlock mentioned in Expert Political Judgement, many “experts”, “popular figures” and “government figures” commonly make very long-term political forecasts with rather poor calibration. Superforecasters have poor resolution on specific long-term questions, but probably not less so than other people, and their calibration should be much better. Listening to superforecasters on long-term political issues, and also on long-term other issues, seems more useful than listening to any other apparent group.
Misconception: Most future value from forecasting will definitely come from forecasters internal to organizations & projects
Prediction market software has been available for internal company and government use for many years, but adoption has been very small. For example, Google has tried them but for a few projects around 2008, and use has mostly halted. Even after the Good Judgement Project’s work on superforecasting, there are no related large government forecasting projects.
Some may see this as a large amount of evidence that forecasting methods will never be useful for governments and companies.
I’ll begin a counter-argument by clarifying that “forecasting” is a very broad term; the specific thing that is being discussed is typically “internal prediction markets” or “formal internal prediction registries for judgemental forecasts.” Governments and corporations generally use judgemental forecasts very commonly (executive decisions, for instance), and employ many data scientists and similar for statistical forecasts.
Many things that businesses care about are similar between businesses. For instance, many businesses purchase data sets and information sources from third-party providers.
Some questions:
- How much money is spent by businesses on internal vs. external analysis?
- How much value do businesses get by internal vs. external analysis?
[Incomplete]
Forecasts vs. Estimates
Claim: Forecasts are a subset of Estimates
Claim: Almost all estimates can be reframed as forecasts, which would come with benefits and negatives.
Claim:
Almost all estimates can be turned into forecasts.
Forecasts are more expensive but more powerful than estimations
Forecasting Terminology
Forecasting · Methods · Nov 2019 · 1,101 words
Quantitative Epistemology Optimization
Definition: The use of math, science, and technology to reduce uncertainty on general questions in ways that create decision value. General questions are defined as questions that include both simple quantitative questions (“Given these parameters, calculate the mean”), and questions that require significant human judgement (“Based on this complex historical evidence, how many people lived in historic Rome?”). In particular, Quantitative Epistemic Optimization refers to a cluster of techniques that can be used together to help with these issues.
Alternatives:
- Epistemic Engineering
- Quantitative Epistemology
- Epistemic Optimization
Confidence: 2/5
Decision Information Value (Decision Value for short)
The value that comes from information insofar as that information helps your decision making. Similar to “Value of Information”, except:
- It’s not the “value of perfect information”
- It’s not specific to one decision, but the expectation for all future decisions.
Confidence: 2/5
Epistemic Pain:
Economic personal or organizational losses that come from improvement in beliefs.
Confidence: 1/5
Alternatives: Epistemic Loss, Epistemic Sacrifice
Examples:
“After careful analysis, we realize that you have been a terrible parent.”
“It turns out that our business has been dramatically harming the environment”
“Our project is likely to fail”
“I’ve come to believe in Islam, although my family is Christian, and would dissown me if they knew. I could keep it a secret, but doing so is costly.”
Deliberation
The act of an agent doing work (thinking or gathering information) in order to reduce uncertainty on a set of questions.
Confidence: 4/5
Debate
Alternatives: Reconciliation, Discussion, Back and forth
Multiple agents with different estimates discussing things / sharing information, with the goal of reducing uncertainties.
Confidence: 2/5
Note: Gah, I don’t like this.Value vs. accuracy is important for a different distinction.
Prediction-Information-Gain vs. Prediction-Accuracy
Prediction information gain refers to the information gain or that comes from information. Prediction-Accuracy refers to how well that prediction reflected its corresponding answer. It’s possible that these could be not perfectly correlated; for instance, agent A may have poor accuracy, but is highly valuable because their predictions help an aggregate. There can be multiple measures of value and accuracy.
Confidence: ⅗
Other words: Instead of information gain: accuracy gain, benefit, assist, bonus,
One interesting tidbit here: If you actually believe something, you don’t need a proper scoring rule as your loss function. You’re not going to lie to yourself.
Expected Estimation Loss
Alternatives: Expected Error Loss, Expected Loss, Expected Score, Expected Certainty, or we just abandon this.
An alternative name for entropy, when done via a prediction and when using log error. Units may be the same as entropy. The reasoning for this is that entropy is used all over the place, and typically refers to other situations. The phrase “I’m trying to minimize the expected loss of this forecast” seems more intuitive to me than “I’m trying to minimize the entropy of this forecast”. My guess is that “entropy” would cause more confusion.
Confidence: ⅖
Note: If you are estimating a distribution, things get tricky here. You can’t take the differential entropy.
Estimation Loss:The actual loss, after the result is known. There are many ways to calculate error.
Alternatives: Ex-post error/loss (compared to ex-ante), Post-evidence error, post-improvement error
Estimation
An estimation is an attempt of a quantification on a specific parameter. In most cases estimations are uncertain, though in the limit they could have no uncertainty.
Prediction
Predictions are estimates that attempt to estimate the results of a verification procedure. Most estimates can be arbitrarily turned into simple predictions, if one is flexible enough with the verification procedure.
Verification
A verification is an estimate of a parameter after the acquisition of evidence. One prediction’s verification could itself be a prediction for a further verification.
Predictions vs. Verifications share a similar relationship as Priors vs. Posteriors; they are a similar shape, but separated by the presence and update of evidence.
Evidence
Information that helps reduce uncertainty on a set of variables. Predictability could be defined pre-evidence and post-evidence for any set of evidence.
Discovery
The release of evidence. This is often a gradual process.
This is similar to discovery in law), which is a specific period where evidence is gathered.
Evaluation
Verifications that require judgemental analysis of information, rather than directly taking a specific statistic or fact.
Estimation / Prediction / Verification Curves
Graphs of expectations of work done vs. expected information accuracy or value. Most of the time there are diminishing returns.
Alternative names: Estimability / Predictivity / Verifiability Curves.
Estimation / Prediction / Verification Limits
The limits of expected information accuracy or value with arbitrarily large resources. “Arbitrarily large” could be defined differently depending on the circumstances; there are some situations that could expend far more resources than others.
Estimation / Prediction / Verification Potential
The remaining potential to improve, from the current point to the limit. Can be specified in percentage of the original, which may be a bit useful.
Work & Effectiveness
Estimation / Prediction / Verification / Evaluation Work
Costs imposed to do better at estimation/prediction/verification.
Note: There should be some way of specifying the cost-effectiveness of these kinds of work, vs. the returns by having them.
Frontier? Efficiency?
Accuracy vs. Value
(Estimation | Prediction | Verification | Evaluation) Work (Accuracy | Value) Effectiveness
The marginal accuracy or value gain of a specific intervention, divided by its’ cost. Either counterfactual or using Shapley values.
(Estimation | Prediction | Verification | Evaluation) Work Accuracy | Value) Frontier
The set of projects that would maximize expected effectiveness
Tractability?
This seems useful, but I’m not sure what on the curves it should refer to.
Prediction Setup
Alternatives: System, Engine*, Machine, Complex, Compound, Network, Procedure, Scheme, Design, Faction, Party, Body, Agency, Company, Body, Rig, Outfit, Unit, Ensemble, Faction, Partnership, Coalition, Vehicle, Setup, Coalition, Market
Note: Greg Lewis was in-favor of engine*.
Prediction System Appraisal
Alternates: Attestation, Pinning, Assessment,
https://nlp.stanford.edu/IR-book/html/htmledition/an-appraisal-of-probabilistic-models-1.html
Probability
Perspective
The probability of X from agent Y’s perspective, given information Z, is the posterior of Y after doing a bayesian update on Z, using Y’s prior.
Ontology
Predictability
Relevant wikipedia pages:
https://en.wikipedia.org/wiki/Entropy_estimation
https://en.wikipedia.org/wiki/Nat_(unit))
https://en.wikipedia.org/wiki/Information_content
https://en.wikipedia.org/wiki/Estimator
https://en.wikipedia.org/wiki/Kullback%E2%80%93Leibler_divergence
https://en.wikipedia.org/wiki/Differential_entropy
https://en.wikipedia.org/wiki/Perplexity
https://en.wikipedia.org/wiki/Qualitative_variation
https://en.wikipedia.org/wiki/Level_of_measurement
https://en.wikipedia.org/wiki/R%C3%A9nyi_entropy
https://en.wikipedia.org/wiki/Standard_error
Comments from Nuño Sempere
Restored with permission (Nuño's comments, with Ozzie's replies).
On “Quantitative Epistemology Optimization”:
Nuño Sempere: In general, I'd favor a style in which for every definition, you give an example.
Nuño Sempere: Who is this document for?
Ozzie Gooen: At this point, us. Later on I'd want to rewrite it into a longer form with more explanation, but hopefully keep the terminology the same.
On “Confidence: 2/5”:
Nuño Sempere: What does this confidence refer to?
Ozzie Gooen: Sorry; it's kind of my confidence that this is generally a good term to use; it's a combination of the specific term and the "idea of the term"; independent on which specific name we choose.
On “Epistemic Pain:”:
Nuño Sempere: Epistemic Loss
Ozzie Gooen: Thanks! Good idea, I'll think about it.
Ozzie Gooen: "Epistemic loss is typically conceived of as the loss of a corpus of knowledge, or less commonly, as the further loss of epistemic methodologies. " https://www.tandfonline.com/doi/abs/10.1080/21550085.2017.1342966 I think pain, in comparison, will make more sense with future examples.
On “Prediction-Information-Gain vs. Prediction-Accuracy”:
Nuño Sempere: Here is perhaps a rewrite: Improving the engine vs outperforming the engine. In a prediction engine, like a prediction market, we hope that participants improve the market. They may do so by outperforming the engine, for example by beating a prediction market. By being more accurate than the market, they help move the market in the right direction. But they can also improve the engine without outperforming. In a prediction market, this can happen if a participant is inordinately convinced by a factor which the market hasn't taken into account at all yet. They would also help the market move in the right direction, while they themselves are not very accurate. This distinction can be expressed in many ways: - Improving the engine vs outperforming the engine - Adding information to a market vs scoring well in that market - Improving the aggregate vs being better than the aggregate - etc.
Ozzie Gooen: Good point. In general, everything in this doc really does need to be explained better before reaching a larger audience. The main goal right now is just to get a bit of consensus/discussion on the key ideas/terms (though this is tricky without much discussion)
On “Loss”:
Nuño Sempere: I prefer Error
Nuño Sempere: In particular, loss may not make sense as a word in this context unless "minimize the loss function" says anything to you. Error is also Latin, i.e., easier to understand by Europeans.
Ozzie Gooen: Good to know about error being latin, that never would have occurred to me.
On “My guess is that “entropy” would cause more confusion”:
Nuño Sempere: If you make this decision, you may want to rewrite the definition so as not to reference entropy?
Ozzie Gooen: There is a lot of overlap/similarity with entropy; it can be the same depending on loss function and setup.
On “Predictability”:
Nuño Sempere: You haven't defined predictability yet
On “.”:
Nuño Sempere: It may be the case that a question is significantly easier or harder to predict before or after a piece of evidence comes in
Nuño Sempere: Only one set of curves? It's also not really obvious from the name what the curves refer to. (As opposed to, say, "supply and demand curves")
Ozzie Gooen: Hm... I guess there's a question of how many curves we could imagine there being. Happy to be more specific.
Nuño Sempere: Why do you need a technical word for this, as opposed to "prediction accuracy at the limit"?
Ozzie Gooen: It's quite possible we don't. But if people end up using this a lot, they may want a tighter term.
Nuño Sempere: Why don't you just talk about prediction cost, prediction cost-effectiveness, and maybe divide prediction cost in cost of infrastructure vs participant cost / marginal cost?
Ozzie Gooen: Good point, I'm not sure what kind of structure is best here.
Nuño Sempere: Another term I've seen used is recalcitrance, i.e., how the difficulty of smth, in this case prediction, increases as you put more resources into it.
On “Engine”:
Nuño Sempere: +1
Ozzie Gooen: I'm curious to understand why you favor engine. I could see the infrastructure as being the "engine", but the main attribute will be the people, which I'm not used to thinking in terms of "engine".
Nuño Sempere: Black box intuition? I remember I've seen it used in one of Warren Buffet's yearly letters, and maybe I associate it with prestige and other nice things because of that?
Estimating Binary Outcomes using Continuous Distributions
Forecasting · Methods · Nov 2019 · 1,446 words
Imagine you have the question, “Did Emperor Valerian spend his final years of life as a captive at the Persian Court?”[1] The question is either true or false.
You desire to estimate the chances of a particular answer to this question in a structured way. You could use a percentage, but are interested in instead using a probability distribution in order to get more insight.
This begins with you being uncertain what your probability distribution should look like. You decide to use an evaluative prediction chain, which looks like the following:

At each step, you would agree to a 1/100 chance of the next step getting carried out, in order to be accountable to a better signal. If you do make it to step F3, you will then come up with specifications for F5-F10.
At each stage, your goal would be to predict the distribution at the next stage in order to achieve as low a Kullback-Leibler divergence measure as possible.
Imagine that after F1, you are completely unsure of the answer to this binary question. What would a reasonable shape for your F1 distribution estimate be?
Here are three possibly-reasonable options:
Option 1
A curve with a mean at 50%, that levels off to both sides:
=normal(50,10)
Option 2
A uniform distribution from 0% to 100%:
=uniform(0,100)
Option 3
A bernoulli distribution with p=.5. (This would have 50% mass at exactly 0, and 50% mass at exactly 100%).

=bernoulli(.5)
This may not be perfectly obvious at first, but I think the way this question is framed leads to a clear answer.
Imagine that you are quite sure that the true answer should become apparent at F4. In this case, either the answer will be 0%, or it will be 100%.
If that’s the case, imagine you are predicting at point F3. At F3 you recognize that the next step will have 0 probability at anything other than 0% and 100%. If you want to maximize your KL-divergence with your distribution at F4, it similarly makes sense to put no mass at anything other than 0% or 100%. You should use a bernoulli distribution.
But of course, if this is predictable, you can predict that at F2, and therefore F2’s prediction accuracy would also be maximized with a bernoulli distribution. The same is true for F1, so your ideal prediction for F1 would be a bernoulli distribution.
But this is kind of unsatisfying! If you’re just going to use a bernoulli distribution the entire time, you might as well just use a simple probability. A bernoulli distribution contains just as much information as its corresponding probability parameter (if it is known it is definitely a bernoulli distribution).
Using a mean for an interesting distribution forecast
The obvious solution to this is to eventually return a mean, or binary probability, instead of a bernoulli distribution, at some point in the evaluation chain. Say you decide to do this at stage F3.
At this point things seem much more clear. You could definitely have an interesting continuous probability distribution that estimates a specific probability. The beta distribution, for instance, is often used to estimate a specific probability.
The use of the mean would still allow predictions at F2 and F3 to be scored, they just wouldn’t be scored using KL-divergence. F2 would be scored based on the log value of the pdf at the specific point, and the mean probability of F3 would be scored based on a simple probability log score.
4 Scenarios for F1:
Scenario 1
During your investigation at F1, you realize that all historians on the issue are not trustworthy. You become convinced that at F3, there’s very little chance there will be enough evidence to have a very high probability or a very low one. You’re quite sure the mean will average 60%, but you are not sure exactly where it will be at that time. You can break the problem up into a few distinct clusters, but are sure that none of these clusters can be reasonably eliminated until F4. Therefore, you have to take averages of these.
=beta(60,40)*100
Scenario 2
After a small amount of investigation in F1, you become pretty sure that you won’t be able to tell conclusively at F3. You identify a few “clusters” of possible ways that Emperor Valerian could have spent his final years, and think that at F2 or F3, the respective odds of each cluster are likely to change significantly. You make inferences regarding the likelihood and impact of this at F3. This results in the following distribution:
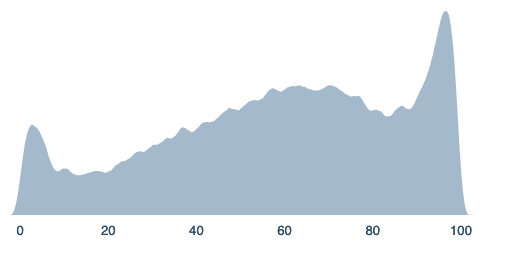
=mm(beta(40,2)*100, beta(2,40)*100, beta(3,2)*100, uniform(0,100), [0.05,.02,.25,.1])
Scenario 3
In scenario 2, you realize that the final answer is likely much nearer than you thought. You become convinced that it will be discovered sometime in F2.
In this case, you know that the result of F2 will either have 100% probability mass at 0, or 100% probability mass at 100%. Correspondingly, F3 will either return 0% or 100% (if you bother to run it).
=bernoulli(.5)
Once again, you wind up with a bernoulli distribution! Rats!
Scenario 4
In scenario 3, you realize that the final answer won’t be discovered in F2, but a “really good” answer will be, that will ensure that F3 will either be within a few percentage points of 0%, or a few percentage points of 100%.
In this case, you may wind up with a distribution that looks similar to:
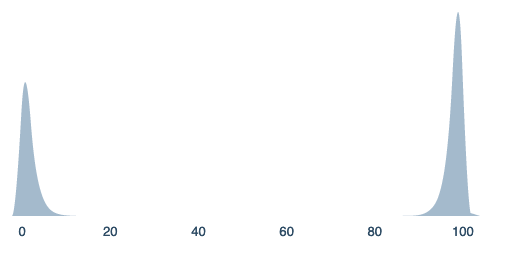
=mm(beta(60,1)*100, beta(1,60)*100,[0.6,.4])
This isn’t as frustrating as returning to a bernoulli distribution. There’s some nontrivial information here; for instance, the specific widths of the two parts of the distribution.
However, it’s pretty similar to a bernoulli distribution. This distribution may be near-optimally represented by two sub-probabilities; the mean, and a measure of dispersion. This makes it more information-dense than a bernoulli distribution, but not by that much.
Some Lessons
We can formalize our results a bit by calling the “Mean Returned” time the “Summary” event; as it could be reasonable to return a metric other than the mean for a similar reason. We can call the “Final Answer Found” as the “Conclusive Evidence”, and the “Really Good Answer Found” as “Crucial Evidence.”
Lesson 1: Carefully selecting when to summarize a probability may be important in order to maximize the use of non-bernoulli-like distributions.
The first important question is what step to select for the summary measure. If it’s done after sufficient evidence is available, all previous distributions will be bernoulli-like. If it’s done very early on, then there may only be one or two prediction steps that can be non-bernoulli distributions. In general you probably want to maximize would be non-bernoulli-like distributions; but setting summary too early or too late seems to minimize this.
Lesson 2: Predicting a distribution that represents a binary variable seems quite tricky!
When doing this, you seem to need to have a good idea of how much convergence will occur at what points in time, and also how that relates to when summarization will occur. More generally, back-chaining to understand the possible types of distributions at later stages, and chaining back to the current time in order to estimate your best guess at a distribution, seems normally quite tricky. There probably could be a lot more work done here to make sure predictors don’t make dramatic mistakes.
Lesson 3: Distributions are particularly informative if they are informed by distinct scenarios that will collapse before the summary.
Takeaway: Maybe there are better things than distributions
The thing that seems to make distributions interesting for purposes of prediction is that they can help reveal several parameters about a model. If so, these could be recognized and used to divide labor; different predictors could essentially adjust different aspects of the model by the simple task of updating their probability distribution.
Of course, another type of input that would do this would be that of a model. If “predictors” could instead formally input their models, that could be more useful than even giving their probability distributions. However, this would create additional complexity.
[1] Final note: This particular question was attempted on Foretold. You can see the answer here, though it’s recommended you do so after finishing this post.
https://www.foretold.io/c/f19015f5-55d8-4fd6-8621-df79ac072e15/m/83494e3d-4662-4540-8fe6-1c9b8520d2d6
Calculating the Shapley Value of Impact
Forecasting · Methods · Dec 2019 · 752 words
Question:
Your name is Emma. You see 50 puppies drowning in a pond. You think you only have enough time to save 30 puppies yourself, but you look over and see a person in the distance. You yell out, they come over (their name is Phil), and together you save all the puppies from drowning.
Calculate the Shapley values for:
The correct answer, of course, for both, should have been “an infinitesimal fraction” of the puppies. In your case, your parents were necessary for you to exist, so they should get some impact. Their parents too. Also, there were many people responsible for actions that led to your being there through some chaotic happenstance. Also, in many worlds where you would have not been there, someone else possibly would have; they deserve some Shapley value as well.
In moral credit assignment, it seems sensible that all humans should be included. That includes all those who came before, many of whom were significant in forming the exact world we have today.
However, maybe we want a more intuitive answer for a very specific version of the Shapley value; we’ll only include value from the moment when we started the story above.
Now the answer is Emma: 40 puppies, Phil: 10 puppies. In total, you share 50 saved puppies. You can tell by trying it out in this calculator.
Now that we’ve solved all concerns with Shapley values, let’s move on to some simpler examples.
Question:
You (Emma again) are enjoying a nice lonely stroll in the park when you hear a person talking loudly on their cell phone. Their name is Mark. You stare to identify the voice, and you spot some adorable puppies drowning right next to him. You yell at Mark to help you save the puppies, but he shrugs and walks away, continuing his phone conversation. You save 30 puppies. However, you realize that if it weren’t for Mark, you wouldn’t have noticed them at all.
Calculate the Shapley values for:
Question:
You (Emma again) are enjoying a nice lonely stroll in the park when you hear a rock splash in a pond. You look and notice some 30 adorable puppies drowning right to it. You save all of the puppies. You realize that if it weren’t for the rock, you wouldn’t have noticed them at all.
Calculate the Shapley values for:
Question:
You (Emma again), are enjoying a nice stroll in the park. Alarmedly, 29 paperclip maximizers inform you that a paperclip is going to be lost forever, and 30 adorable puppies will drown unless you do something about it. You, together with the paperclip maximizers, spend three grueling hours saving the 30 puppies and the paperclip.
Calculate the Shapley values for:
- You (Emma)
- Each paperclip maximizer
Question:
You (Emma again), decide that this drowning puppies business must stop, and create the Puppies Liberation Front. You cooperate with the Front for the Liberation of Puppies, such that the PLF gets the puppies out of the water, and the FLP dries them, and both activities are necessary to rescue a puppy. Together, you rescue 30 puppies.
Calculate the Shapley values for:
The Puppies Liberation Front:
The Front for the Liberation of Puppies:
Question:
The Front for the Liberation of Puppies splits off a subgroup in charge of getting the towels: The Front for Puppie Liberation. Now;
- The Puppies Liberation Front gets the puppies out of the water
- The Front for the Liberation of Puppies dries them
- The Front for Puppie Liberation makes sure there are enough clean & warm towels for every puppie.
All steps are necessary. Together, you save 30 puppies. Calculate the Shapley value of:
The Puppies Liberation Front:
The Front for the Liberation of Puppies:
The Front for Puppie Liberation:
Your name is Emma. Phil sees 30 puppies drowning in a pond, and he yells at you to come and save them. To your frustration, Phil just watches while you do the hard work. But you realize that without Phil’s initial shouting, you would never have saved the 30 puppies.
Calculate the Shapley values for:
You are Emma, again. You finally find the person who has been trying to drown so many puppies, Lucy. You ask how many puppies she threw into the water: 100. Relieved, you realize you (and you alone) have managed to save all of them.
Calculate the Shapley values for:
Comments from Nuño Sempere
Restored with permission (Nuño's comments, with Ozzie's replies).
On “The correct answer”:
Nuño Sempere: Thought: Suppose that you have a decision theory. This decision theory tells you which agents will act differently if you add differently / would have acted diferently if you choose to act diferently. Use that subset of agents as the participants in your SV calculations.
Nuño Sempere: (This fails because it works badly with actions which people have taken in the past. But I think it points at something).
On “parents”:
Nuño Sempere: I don't think this is a take-down argument. Suppose that our ancestors are responsible for 99.99% of all Shapley value; maximizing for SV and maximizing for SV*0.01 has the same results.
Ozzie Gooen: It's not meant as a take-down argument. I like shapley values (better than counterfactuals, where applicable), but am just trying to point out some counterinuitive things. If I release this as a blog post I'll write a paragraph or so to make that more clear.
On “Calculate”:
Nuño Sempere: Intuitive: 30 & 0
Nuño Sempere: Another interesting thing is that if Mark is not optimizing for Shapley values, sure, in this case he'll get some SV (and some counterfactual impact), but over time, altruists will still get more SV.
Ozzie Gooen: If that's the case though, there's a big gradient between Mark and a rock that we could get into. Would an urn of someone's dead ashes count? Someone in a coma? Dirt that contains a fraction of the remains of someone who died?
Nuño Sempere: Intuitively: 30 and 0
On “Calculate the Shapley values for:”:
Nuño Sempere: Intuitively, 30 puppies and 1/30th of a paperclip
Nuño Sempere: So the answer to this is +50 & - 50, respectively, which I still find unintuitive.
Judgemental Predictions are Low-Signal, High-Skill
Forecasting · Systems · Jan 2020 · 2,396 words
A Simple Example
Say you want a web application to catalog information about North American fish populations. You’d probably realize that you need at least one software engineer and one expert in marine biology.
You would not ask the marine biologist to attempt to write the software themselves, because it’s unlikely they would have the expertise. You’d probably be willing to pay a lot more for a well-functioning application than a poorly organized spec sheet.
Now imagine instead you want a forecast of, “What are the chances that fish populations around New York will collapse before 2030?”
It seems obvious that you’d probably want a domain expert here, but it’s less obvious if you’d want a forecasting expert. You may have the option of hiring a superforecaster, or better yet, a team of superforecasters.
One problem is that the result of the superforecaster would look nearly identical to the one by the domain expert, or one by anyone off the street. The result could be about as simple as a probability, like “42%”.
Would you pay much more for the superforecaster to tell you “42%” than for the domain expert to tell you, say, “58%”?
The main conflict I’m raising here is that judgemental forecasts by themselves often don’t come with much information to signal how valuable they are. The result of 5 hours, 10 hours, or 500 hours of work by radically different groups of people would itself look near identical. This could mislead someone to believe that it is an easy job; “I don’t see why that superforecasting team is getting paid so much money to produce 10 guesses. I’d agree to make 10 guesses for only $10.” But looks can be deceiving.
Different forecasts can appear to be equally trustworthy, but in reality, some should be valued hundreds of times (or more) as much as others.
Forecasts can be “low-signal”, but possibly, very “high-skill.”
Is Judgemental Forecasting High-Skill?
Philip Tetlock has done a fair bit of work around answering the question of how good people are at Judgemental Forecasting, and in what conditions. His book Expert Political Judgement laid out evidence to suggest that political experts generally performed poorly at judgemental forecasting around political topics. The book Superforecasting highlights how the top talent in large forecasting competitions were able to repeatedly outperform the rest. The top 2% of forecasters in this work were labeled “Superforecasters.”
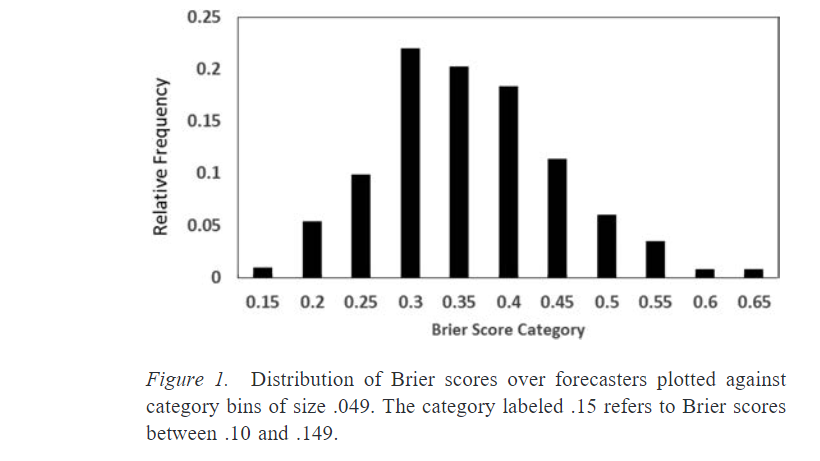
The above is a graph of the average brier score for forecasters in one of Philip Tetlock’s studies. Some forecasters clearly did significantly better than others. AI Impacts discussed this graph and related results in this post.
For this set of questions, guessing randomly (assigning even odds to all possibilities) would yield a Brier score of 0.53. So most forecasters did significantly better than that. Some people—the people on the far left of this chart, the superforecasters—did much better than the average. For example, in year 2, the superforecaster Doug Lorch did best with 0.14. This was more than 60% better than the control group.12 Importantly, being a superforecaster in one year correlated strongly with being a superforecaster the next year; there was some regression to the mean but roughly 70% of the superforecasters maintained their status from one year to the next.13
In the graph, the mean is around 0.4, and the best 2% probably averaged around 0.2. This is a highly significant difference.
A specific caveat not typically discussed is that one of the main predictors of superforecaster accuracy is just the boring work of keeping one’s forecast updated over the duration of the experiment, as David Manheim described in this comment. I think there are two considerations here. One is that consistent updating is an important attribute at times. Many “bad” forecasters are bad because they refuse to update their forecasts systematically, and that does make their averages worse. The second consideration though is that this may be bad for the “Judgemental Prediction is High-Skill” “hypothesis”. More research here would be very interesting.
A different challenge around forecasting being considered “high-skill” is that the learning curve appears to be currently much lower than it is for other acknowledged high-skill activities. It’s clear that someone needs years of medical training to become a good doctor, even if they are brilliant. With judgemental forecasting, there may only be a few weeks of obvious and explicit training. The Good Judgement Project has shown that select training is useful, but they have a very limited amount of it. [2] The rest of forecasting skill is so-far unteachable.
But there are many high-skill activities that are difficult to teach. It’s quite clear that some people do far better than many others at sales, management, stock picking, music, acting, and sports, while there is relatively little crucial academic knowledge for these areas. I think we can still consider these activities “high-skill”.
Financial trading firms and consulting firms arguably do some work very similar to judgemental forecasting. They both also hire from several different undergraduate majors and don’t have a necessary follow-up multi-year training program. One thing they do filter highly for is intellect and academic success. They often pay very well for “top” talent, despite the lack of course relevance.
Defining Low/High-Signal, Low/High-Skill
I’m using these terms loosely, but wanted to give possible more specific interpretations.
Low/high-signal refers to the ease at which most recipients would be able to ascertain quality. High-signal skills would be ones where it’s easy to evaluate quality. Someone who’s amazing at running quickly could prove their ability in a few minutes by running quickly, or a few seconds by showing a trustworthy website with records of their recent abilities.
If you can select someone for a job based on a 1-3-day interview, even if they have a poor resume, that’s a sign of it being high-signal. Much of software engineering works this way.
If a public speaking presentation begins with 4-8 minutes of an introduction on all of their accomplishments, it is a sign that a lot of explicit signaling is necessary, and thus a signal that their work is relatively low-signal otherwise.
Low/high-skill refers to how sensitive output quality is to input skill. Most jobs on assembly lines are explicitly crafted to not be sensitive to changes in skill. An amazing assembly-line worker may only be a very small amount more productive than an average worker. Some other jobs clearly do have high sensitivity to skill. A runner will produce a result almost directly commensurate to their own ability.
Here’s a quick attempt at a rough breakdown:
Low-Signal, Low-Skill: Virtual assistant work
High-Signal, Low-Skill: Assembly line work, Retail positions
Low-Signal, High-Skill: Product Management, Managerial Consulting, Medical Professionals, Teachers
High-Signal, High-Skill: Software engineering, Musicians, Athletes
Expertise is a weak signal of Judgemental Forecast quality
Sometimes judgemental forecasts can seem to be much higher signal than they actually are. Before the explicit research on judgemental forecasting, people highly respected individuals who seemed to be good at it. Psychics, religious predictors, politicians, and political pundits would fall into this category.
Yet, now we know that these were rather weak signals.
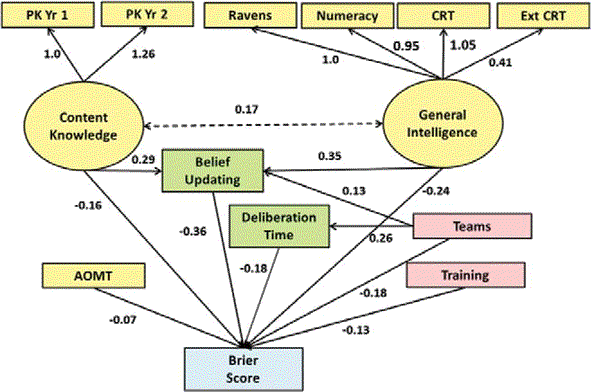
I think the lack of correlation between content knowledge and judgemental forecasting accuracy in particular is still highly unintuitive to most people. In the graph above it’s labeled as explaining a rather small faction of accuracy. The book Expert Political Judgement focussed on what was essentially this topic (though in arguably biasing settings) and similarly came to the conclusion that seeming experts really weren’t that great at doing forecasting.
Say I am trying to get a sense of “What are the chances that the US will go to war with Iran in 2020?” One thing I may first do is to go to the most recognized political scientists and see what they think. A few may have written extensively on this topic, so I think I could easily assume that those are the ones to listen to.
If I were skeptical of them for whatever reason, my first instinct would be to try to read from them and a few other sources, and then make up my own mind.
If a friend disagreed with me, our first instinct to resolve the disagreement may be to spend a long time arguing back and forth on the political details.
Yet, written expertise is a poor signal of judgemental forecasting, so I shouldn’t highly trust the experts when they make predictive claims. I shouldn’t necessarily believe my own intuition that much more, as I don’t have significant evidence that I actually would do well at similar questions. If my friend could destroy me at arguing the details, this should also give me a relatively minor signal.
None of these people (the academic authorities, myself, my friends who are great at debating) would likely have adequate signal to show they are highly-skilled at the specific practice of judgemental forecasting. If I want a great judgemental forecast, I really should go to prediction markets or other teams of proven forecasters.
If I wanted a well-made cake decorated like a pumpkin for Halloween, I wouldn’t try to make it myself, or purchase it from an authority in Halloween history, or get it from a friend who could argue very eloquently on how cake making should be done. I’d go to a professional with clear experience making great custom cakes.
It would seem weird to treat my important judgemental forecasting choices with substantially less evidence than my cake purchasing choices.
Future & Implications
I think we’ve just really just seen the beginning of valuing and integrating judgemental forecasting. The historic brier/log score is arguably a pretty good signal. One great thing about it is that it’s a single metric. I may have to spend some time going through an engineer’s codebase to get a good sense of how good a job they did, but a simple brier score on a set of forecasts would give me most of the useful information on forecast-specific quality.[3]
Above I defined “Low-Signal” as something like “Low-Signal in general, for most people, so far”. With the right theory and metrics, perhaps forecasting can be very high-signal.
I’d also imagine that forecasting may require significantly more forecast-specific knowledge in the future. Prediction markets and prediction tournaments have so far been made for relatively new or casual users. For example, the questions on these platforms are typically binary instead of continuous. As this happens I’d expect this learning curve itself to be a useful signal to filter out the non-dedicated forecasters.
As forecasting setups are crafted for the sake of potential power users, they may include lots of more powerful but complicated abilities. I’m building Foretold along these lines. One thing I’ve realized is that while many people are poorly calibrated with binary probabilities, they seem significantly more awful with arbitrary probability distributions (I started this way!), at least at first. A few people on the site seem to have gotten a fair bit better over time.
Take-Aways
- 1. There’s still a lot of interesting things we have to learn about specialized judgemental forecaster teams. It’s not obvious how to best think about this as low-skill or high-skill yet, though it seems like it’s relatively high-skill, especially with teams.
- 2. Content knowledge and confidence are mediocre signals of judgemental prediction quality. This means that you shouldn’t highly trust the forecasts of most people who are highly knowledgeable and/or confident.
- 3. Related to point (2), just because you are confident in something, doesn’t mean that you should be. Unless you have rigorous knowledge that your forecasting is at the level of teams of superforecaster, you should probably expect superforecasting teams to do quite a bit better than you on questions where you both compete.
- 4. Related to point (2), if you have the choice to listen to either academic experts, or teams of superforecasters that listen to academic experts, almost always go with the teams.
Further Reading
The Elephant in the Brain describes a lot of useful types of signaling.
https://www.amazon.com/Elephant-Brain-Hidden-Motives-Everyday-ebook/dp/B077GZT9Q1/ref=sr_1_1?crid=2IK73DIL0NBDO&keywords=the+elephant+in+the+brain&qid=1579456110&sprefix=the+elephant+in+the+%2Caps%2C204&sr=8-1
The Case Against Education argues that a lot of academic degrees exist primarily for signaling purposes.
https://www.amazon.com/Case-against-Education-System-Waste-ebook/dp/B07T3QRNLC/ref=pd_sim_351_14?_encoding=UTF8&pd_rd_i=B07T3QRNLC&pd_rd_r=95175786-1415-4472-87d2-6a92ff7b29f8&pd_rd_w=V1tqs&pd_rd_wg=tq9hS&pf_rd_p=04d27813-a1f2-4e7b-a32b-b5ab374ce3f9&pf_rd_r=NYB9R2R44G3W9BD6ZFGC&psc=1&refRID=NYB9R2R44G3W9BD6ZFGC
AI Impact’s summary of “Evidence of Good Forecasting Practices” is quite good.
https://aiimpacts.org/evidence-on-good-forecasting-practices-from-the-good-judgment-project-an-accompanying-blog-post/
Some examples of current expert judgements:
If this were really the case, it could take away
[1] There are technical ways around this if one really tries, so it is possible that they could be “high-signal” with the right work, but we almost never have this work, so in almost all current cases “low-signal” applies.
https://aiimpacts.org/evidence-on-good-forecasting-practices-from-the-good-judgment-project-an-accompanying-blog-post/
[2]
I think one reason for this is that the education required for top-level forecasting performance overlaps heavily with things many humans already currently know. The best forecasters generally seemed well studied in technical topics and select worldly information. But it’s not clear exactly what knowledge is most helpful for political forecasting, and it also seems that it’s possible to do poorly even with huge amounts of knowledge. After all, the experts surveyed in Expert Political Judgement arguably knew more about political information than even the superforecasters, but performed worse.
[3] This does leave out information like how useful their comments were. That would have to be dealt with separately.
Enlightened Willingness-To-Pay Forecasting Exploration
Forecasting · Systems · Jan 2020 · 1,316 words
Author: Ozzie Gooen
I’m interested in running an exploratory experiment to use forecasting to help with minor decision-relevant interventions. The goal is to produce a list of the costs and benefits of various interventions in a way that would be interesting and useful.
This experiment may get written up on LessWrong/the EA Forum, but will not be published. It’s not meant to get statistically meaningful results, but rather to get a feel for how this kind of thing would work and how it may break. If you participate or provide help, we will give proper credit in the blog post if we write one.
I’m currently looking for:
- People to give feedback & intervention ideas
- 2-5 people to act as evaluators
- People to act as forecasting
The proposal:
- We produce a list of 30-100 possible interventions or things that we may have willingness-to-pay for.
- A few individuals sign up and agree to be polled (in step 5). These are called the “evaluators”
- The evaluators join a custom Slack channel made for this purpose.
- A team of forecasters spend a few weeks talking to the evaluators (via slack) and making forecasts of (5)
- We randomly sample 5-20 of the items. On each item, the evaluators do the following:
- We can discuss these options in detail and spend 10-60 minutes each (or more, if you want) investigating them.
- We each give our own probability distribution of our willingness-to-pay for that variable.
- The aggregate of (5 b) is used to resolve this question. Everyone gets equal weight. Example: I make estimate my willingness to pay as =normal(5,2). Someone else says normal(8,3). The resolution would be =mm(normal(5,2), normal(8,3), [.5,.5]).
Enlightened Willingness-To-Pay
Enlightened willingness-to-pay should be considered equivalent to what one believes they would think if they had a very large amount of information about an activity, but not the actual result for a certain case. Think of it as the expected value in terms of money for yourself.
Things you should imagine having when being “enlightened”:
- New scientific studies are released.
- You get to read all of the literature now, and over the next 10-30 years on this topic.
- You get to talk to all the possible experts on this topic.
- You can think about this topic for 1-20 years solid.
Things you should not imagine having when being “enlightened”:
- Outcomes of events. For instance, if you were to consider getting laser eye surgery, you won’t know in advance if an error would actually happen; you would just have a very good idea on what the true probability would be.
FAQ:
Question: What if an intervention could be handled in different ways, with different levels of effectiveness? For instance, maybe there’s good and bad running technique.
Answer:
Assume that the evaluators read comments on the questions, but do not assume that they do the optimal thing. For instance, imagine that they read comments suggesting good running technique, but only some realistic fraction actually takes that advice. The reasoning for this is that we care about making the information maximally value for those who read it, but only for those who read it, and can assume that people reading forecasts also read the comments.
Question:
What if the intervention has a few distinct varieties?
Answer:
Assume that the participants do the expected combination of varieties. For instance, if you estimate the “benefits of ketchup”, and there are 3 different types of ketchup, but you know expect that participants will follow some distribution regarding ketchup consumption, then estimate their weighted-average willingness to pay for that distribution.
Question:
What exactly do you mean by “marginal” interventions?
Answer:
Say person X mediates for 20 minutes a day, and you are estimating the willingness to pay for a marginal “10 minutes per day”. Interpret that to mean the difference between person X spending 20 minutes vs. them spending 30 minutes meditating on a random day.
Question:
Why is this focussed so much on personal things, as opposed to more impactful or large-scale things?
Answer:
First, personal things can be valuable to better understand. Second, more impactful things are likely to be more controversial. Starting with personal "life hacks” is expected to be more playful and acceptable.
Question:
Should we assume these interventions take into account the opportunity cost? For instance, when estimating the impact of “10 minutes meditating”, should we include the cost of losing 10 minutes of time of other things?
Answer:
No. Imagine the time comes for free. That way it will be easy to compare costs & benefits separately later on. For instance, an evaluator can weigh the “$38 of value from meditating” from the cost of “10 minutes of their time” by themselves.
Example:
Intervention: The health effects of a marginal 10 grams of white sugar.
Assume that 10 grams of sugar will be added to your body one day without being able to taste it. How much would you be willing to pay to have or stop this from happening? This is likely an unhealthy addition, so perhaps you would be willing to pay $0.10 to stop this. However, you’re unsure about what you would think if you were “enlightened”; had you spent a lot of time investigating the issue and getting science from the future. So you estimate “=normal(-1.2 to -.01)”.
Average American…
Current List (Feel free to add comments with suggestions of other things)
Health
10g white sugar (just health effects)
10g brown sugar (just health effects)
1 pack stevia sugar-replacement (just health effects)
1 diet coke
1 cup coffee, black
5 ounces red wine, 12% alcohol
12 ounces regular beer, 5% alcohol
1 Orthomega Fish Oil Capsule
6 Enhanced Zinc Lozenges taken correctly, for first day feeling sick
6 Enhanced Zinc Lozenges taken correctly, for third day feeling sick
10-minutes “mediocre headache”
10-minutes “mild cold”
2-minutes vomiting
10-minutes meditation
10-minute walk, casual pace
10-minute bike ride, casual pace
1 marginal glass of water
10-minutes extra of primary sleep period
10-minutes walking in nature
10-minutes commuting, driving
10-minutes commuting, walking
10-minutes commuting, riding bicycle
10-minutes of stretching
30-seconds washing hands
1 day of having a cold
1 day of wearing a face mask
Media / Education
10-minutes browsing Reddit
10-minutes browsing Facebook
10-minutes watching Netflix
10-minutes reading the EA Forum
10-minutes reading LessWrong
10-minutes of reading political news on the New York Times
10-minutes reading articles on The Economist
10-minutes reading articles on Breitbart
10-minutes reading a math textbook
10-minutes listening to podcasts
10-minutes watching an in-person academic presentation
Social
10-minutes social dancing
10-minutes talking with close friends
10-minutes talking with casual friends
10-minutes video games with friends
Other
1 micromort
1 microtopia (A 1 of a million chance of a positive AGI Future vs. total sentient extinction)
1 extra year of healthy life, conditional on dying in the next 90 years (to exclude cryonics/AGI).
10 minutes spent commenting on the Slack or Prediction pages for this experiment
1 hour lost today
$1, given 1 year from now
$1, given to self 1 year ago
Spending 10 hours reading this table of forecasts, vs. not being able to have seen them at all.
- This is only to get at the benefit that evaluators will get from making life choices differently. It is not meant at all to cover differences they may make in the actual evaluations had they not seen this information.
Spending 10 hours reading this table of forecasts, vs. not being able to have seen them at all, conditional to 10 times as much effort being spent on forecasting.
Meta Predictions
Thoughts on the Linguistic Etiquette of Nomenclature
Epistemics · Jan 2020 · 654 words
Presuppositions in Names
“The 8 Methods of Exploration”
“The Master List”
The Heuristic of Expected Multiple Discovery
One nice property of a good name is that it would have been expected to have been separately identified and chosen by multiple hypothetical discoverers. For example, Claude Shannon used the term “information” for a technical concept in his paper “A Mathematical Theory of Communication.” It would have been very possible for him to have instead named this a new work like “shlonah”. However, this technical concept mapped quite closely with existing intuitions around vernacular definitions of “information”, so referring to the technical term by its’ vernacular similar was quite intuitive. One could imagine that had another person defined the concept without seeing this paper, they too may have used the word “information” for this purpose. It seems like calling it “information” both satisfied the considerations of:1) Being relatively intuitive to technical readers.
2) Was the likely word to be used had someone else name the concept.
Perhaps this is more apparent when the definition is a clear combination of multiple related words in a way that implies the correct meaning. “Information Theory” is an evident name for a scientific field based around the technical definition of information. Something like “Claudism” would likely have been much worse.
https://en.wikipedia.org/wiki/List_of_multiple_discoveries
https://en.wikipedia.org/wiki/List_of_misnamed_theorems
https://en.wikipedia.org/wiki/List_of_examples_of_Stigler%27s_law
https://en.wikipedia.org/wiki/Stigler%27s_law_of_eponymy
https://en.wikipedia.org/wiki/Eponym
Positive Verbal Affects as a Fixed Public Resource
The space of existing beliefs and intuitions within a community on a set of terminology can be considered a fixed public resource in regards to new terminology.
For example, a group could have strongly positive impressions of the word “liberty”. If a company were to market themselves under the name “Liberty”, they would likely be benefiting from this positive affect. Perhaps the company calls itself “Liberty Technology” to invoke positive associations.
One challenge is that the space of available terminology is a limited good. If one group were to call itself “Liberty Technology” and became popular from doing so, that would limit other groups from using “Liberty” in their names.
The first reason for this is “replacement”; a second group also called “Liberty Technology” would encounter clashes with the first, and other groups with similar names would also face confusion.
The second reason is the potential for the presence of negative externalities. Perhaps Liberty Technology collects and sells large amounts of data on its customers to Spyware companies and causes a corresponding scandal. If so, community members may develop a negative connotation of the word “Liberty” that could apply to all future uses of the word. This can be viewed as a negative externality of the impact of “Liberty Technology” on the space of names near the word “Liberty.”
Note that at any point in time, there may only be a fixed number of words with positive affects to the extent as “Liberty”, especially in relation to many kinds of specific business types.
One suggested solution for dealing with problems of fixed public resources is to tax participants in proportion to the counterfactual cost and externalities of their uses of terminology. A brand would have to pay a fixed fee to use the name “Liberty Technology” if it were evident that Liberty was a popular word and that their use of the name would displace naming of other actors. They may have to pay an additional fee in correspondence to any negative externalities they cause, or perhaps gain a subsidy on positive externalities they cause.
This kind of setup is related to the WWW domain system. While top-level domain registrars don’t typically charge different prices for different domain names, markets are quickly established as users and domain parkers purchase domains and can circumstantially sell them off. Calinsurance.com was reportedly sold for $49.7 million, for instance.
“Forecasting Force”: Early Ideation
Forecasting · Systems · May 2020 · 1,565 words
Experimental Forecasting Task Force (EFTF): Early Ideation
Summary:
The EFTF is an idea for a dedicated group of 3-9 full time equivalents that performs end-to-end forecasting with a rapid turnaround time. It would work on a range of topics, prioritizing Effective Altruist concerns and globally important decisions.
This is proposed for the primary focus of the Quantified Uncertainty Research Institute for the next 2-4 years.
Description of need
There's currently a lot of excitement around judgemental forecasting but relatively little implementation. It’s not completely clear why this is, but it seems like there is a lot of innovation yet to occur. There are only a few actors in the space and these operate on fairly long timescales. The Good Judgement Project does experiments with year-long and multi-million dollar contracts. The Good Judgement Project Open and Metaculus both rely on volunteer forecasters, who can be unreliable and often don’t deliver rapid and reliable turnaround (on the scale of hours or days).
I believe that at this stage not only are group forecasting methods in need of improvement, but so is development around figuring out which questions to ask. Question development can be quite tricky and require significant iteration. Questions need to be clear, useful, actually interesting to clients, and cost-effective for forecasters to work on.
This thinking very much follows that of Agile software development. Rather than aiming for a Waterfall model style 4-20 month forecasting competition, the EFTF would work in sprints of 1 to 4 weeks. Each sprint will include a full cycle of questions being written, forecasted, delivered to clients, and discussed to make sure they are useful and decision relevant.
The goal would be to learn how forecasting can be cost-effective by rapidly iterating with different setups and on different kinds of questions.
Possible Team Composition
Note that full-time means 40-hour-weeks. These can technically be employees or contractors.
Small Team (~$200K-$500K/yr)
- 1 general manager
- 2 full-time forecaster equivalents
- 1 part-time engineer
- A network of advisors in various domains
- 1-2 virtual assistants with different skill sets
Medium Sized Team (~$400K-$900K/yr)
- 1 product manager
- 1 client lead (Identify clients, communicate to clients, write questions, deliver results)
- 2-3 full-time judgemental forecasters
- 2-20 part-time Forecasters contractors with various specialties, on an on-needed basis
- 1 full-time Interface/scientific engineer
- 1 part-time data engineer
- 1 part-time data scientist
- A network of advisors in various domains
- 1-5 virtual assistants with different skill sets
Cohesion vs. Specialization
Some forecasting topics may require a fair bit of background knowledge. Traditional research groups achieve this by specialization. A team of 10 researchers may focus in 10 different areas and barely need to communicate with each other. This is good if they each have all the skills needed for their work, but in our case things are more complicated. Some members will be focussed on question writing, research, forecasting, data science, and engineering.
In our situation the team will represent a diverse set of domain-agnostic skillsets and would be interested in experimenting with a wide domain of fields. Fortunately it seems from research and practice that superforecasting teams with GJP have done very well in many fields outside of their focus areas, so this would be in line with this work. However, it may be the case that over time the forecasters would specialize into sub teams over longer timespans, rather than constantly working on the same topic during each sprint.
Engineering & Long-Term Work
It’s likely much of the engineering work will operate on different schedules than the forecasting work. For example, some projects the forecasters may work on may require no engineering work, and others many weeks worth.
Example engagement
The (fictional) nuclear safety research team Researchers On Nuclear Risk (RONR) recently completed an analysis of Pakistan-India relations. In this they’ve established an index for measuring nuclear risk between these two countries. They provide an estimate for the likelihood of nuclear attacks based on various levels of this risk index; for example, a score of 50 means there is a 0.001% chance per year of a nuclear attack.
RONR works with the the EFTF client lead to further clarify these questions. The EFTF forecasters start work to verify the estimates made by the nuclear safety group. This is done by helping make these estimates very specific, then having the EFTF forecasters give their own takes upon consideration. The EFTF forecasters determine that the researchers seem significantly pessimistic about some elements of the index, but besides that seem reasonably calibrated. These disagreements lead to a realization that the definition of “nuclear attack” was understood differently by different individuals in both organizations, so this is clarified, then more predictions are made. The results of this are made public.
The next step is to put together a plan for continuous judgemental forecast updates. It’s decided that these forecasts will be updated on a yearly schedule going forward. EFTF commits to spending at least 2 weeks working with this nuclear safety groups and others to update these forecasts on this schedule.
The EFTF engineering group starts related work a few weeks after the judgemental engagement. The main elements of the nuclear safety index are based on publicly accessible data. The process of organizing and tracking them can be automated, but requires engineering effort that the research group does not have. The EFTF engineers handle this work. The EFTF also helps build an automated model that combines this data with the judgemental forecasts to produce automatically updated risk index forecasts.
Because both the primary judgmental forecasts and the automated index forecast are publicly accessible in a common format, they are used in other models by EFTF and other organizations that determine total global nuclear risk, which are in turn used by other models that determine total global existential risk. This is done using the forecast APIs, meaning that they will continue to be updated as new predictions are made.
Comparisons to other services
Engineering Consultancies
Engineering consultancies often have a wide range of specialties on diverse teams. For example, product designers, designers, product managers, frontend engineers, backend engineers, and tech specialists. They can be most effective when many of these skill sets are important for a project, but are lacked by their clients. They can do intense work to set up new systems, or ongoing efforts to maintain systems. Often a team of 4-8 may work between 5-20 clients over the course of a year.
In our case things are similar. Combinations of skill sets are important for forecasting setups to be useful, and it doesn’t yet make sense for many other organizations to try to set up full internal forecasting teams at this point.
Similar to these engineering engagements, forecasting engagements would likely entail upfront periods of setup followed by ongoing maintenance. The upfront setup would involve question definitions and initial predictions. The “maintenance” would involve keeping the predictions and relevant data up to date at regular intervals.
Effective Altruism Related Research Teams
EFTF work would look very different to the vast majority of academic research that is currently being done. The specific part of “clearly defining forecasting questions and then ensuring that a team continues to forecast them” is typically a very small part of the research process. Traditional research papers can be great for coming up with new insights, understanding ways of looking at questions, and summarizing existing work, things that the EFTF would not be particularly focusing on. Hopefully research teams could be great collaborators for EFTF efforts. Researchers could act both as clients and as advisors.
Superforecasting Teams
The Good Judgement Project charges for the services of small teams of superforecasters. They seem to work in engagements that last several months at a time in order to focus on 5-15 questions over that period. From what I can tell, this service is a rather small part of the Good Judgment Project’s client portfolio. Most of their existing contracts are under nondisclosure agreements, and in general they don’t share that much research in learnings of how these groups best operate. These teams are also typically mainly superforecasters, rather than more diverse teams with engineers, data management, and research assistants. The EFTF would be more experimental in technique, follow a compressed workflow, and release their research and process improvement findings to the public.
Open Prediction Tournaments
There are several examples of large predictions tournaments. For instance, The Good Judgement Project Open and Metaculus. These can be cost effective ways of getting many forecasters on well-defined questions. This seems to be the best way of achieving scale and on relying on inexpensive volunteers, but can be challenging in other ways:
- The turnaround can take a significant amount of time.
- It can be difficult to ensure that the necessary questions are properly forecasted on specified schedules, especially when there are many questions.
- These systems don’t work with steep learning curves, so need simple interfaces that exclude possible functionality.
- The questions, predictions, and aggregations need to be public, or at least available to many people.
I think that open platforms may be a large part of the total solution. It’s possible that Foretold can still be encouraged for larger groups.
Prediction Star System
Forecasting · Methods · Jun 2020 · 1,381 words
Other possible names:“Cost to outperform”?
“Forecast quality rating system?”
“Cost to achieve accuracy”?
“Adjusted Forecasting Outperformance Cost”
“Effort score/index/rating”
“Robustness”
Background
Some group forecasts are the result of so little investigation as to be near useless, and others are near impossible to outperform without large data and analyst teams.
This topic parallels discussion around the efficient market hypothesis. It’s quite apparent that there are professional groups that can outperform the stock market in highly specific areas (as done by hedge funds and select traders), but it takes significant fixed and marginal costs to do so. Good financial institutions find areas that require relatively few intellectual resources for a set amount of return. This could be formalized in equations for something like the “quality adjusted intellectual effort” necessary to make specific amounts of money in various parts of financial markets.
[Note: if someone can recommend discussions of the economics of the costs & benefits of pursuing different trading strategies, and how that impacts the greater stock market, let me know!]
Different questions on PredictIt, Metaculus, Polymarket, and other platforms, get dramatically different levels of activity. It should be assumed that this, and other factors, can dramatically vary the “quality” of forecasts. For example, in mid 2020, “2020 Democratic VP nominee” had 39.7M shares traded, but “Which party will win DE in 2020?” had 82 shares traded. If it were assumed that these were similarly biased in other ways, then a reader should assume that the first question may be fairly difficult to outperform, but the second much easier.
On Metaculus there is an “interest” score for each question and a count of the “total predictions”. These numbers vary dramatically by question. It’s not apparent exactly how to translate this into the question of how much observers of various kinds should trust different aggregates.
An example in finance may be the current Apple Stock Price. This is a very heavily investigated metric with large teams analysts working hard to forecast. A 20-person full-time smart forecasting team could spend 2 years trying to forecast Apple’s Stock Price 1 year out, and wind up not being able to outperform the existing stock price. If one spent $1 Trillion dollars setting up an effective institution to predict Apple’s stock price better than the market, it seems quite possible, though of course not profitable.
Quality here means something roughly like “the challenge to outperform”, which is different from calibration. It’s quite possible to have high calibration but provide an estimate that’s easy to outperform. A naive example would be something like an estimate of “50%” of a long list of randomly chosen binary policy questions.
Starting with a simple score
In a very simple model, we can imagine that forecast quality is solely a factor of how many forecaster-hours went into a given investigation.
Score_simple = number of forecaster hours
This is probably approximately proportional to Metaculus’s interest and number of forecasts, which probably correlate well with hours spent forecasting.
Perhaps we can assume that each prediction on Metaculus corresponds to 20 minutes of investigation. Then a Metaculus question with 300 predictions would have a score of “100 research hours”. It would be expected that as an outsider, if you wanted to beat this prediction, you would need to spend 100 research hours to do it.
Say one question is asked both on Metaculus and PredictIt. On Metaculus, 40 people spend a total of 80 hours on that question over the course of a year. On PredictIt, 80 people spend a total of 50 hours on the question over the last 3 month period. According to Score_simple, score(Metaculus) > score(PredictIt).
Complications
Obviously the previous score is not quite right. It’s incredibly simple. Let’s point out problems, then try to help get around them.
Problem 1: New information may have emerged
It could be the case that the 100 research hours spent on a Metaculus question happened 2 years ago, and significant new evidence has come out since. The previous forecast should still remain calibrated, but maybe now it could be outperformed by a 2 research hour forecast.
Potential Solution: Timestamps
Predictions scores could have timestamps of when they were made and checked. It would be up to the readers to determine how much things have changed and what they should consider the current score to be.
Potential Solution: Continuous decay
Prediction scores could be represented as functions that decrease over time. Maybe these are set up to algorithms that take in feeds of possibly relevant data and can trigger reductions when necessary. For instance, a prediction of the global population in 2040 could be stable for many months, but a news spike around the term “global pandemic” could raise an alarm, dramatically decreasing the score. Humans could also review these from time to time and change the scores manually.
Problem 2: Forecasters vary in quality
It could be that one Metaculus question has 1000 forecasts, but they all come from very new and inexperienced forecasters. There’s quite a bit of evidence that Superforecasters are not just more calibrated but also achieve better resolution than worse forecasters.
Potential Solution: Quality Adjustment
“Quality adjustment” is used in “Quality Adjusted Life Years” to help cross compare various quality and duration of life adjustments. Here it can be used to compare forecasting setups. Perhaps it’s expected that 500 inexperienced forecasters working for 1 hour each would achieve the same amount of accuracy as an experienced team of 5 forecasters, working for 5 hours each.
Each forecasting team is different. Even the same team will vary from question set to question set, as they may become more experienced over time. It probably would be a bit much to try to quantitatively compare every variation of these teams, but one could do this with a much coarser granularity. For example, one method could involve having different weights for different forecasting platforms, and leaving it at that.
Problem 3: Different arrangements of forecasters would produce outputs of differing quality
The wisdom of crowds is well-researched. It could well be the case that 20 great forecasters working for 2 hours is expected to be significantly more high-resolution than 1 great forecaster working for 40 hours.
It’s also recognized that putting forecasters into collaborative teams improves accuracy, over situations where they are all working individually. Collaboration matters and should help total accuracy. In particular, collaboration might reduce redundancy and allow for specialization: in particularly adversarial prediction market setups, each participant might have to research all pieces of information by themselves.
Potential Solution: Quality Adjustment
This could broadly be solved using similar methods as in problem 2.
Problem 4: Available information needs to be accounted for
Imagine that a question on Metaculus only has 20 predictions, but is exactly the same as a heavily traded question on PredictIt. The Metaculus forecasters seem to be simply tracking the PredictIt score.
This brings up a tricky clarification. A reader would have to spend 1 hour to replicate the Metaculus’s accuracy if they had access to the PredictIt score, but 5000 hours if they couldn’t see the PredictIt score.
Problem 5: Problems differ in difficulty profiles
Problem 6: Difficulty to outperform is not the only measure of value
Applying Prediction Star Systems In Practice
In practice, some current platforms apply some of these ideas some of the time. Metaculus displays an interest score and the number of forecasts, but this isn’t adjusted for forecaster quality. PredictIt and Polymarket display trade volume and make the number of trades available. Various Good Judgment dashboards display neither the number of superforecasters nor the amount of time they spent, but presumably these remain relatively standardized from question to question.
Ideally, a third party, such as Metaforecast, could come in and determine a common unit (such as stars), and make these comparable. In practice this is difficult, because the solutions proposed above are difficult to automate efficiently. So far, we have instead resorted to asking people familiar with multiple platforms to directly give their quality assessment.
Comments from Nuño Sempere
Restored with permission (Nuño's comments, with Ozzie's replies).
Nuño Sempere: I'd go with "Prediction Star Systems"
Nuño Sempere: Random thought: In practice, I notice that something which would highly correlate with the forecast rating would be the amount I’m willing to bet. I’d be willing to bet $1 : $5 on a prediction I spent 10 mins coming up with, and say $1000 : $ 5000 on a prediction I’d spent a year researching, even though the implied odds are the same.
DistML: A Shorthand Language for Probability Distributions
Forecasting · Methods · Jul 2020 · 2,994 words
July 21, 2020
Ozzie Gooen
Version 0.1
Background & Motivation
The distribution syntax in Guesstimate seemed to be relatively successful in both Guesstimate and Foretold. We’re interested in improving this, formalizing it, and making it accessible to other platforms. It would be totally open source and have a fully permissive license (CC0, for instance).
You can play with an early version of the updated syntax here.
I’ve (Ozzie) been the main one figuring this out, but I’ve had a lot of help from several others, especially with the related ReasonML library.
For this document, I’ll refer to the syntax as “DistML”; in part because I don’t want to use this name, and don’t want people to anchor on a different choice.
Having a short text syntax is useful for a bunch of reasons. It’s possible that UI editors will be more commonly used, but I think there will at least be some important cases where having a shorthand is preferred:
Reasons for a shorthand syntax
- The shorthand is very flexible (unlike many non-code UI editors), so is good when flexibility is needed.
- The shorthand is in plaintext, so is trivial to copy & paste between applications. It would be trivial for people to post their predictions on Twitter, Facebook, or in surveys, using this format.
- The shorthand is relatively readable. If other apps exported to this format (where applicable), it would be relatively easy to understand as plain text. This is in comparison to X-Y coordinates or much longer snippets of code, which are quite messy.
- The shorthand is very short, so is simple & fast to store and send via API.
- Unlike writing PyMC3 code or Stan, this can be much simpler to use for simple descriptions of probability distributions.
One potential goal would be to advance, formalize, and standardize such a syntax. Ideally it would be easy to use in all Javascript (and later Python) applications.
I have a lot of uncertainty on the specifics, and am looking for other opinions and feedback. I’ve recently been working on the DistPlus library which helps support it in Javascript.
This syntax really represents a simple programming language or a DSL. That said, other common syntaxes also have features of simple programming languages as well. YAML, CSS, SASS, etc, use it. Lua is often used for configuration and is used in similar ways.
Key Properties
Dynamic
High-Level
Key Questions
1. Are others interested in making this (or similar) a small standard, something used in multiple applications by different application developers and similar?
Even if others don’t use it, I want to formalize it for the purposes of Foretold, Guesstimate, and future apps I work on. I’m curious who else may be interested.
2. What should the name be?
I’m quite ambivalent on the name. Please suggest other ideas if you have or come up with them.
Some options:
- Distax (distribution + syntax)
3. How advanced should we aim for it to be?
The more power that it has, the more expressive it can be, but this comes with additional complexity. For instance, it could aim for all of the functionality of a simple language like Lua.
4. Does it need a separate parser in Python?We’re currently working on a Javascript implementation. It’s a fair amount of work to write this. It would be great to be able to call this from Python, but if we wanted a complete Python implementation that would be a fair bit of work.
Another option would be to support a translation of DistML formats to Python code equivalents.
4. Should we aim for it to be extensible with plugins, or to have all functionality out of the box?
There are some shorthands and/or sugar that may be better as adjustable features that get converted into the standard. For instance, the syntax “5 to 10” may be adjusted over time or configurable, so could be best not to be part of the standard. If a user writes this syntax, it will get converted to a string like, “lognormal(a,b)”, which is part of the standard.
Rather than “plugins” we could also have different options, like “DistML-core” vs. “DistML-quick” or similar, where “DistML-quick” would be a superset of “DistML-core” that has some extra shorthands or features, but can ideally be converted into “DistML-core”. This is similar to Markdown vs. Kramdown, though more about shorthands, than added features.
I also imagine in many cases apps will want additional functions and functionality, so that would be done separately. For example, in Guesstimate, you can type “=@Cities.NewYork.population” or similar to get the NYC population.
5. Should we aim to support mixtures of discrete and continuous distributions?
Our library currently supports this, but this does make several things more tricky.
Example:
| mm(0,3,normal(5,1), [.4,.2,.3]) |
|---|

This is a more generic format, but introduces a fair bit of complexity.
One nice thing is that these mixed distributions can be converted to fully continuous ones on the end of the client, using some assumptions, if needed.
6. Are there other things we should aim to standardize as well, or instead?
Simple Fundamentals
Common Distributions
Continuous
| normal()uniform()lognormal()beta()exponential()cauchy()pareto()triangular() metalog() |
|---|
Discrete
| bernoulli()binomial()degenerate() |
|---|
Note: the current tool doesn’t yet support metalog or the discrete distributions. Metalog seems a bit tricky, but doable, to add.
Functions
These functions are mostly inspired from the library in math.js, which Guesstimate and Foretold initially used. We could also add the trigonometry functions easily enough.
| Function | Notes |
|---|
| floor() | Converts continuous -> discrete |
| ceil() | Converts continuous -> discrete |
| log(x, [,base=10]) | |
| log10() | |
| log2() | |
| sqrt() | |
| pdf() | |
| inv() | |
| cdf() | |
| sample(x, [,n=1]) | |
| mean() | |
| median() | |
| mode() | |
| percentiles(a, [percentiles]) | |
| std() | |
| variance() | |
| min() | |
| max() | |
truncate()
truncateLessThan
truncateGreaterThan
Other names:
filterLessThan,
bounds(normal(5,2), {lower: 0, greater: 100)
Key Optional / Questionable Features
“To” syntax
This syntax is a quick way to write out a 90th percentile. This uses a lognormal distribution when the lower bound is above 0, and a normal distribution when it is at or below 0.
50 to 150
50to150 (not yet implemented)

Possible changes:
- We may want to change this to an 80th percentile interval or smaller, or state this separately.
- It seems most people are overconfident, so 90th is wider than I expect most would really believe as the standard. I’d expect that they also don’t notice the exact percentiles, so they would say the same ranges if these numbers represented their 50th percentile intervales.
- It could make sense to use a different distribution. In particular, the lognormal may not have a long enough tail.
- Maybe the Pearson or Metalog distributions, with a few defaults.
- Causal seems to use triangular distributions for the “to” syntax and give a few different options.
- My guess is that “to” shouldn’t be part of any standard now, but instead converted to the standard notation. Like, “30 to 80” would be converted to “lognormal(a,b)”, where is possible.
Orders of Magnitude
k,K -> thousand
m,M -> million
b,B -> billion
t,T -> trillion
Possible changes:
- We may not want to have this be the standard, be convertible to the standard.
- The lowercase letters are more correct to be used for other things, but in our use cases, those things don’t seem to be used much at all. (For instance, a lower case m should mean “milli”, not “million”).
Regular Distribution Operations
normal(5,1) * normal(10,2)

| normal(5,1) / normal(10,2)normal(5,1) + normal(10,2)normal(5,1)^normal(10,2)normal(5,1) * normal(10,2)log(normal(5,1),normal(10,2)) |
|---|
| uniform(0,1) + uniform(0,1) |
|---|

These operations treat the two distributions as uncorrelated, and do the operations similar to how they would be done in Guesstimate (the functions act on the X axis, so to speak, instead of the Y axis). The most general way to handle this is with sampling.
Pointwise Distribution Operations
normal(5,1) ./ normal(10,2)
normal(5,1) .+ normal(10,2)

normal(5,1) .^ normal(10,2)
normal(5,1) .* normal(10,2)

.log(normal(5,1),normal(10,2))
normal(5,1) .- normal(10,2)
This syntax performs dotwise combinations of distributions.
Possible changes
- We may not want an infix at all to do this.
- “.-” and “./” would need to be used carefully, as it’s possible that they would prevent the result from being a proper probability distribution.
Current Problems
- We still haven’t figured out / decided the best way to do pointwise operations on mixtures of discrete and continuous distributions.
- It’s not obvious how to handle floats. For instance, “normal(5,2) .* 5”. 5 could either mean a discrete distribution with mass at 5 (a degenerate distribution) like, x=5, or a line of y=5. My guess is that most people would assume the latter (the former would return a result that would rarely be useful), but this would break with other cases where it is used as a degenerate distribution.
Degenerate (point) Distributions
Degenerate distributions are distinct from dirac delta functions, though we can also call the ones we use dirac delta functions for simplicity.
Below, we use the multimodal syntax with 2 degenerate distributions at x=0 and x=3. This doesn’t require they use any syntax to convert them from floats to degenerate distributions, but we may want that later for specificity and consistency.
| mm(0,3,normal(5,1), [.4,.2,.3]) |
|---|

A different version could require a wrapping, like,
| mm(delta(0),delta(3),normal(5,1), [.4,.2,.3]) |
|---|
We could require the use of the d() shorthand or other if this is common.
| mm(d(0),d(3),normal(5,1), [.4,.2,.3]) |
|---|
We think that users will sometimes want floats to mean degenerate distributions, and sometimes to mean functions of y=n. It’s not clear if we should make assumptions for them, or leave things to be more explicit.
Multimodals / Mixtures
multimodal(normal(2, 1), uniform(5,8), [.2, .8])
mm(normal(2, 1), uniform(5,8), [.2, .8])

mm(1, 2, normal(5,2), [.2, .8])

This is a simple way to combine multiple distributions into a mixture, with the weights at the end. It’s been used quite heavily in Foretold inputs. One clear case has been when someone wants to assign most of the probability mass to one main distribution, but a few percent to a very wide distribution, “just in case.”
Possible changes:
- We could rename it to “mixture”, with the shorthand of “mix” or “mixt”. This is in some ways more precise.
- Having the “weights” be a distribution at the end is kind of awkward.
Variables
| long_tail = 3 to 20000;main_dist = 10 to 1000;mm(maindist, longtail, [.9,.1]) |
|---|
For readability it would be nice to add simple variables.
Key Questions
- Is this worth the complexity and potential expectations? It would ask that this notation use newlines.
- Should we require variables to declare with the terms “var”, “let”, or “const”?
- Should we allow for additional metadata, like name and/or description?
- If there are multiple lines, can we assume the last one returns, or should we ask that users explicitly state “return”, as, “return mm(maindist, longtail)”...
More Complicated Variable Possibilities
Accept external parameters, to act as functions.
This would also make it easier to pass in variables from other sources, or enable simple functions. For example, an input could take a time parameter t, which is the number of years since 0AD.
| 500*(normal(1.01, .01)^(t - 2020)) |
|---|
Accept external metadata
We could allow parameters to accept hashes with additional metadata, like in the following.
| long_tail = {value:3 to 20000, name: "Long Tail", description:"I think there's a log of uncertainty on the total time"};main_dist = 10 to 1000;mm(maindist, longtail, [.9,.1]) |
|---|
Non-Distribution Functions
This takes a normal distribution and multiplies it pointwise by the simple equation (y=x^2).
normal(5,2) .* (y=x^2)
This function multiplies all of the normal distribution by 3 along the y axis.
normal(5,2) .* (y=3)
This could introduce a fair bit of complexity, but also allow possibly a much broader class of potential distributions. Some would be not computationally tractable however, or not even proper distributions.
It’s not obvious if this format would make sense or could be parsed correctly and easily.
A different syntax for this could be something like
transform(normal(5,2), x => x^2)
transform(normal(5,2), y => y*3)
transform(normal(5,2), (x,y) => (x^2,y*3))
Other quick experiments:
transform(normal(5,2), {x,y} => {x:x*1x,y})
normal(5,2) |> ({x,y}) => {x: x+1, y: y}
normal(5,2) |> xmap(x => *2)
normal(5,2) |> ymap(x => x + normal(2,1))
normal(5,2) |> ymap(y => y + pdf(normal(2,1),y))
yCombine(normal(5,2), 4, (y1, y2) => y1 + y2))
xCombine(normal(5,2), normal(5,1), (x1, x2) => x1 + x2, {correlation: 0.0});
normal(5,2) * 2
normal(5,2) .* 2
normal(5,2) |> ymap(*2)
Some other options / sketches:
f(normal(5,2), (x,y) => (x^2,y*3))
((x,y) => (x^2,y*3))(normal(5,2))
toNormal = r => {value: normal(r,2), name: “My Normal Distribution”}
rTransform = r .* normal(5,2)
{t} => t |> toNormal |> rTransform |> from(0,2) |> normalize
Explicitness vs. simplicity with distributions
Having a shorthand like this presents a tradeoff between explicitness and conciseness. Finding a reasonable medium is challenging.
Regular operations vs. pointwise operations, and floats
This gets converted to:
This gets converted to something like:
The reason for that is that the alternative methods seem quite unusual. For the latter,
normal(5,2) .* delta(3)
Would return a distribution of delta(3), which seems like an unusual thing to be interested in.
That said, it should be possible to make this explicit by writing out,
normal(5,2) .* delta(3)
If that is what is desired.
Normalization
A function like normal(5,2) .* normal(10,3) is not normalized. If it’s being submitted as a prediction, it is assumed it will be normalized in the end.
There can also be a normalize() function when users want to make this explicit, or want to normalize any part of the function.
Normalization & Multimodals
We can assume that all terms in multimodals should get auto normalized before they get scaled and pointwise-added. Maybe there could be an optional third parameter to not auto normalize.
This is to make sure users can write,
| mm(normal(5,2), normal(5,2) .* normal(10,3), [.5,.5]) |
|---|
And have the first part get 50% of the mass, and the second get 50% of the mass. If both subparts were not normalized, then the section function would have significantly less.
This is equivalent to saying that the weights at the end represent the weights out of the total probability mass, instead of weights to pointwise multiply each term by.
Random sampling decisions, and summary statistics
Note: this section is particularly messy right now.
- normal(5,2)
- normal(normal(10,3), 2)
- normal(mean(normal(10,3)), 2)
Normal distributions take in two floats. If one of the inputs is a summary statistic of a distribution (as in #3), then this would ideally be calculated as such. In this case, the mean of a normal distribution could be solved symbolically, so hopefully it would be found to be 10.
The case of #2 is less obvious. We assume here that it means that we should sample from the inside distribution, normal(10,3), and for each sample, we then sample from the outside distribution, normal(normal(10,3), 2).
Here’s another interesting case:
normal(4,2) + normal(std(normal(1,2) + uniform(1,3)),2)
Every time there’s a summary statistic of a distribution, we resolve that function before continuing with sampling.
To solve this, we first calculate std(normal(1,2) + uniform(1,3)), then use that for the other calculations.
- Use sampling for normal(1,2) + uniform(1,3).
- Convert those samples into a shape using kernel density estimation or similar.
- Take the standard deviation of that shape. (Here, assume it’s .5, for simplicity)
- Use sampling to calculate the function, normal(4,2) + normal(.5,2)
- Convert those samples into a shape.
There can also be summary statistics of arrays or sets of items. These don’t work the same way.
Take, mean(normal(5,2), uniform(3,2)).
Maybe in the future we could have a special syntax like {} for the portion that should be done using sampling in one go. Therefore, to make things simple,
normal(4,2) + normal(mean(normal(1,2) + uniform(1,3)),2)
Would be converted to:
{normal(4,2) + normal(mean({normal(1,2) + uniform(1,3)}),2)}
If brackets are only applied around the entire function, as in,
{normal(4,2) + normal(mean(normal(1,2) + uniform(1,3)),2)},
Then it will work differently; the mean will be applied to samples of the subdistributions.
The {} is kind of messy as it’s also used for hashes in js, and other parameters we might want to use. It’s not clear what notation would be preferable at this point.
Comments from Nuño Sempere
Restored with permission (Nuño's comments, with Ozzie's replies).
On “These operations treat the two distributions as uncorrelated, and do the operations similar to how they would be done in Guesstimate (the functions act on the…”:
Nuño Sempere: I understand what this means, but it could be explained better.
[a comment by another collaborator omitted]
Ozzie Gooen: Good point
On “.log(normal(5,1),normal(10,2))”:
Nuño Sempere: ?
Ozzie Gooen: .log is the "dot" equivalent for log, with a particular base. The base would be the value of the second distribution.
On “;”:
Nuño Sempere: do you really want to add ; to the end of each line except the last?
Ozzie Gooen: I'd be fine making this optional. It can be nice to allow people to have multiple statements on the same line.
On “not even proper distributions”:
Nuño Sempere: What would be outputted here? In reasonML this would be a Some(x)/None variable.
Nuño Sempere: Also, in that case, maybe give a function to normalize the result of an operation.
Ozzie Gooen: I imagine that it would basically return one of a few types: [ | NormalizedDistribution(d) | Distribution(d) | Function(f) | Float | `Error(r)| ] Figuring this out is also important, of course.
Inconvenient Associations
Culture · Sep 2020 · 1,042 words
On their own, backpacks are highly optimized vessels for carrying a wide variety of possible objects. On their own, velcro or zippers on shoes can be a time saving mechanism. On its own, running is both faster and a more exercising activity than walking, for many professional locations.
But culture makes things complicated. Backpacks and shoes sans laces are associated with children, so anyone trying to seem professional may suffer a reputational loss from this association. Running to work is associated with people who are a bit insane.
These inconvenient associations aren’t uncommon.
One would think that with backpacks, all professionals could coordinate to arrive at the clearly superior equilibrium of acceptance rather than aversion. Many brands have fought to help make this the case, and many others have fought to exactly not make it the case.
With youthful items like backpacks, trends seem to first get taken up by hipsters and techies, and only then considered by the more conservative groups. The negative associations are replaced with positive ones one adapter at a time, as long as the adopters have positive associations by the later adapters.
Association dynamics often seem inevitable. Facebook had positive associations from the elite college scene, which led to the broad college scene, which led to old people. Young people have negative associations of old people, and in part have rejected Facebook for apps like Instagram and Snapchat. It’s possible that this association cycle will repeat itself indefinitely.
I bet you could tell a whole lot about a culture by categorizing and cataloging its positive and negative associations.
I’d be curious to see how far one could go with an analysis of a culture by its associations. I searched for a few breakdowns of “culture”, and arrived at terms like, “practices”, “biases”, “values”, “norms”, and “beliefs”. I think practices and norms could be understood as the result of the expected values of various interventions, where shared associations can represent a substantial part. Biases are arguably one subcategory of associations. Values overlap with some key associations, but I would expect readers would assume “values” to be much more narrow. I imagine that in many cases “beliefs” are the results of epistemic associations.
Associations are political. Making sure that the right groups and ideas have the rights shades of associations is a major factor in governmental politics, and a visible one in social politics.
(The draft trails off into rough notes here.)
Justified Trust
EA & Eval · Sep 2020 · 814 words
Totalitarian regimes are trusted by their civilians, but they shouldn’t be. They use propaganda and force to ensure trust. They are trusted, but we can say that they aren’t trustworthy. This is called *unjustified trus*t.
Some intellectuals are intelligent and accurate, but are either barely known or incorrectly dismissed. If only they would listen. These intellectuals are trustworthy but not trusted. This is a shame, because no matter how valuable these people could be in theory, their knowledge won’t translate to action.
So, trustworthiness without trust is useless, and trust without trustworthiness is harmful. We can draw this in a diagram:
Here, with a few examples:

We can say that if groups are trusted more than they are trustworthy, they have overtrust. And if they are trusted less, they have undertrust.


These terms should be understood selectively. An individual trustworthy in parts of Aerospace Engineering may not be trustworthy in Economic History. A Think Tank trusted by American Sociologists may not be trusted by Japanese Economists.
Any measure of trustworthiness would be subjective and dependent on the perspective of a given person or group. This doesn’t mean that it’s useless, but rather that it’s complicated. You can redefine “trustworthiness” as “trust by a specific 3rd Party.” For the sake of this document, “trustworthiness” means how trusting you, the reader, would be, given my expectations of the readership.
There are situations where trustworthiness leads to trust. There’s a connection there, but it’s often fairly weak. Scientists have a long history of accuracy that’s led to a fair amount of respect, but they still have a long way to go. Maybe for the TED-talk intellectual audience, for every 10% increase in trustworthiness, a group gains a 2% bonus in trust. Not as high a ratio as boosting academic credentials or sounding confident, but something nonetheless.
Justified Trust in Politics:
American libertarians often argue that governments are not trustworthy. Liberals in favor of big governments seem to think that governments are good enough. I hear relatively little from either about how we can measure and improve justified trust within governments.
There are a bunch of powerful tools only available to governments. If governments aren’t trustworthy the tools will be used for destructive ends. For instance, the American public supported the Iraq War based in large due to overtrust. On the other hand, if governments aren’t trusted, the public won’t allow them to do things. You can see this as American governors are scrambling to fight criticism around basic COVID-19 precautions. This has been mostly a problem of undertrust (though there has definitely been overtrust to encourage this undertust).
So, if governments are not trusted they are powerless, and if they are trusted but not trustworthy they are dangerous. But if somehow, just somehow, they could strike that magical balance of both, it seems to me like it’s difficult to imagine just how good things could be.
On Forecasting
Much of forecasting research focuses on improving accuracy and calibration; on increasing trustworthiness. It’s all kind of useless if other groups don’t actually trust these methods anyway, and generally, they still don’t seem to.
Deferred Trust:
If I trust an expert on matters of nuclear power more than I trust myself on the issue, I would defer questions in the area to that expert. If identifying an expert is challenging, I would find an “expert in identifying experts” and defer to them. If a decent aggregation is available that seems more trustworthy than any individual, I would use an aggregate. Being skilled in assessing trustworthiness seems much higher leverage than being skilled in doing direct research and evaluation.
There are some topics near me where I’m much more knowledgeable than others. I know my personal history and preferences better than anyone else at the moment. But these topics are also those where I expect to be the most biased. If the cost of educating a 3rd party on my knowledge were low, then deferring to them seems generally like the superior option.
Trustworthy vs. Trusted
We can’t discern the trustworthy from the frauds.
If individuals are trustworthy but not trusted, they can’t provide much value.
I want to live in a society with competent leaders who’s competence is trusted.
If you only have one of the two things won’t work well.
I’ve heard that phrase “justified trust” get used here and there
Contemporary
Incremental vs. Radical
Thinking tools…
Overtrust and undertrust
Epistemic deferring
Highly defensible work with low generalizability
https://en.wikipedia.org/wiki/Wikipedia:Avoid_Parkinson%27s_bicycle-shed_effect
Avoiding Undertrust and Overtrust pdf
Other topics
Convenient vs. inconvenient truths / beliefs
-> Truths that’s EV-negative to the “closer party”, though maybe EV positive to a different party.
“Value
Most medical professionals operate under unjustified trust
Association Networks: A Possible Unification of Some Psychological Ideas
Epistemics · Oct 2020 · 1,371 words
I’ve been reading a fair bit of literature on behavior economics, sociology, psychology, marketing, and others, and have been frustrated by much of the terminology and conceptions. There’s a fair bit of great insights, but less in terms of coherent and unified models.
It all reminds me a bit of cybernetics. Before cybernetics was created, Norbert Wiener noticed that similar principles were emerging in several different fields at the same time; neuroscience, engineering, software, mathematics. He decided the principles and terminology should be unified, and worked to help develop cybernetics (which spawned into what we now know as control theory).
The basics of this theory really aren’t novel at all. I’m sure this whole thing is described somewhere in the literature, I just can’t seem to find it. (Please message me or comment if you have ideas)
I’m not sure if this theory is true (all models are wrong, some useful). My impression is that it might be a decent model in terms of being relatively simple for a fair amount of predictive power. It tries to be more “gears level” than other discussions I’ve seen around human/group motivations and signaling.
I think much of the interesting work here is in providing a framework and connecting it to examples in a large number of very different fields. I’d also be interested in attempting to use it to model important groups, and in building computer simulations that obey these principles, to see if other known social attributes fall out of them.
Here are the basic premises:
- People develop implicit and explicit associations between nodes.
- The nodes could be a few things:
- Abstract concepts. Individuals, music genres, places, products, services.
- Emotional states or Felt Senses
- Good and Bad (arguably felt senses)
- Associations are carried through multiple nodes. If you associate silly voices with childish media, and have Bad associations of childish media, you will then experience bad associations of silly voices.
- People have decent ideas about what associations others have about things.
- When forming intuitions, the combination of these associations is highly influential. This process is unconscious, and often not recognized.
- Example: When reading an essay, you have a positive association of the author, but you associate the argument method with an author you have a negative association with. If these are the only two associations, then much of your intuitive judgement of this essay will come from the sum of the relative strengths of these associations.
- The “sum total positive/negative” association of a given thing is a very important factor for decision making.
These premises would lead to the following main conclusions:
- In order to really understand a person or collective (enough to predict their behavior), it would be highly useful to map out the bulk of the associations they hold.
- This would be impossible to fully do, but may be possible to approximate enough to be useful.
Fun Questions to Consider:
- How much money would you need to accept to post on your Facebook wall a highly pro-Trump message, without any explanation? (Assuming you don’t like Trump)
- How valuable would it be for all Effective Altruists to adjust their positive/negative associations of the most valuable 5 things to adjust? For instance, maybe they develop very positive associations with “being friendly to people online” and “being scrappy and getting data”. Reasons are one way of building these associations, but they aren’t the only way.
- How much of organizational culture is just the presence of the associations people have of things? What about just the positive/negative associations?
- Knowing different things or having different skills would not be considered “associations”. I’m curious about situations were one group could know the same things and have the same skills, but their positive/negative associations make a big difference.
- What are the best ways of making diagrams of association graphs? Are there good examples online of these?
- How well do these graphs map to neural networks and other concepts in AI?
Related to:
Boo/yay: Arguably a lot of reasoning is just saying “boo yay” X. That’s equivalent to declaring you have a bad/good association with that thing.
Affect Heuristic: Personal and unconscious positive and negative associations.
Halo Effect: Overgeneralized positive associations
https://www.lesswrong.com/posts/ACGeaAk6KButv2xwQ/the-halo-effect
Racial/Gender Biases: Unjustified positive and negative associations.
Tribalism: Biases that favor a group one as compared to other groups. Similar to collective narcissism, xenocentrism, xenophobia, racial fetishism, and many other words.
Ugh fields: Intense personal negative associations around tasks.
Values: Ideas that seem big and have strongly positive associations.
Simulacra: Communal expansion of associations.
Trends: Waves of temporary positive associations that lead to action.
Fads: Quick trends, often led by second waves of negative associations.
Signaling: A group tries to show that they resemble things that have positive associations, or hide things that would have negative associations.
Countersignaling: The main group has a negative association to a secondary group, so the secondary group will make signals to distinguish themselves.
Reputation: Positive and negative associations of an agent.
Status Symbols: Goods that have positive associations. Related to badges of shame, positional goods, veblen goods, trophy wives.
Narcissism: Highly positive personal associations.
Ad hominem, name-calling, smear campaigns: Presenting negative associations of a person, so that these associations will spread to their ideas.
Appeal to authority: Using positive associations of authority to represent a point. Only works for listeners with positive associations of such authority.
Connotations: “Connotation refers to the wide array of positive and negative associations that most words naturally carry with them, whereas denotation is the precise, literal definition of a word that might be found in a dictionary.”
The Implicit-Association Test: This basically demonstrates implicit associations. Typically just used for positive/negative valence/associations.
Personal Debt: Similar to having a negative association of the person.
In other fields
Neuroscience:
I know very little about neuroscience, but do know that:
- Some neurons seem to represent distinct concepts
- Much of the complexity of the brain lies in the connections between neurons, not the total neuron quantity.
- The strength of these connections is highly complicated and the changes are very significant.
In this sense, arguably, this maps pretty closely to what I am describing as associations between different concepts and emotions.
Natural Language Processing
Arguably, the association maps are very similar to word embeddings or word vectors. Sentiment analysis identifies simple kinds of associations for long lists of items (like, if people have good/bad associations for 100 brands).
Social Media & Social Graphs
Arguably the Facebook “like” graph represents a very crude association graph.
Causal Networks
What if our brains really worked that way?
It’s assumed that groups do different things because they have different beliefs. But what if it’s instead better modeled by them having different associations, and those associations lead to different beliefs?
Structural Equation Models
Arguably structural equation models work a very similar way to what I’m describing.
Yay/boo -> having amendments
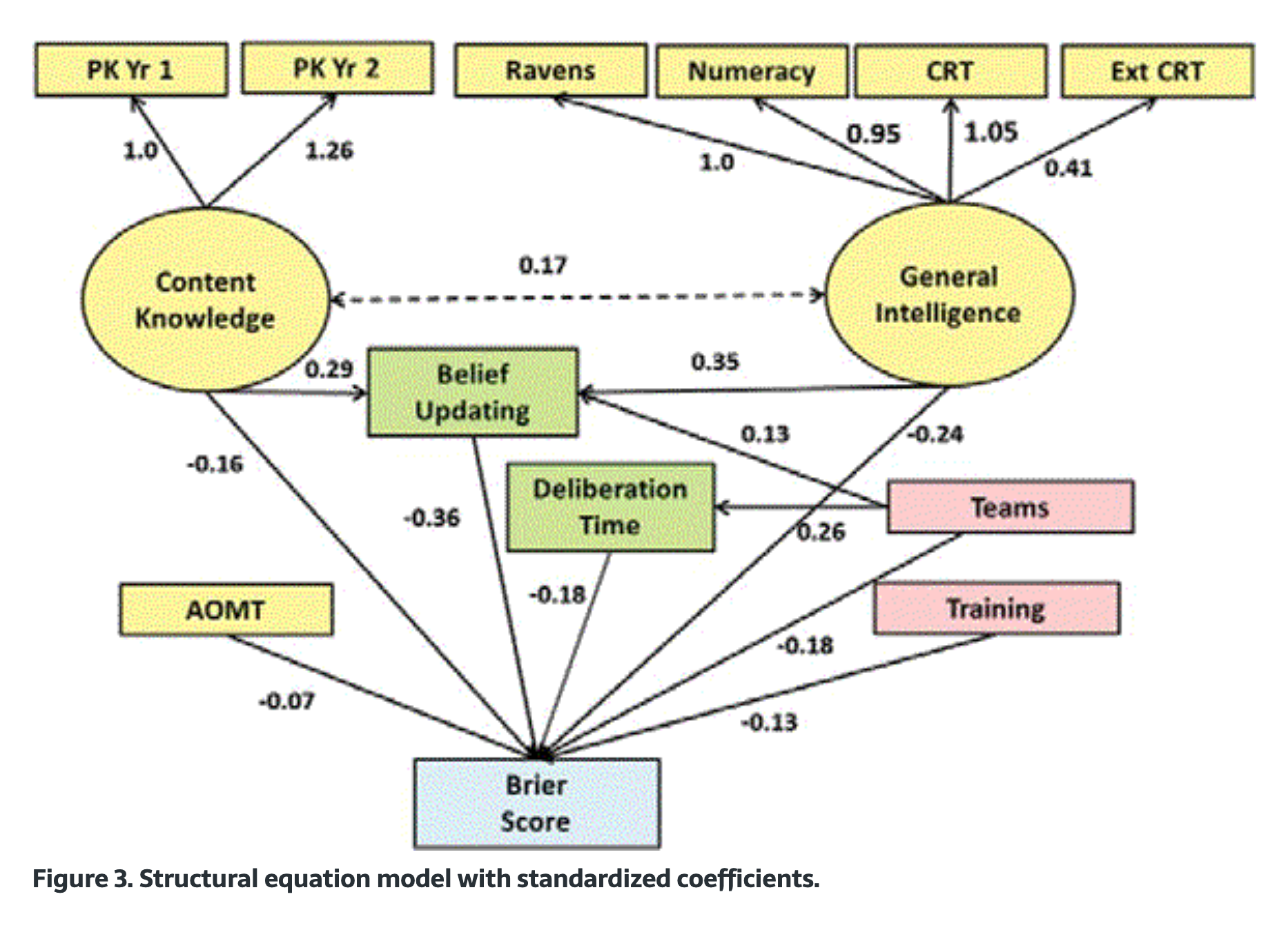
https://aiimpacts.org/evidence-on-good-forecasting-practices-from-the-good-judgment-project-an-accompanying-blog-post/
Ontology discernment
Associations depend on ontologies… so they can only be as fine tuned as one’s ontologies.
“Italian food = good. Italian government = bad”
A simple ontology may lead to “weird people = bad”, but a more complicated one would say, “weird people fall into several clusters, a few of which are good when coupled with specific situations.”
Homogeneous
Epistemic Infrastructure…
“Good and bad gut feelings about things.”
A “Good American” isn’t one who knows about America, but one with the right associations about it and other things. Intuitions
Good/bad -> Valence
A politician says “I love this city!” Kisses the babies, says the like the main things of that area. There’s some empathy, but also some shared interests/valences.
Being interested in an area is not enough… US and USSR were both interested in each other, but for different reasons.
When people describe themselves, they often say: what they do, likes and dislikes.
Culture: “Values, beliefs, underlying assumptions”. “values, beliefs, symbols, and language”
Point: It’s better to get someone to have positive associations of coding than to teach them coding.
Inconvenient Truths
EA & Eval · Oct 2020 · 889 words
Value of Information calculations typically assume that information is always beneficial. But I think most observant people who have dealt with people and organizations realize that this is clearly not always true in real settings.
I think it should be quite clear that there are many cases where individuals or organizations get more value when they either have wrong beliefs or where they lack specific knowledge. Historically, there were many cases where having correct beliefs were highly risky, and the much more advantageous thing to do was to have specific convenient beliefs.
I would like to better understand these phenomena by adapting models or rational agents to incorporate some of these effects.
The purpose of this work is not to argue that we should have more incorrect beliefs. It’s to try to understand what is actually happening, so we can get a better picture of what to expect and how to improve things going forward. I think Step 1 for overcoming inaccurate beliefs isn’t to directly identify these beliefs, but to accept that one has inaccurate beliefs and figure out what purposes they are serving. Then one could be strategic about optimizing.
Some examples of inconvenient truths:
- A parent might not want a list of all the ways they did a poor job at raising their children.
- If someone thought that society would hate them for their sexual orientation, they might feel safer not discovering this themselves. Doing so would pose a risk.
- If a financial institution was to discover that employees were committing large amounts of fraud to external parties, it might well prefer not to know. It’s possible that fixing the problem would be more costly than it would be worth, and having any documented evidence that they were aware and didn’t fix the problem could open them up to substantial legal risk. Better not to know.
An ideal Bayesian agent may be fine at handling these sorts of knowledge, but humans are not ideal Bayesian agents. Humans are often quite poor at keeping deep secrets, and humans are prone to significant feelings of guilt and shame upon knowing certain information. Organizations are made up of humans so have similar biases, plus have additional and operational legal issues.
There are clearly cases of truths that are expected value negative to realistic individual agents. Let’s call these inconvenient truths. Likewise, truths that are EV-positive to an agent is a convenient truth.
Inconvenient truth:
A truth that is EV-negative for a given agent, when either revealed to that agent or to another agent. The agent could be defined as having a high discount function. For example, one could say that a specific truth is “inconvenient in the short term”, but “convenient in the long term.”
EV(truthful claim, agent A, agent B) < 0
Convenient truth:
A truth that is EV-positive for a given agent, when either revealed to that agent or to another agent.
EV(truthful claim, agent A, agent B) > 0
Note: If my group finds out that my previous work turned out poorly, then that would be considered an inconvenient truth for myself. If they find that the passcode to my personal safe was 38492, and use that to unlock the safe, that would also technically be an inconvenient truth. I’m not a huge fan of this latter part, as it less matches my intuitions of how the word “inconvenient” should be used. I’m curious if there is any clear line in the sand here.
This choice of definition is clearly different from its use in the movie, “An Inconvenient Truth”. I’ve thought a fair bit about this and couldn’t come up with better terminology. If you have ideas I’d be very open to changing this. My main priority here is to have a solid structure. I like the term “convenient” because I think the connotation is generally correct. When someone asks, “Wouldn’t it be convenient for you if your argument were true” hints at a definition similar to what I am using.
Now that we have this clear definition of convenience, we can expand it for the following related terms:
Convenient Ignorance:
The not knowing of truths, or the ability to keep on not knowing truths, which results in positive expected value.
Convenient Belief:
A belief that is convenient to hold as a belief, even if it might not be true. More specifically, a belief is convenient for agent A, with respect to being known by agent B, if it would be EV-positive for agent A, for agent B to believe this information. Agent B could be agent A.
Convenient oversight:
Ways of hiding information
Secrets from others
Self-secrets
“Known” by unaccepted (Repressed) “Many people know it, but they refuse to say anything”
Active Repression, No action, Lack of Action
Active Repression, Inaction, Active Truth Seeking
Inaction
Passive vs. Active Repression
Instantial vs. Domain Repression
Instantial: Don’t say “Bloody Mary” 3 times.
Domain: Don’t go into the basement.
1st level, 2nd level, n-level.
Inconvenient Repressed Space (The space of all of the inconvenient truths that are being awaited to be discovered)
Correlated vs. uncorrelated inconveniences …
And correlated vs. uncorrelated unknowns
Convenient oversight
Could also be called desirable vs. undesirable truths.
Secrets, Inconvenient Public Truth, Inconvenient Private Truths
A not-yet-named epistemic story
Epistemics · Nov 2020 · 2,608 words
Need stuff on page....
Government hires the wrong group...
The group has a plan...
"Um... boss?"
"Yes, what is it?"
"Strange thing happened. So, the results of the grant to an "Accuracy and Validity Study" have started to come in. It was apparently part of Executive Order 14002; the weird one amending Reagan's cost-effectiveness order)."
"Ah, one of those orders, I haven't had time to go through them all."
"Well, in the details it grants $20 Million to some small independent think-tank. They didn't trust the regular officials for this sort of work. They requested it be given to an outside party."
"So the government just wasted $20 Million?"
"Probably. The interesting thing is that there seems to have been some sort of mistake. The think-tank was going to be chosen by an in-house committee, but things got hectic and it seems like they rushed the process and made an error. I'm pretty sure that when the order was written it was intended that the contract go to the Bipartisan Research Center or the US Decision Institute."
"Those are both fairly conservative groups, right?"
"Yes. But the contract instead went to some group none of us have heard of called the US Decision Center."
"So the government just wasted $20 Million."
"We have a meeting with them next week to discuss preliminary findings."
A few days later...
"Thanks for inviting me here. As you might imagine, our team has been quite busy since we got the contract."
"Yea, sure, how are things going with that?"
"Well, to be fully honest, we started with 2 of us, so we had to grow a bit to get through the contract."
"And this was... something about accuracy in the government? You did investigation to improve our cost effectiveness estimates or something."
"Well, the task we were given, more specifically, was to optimize the accuracy of estimates placed by government bodies."
"Sure, so do you have a few changes to recommend?"
"Well, yes, but it's a bit complicated. I suggest taking a seat."
(Seat taken)
"I should probably make you aware that UDC is rather novel in that all of our work is backed by a Legal Trust Guarantee. Our colleagues at the Center for Experimental Epistemics and the New Incentives Institute deeply review our work on a stochastic basis, and if they determine that any of it is not correct or has been considerably suboptimal, then all of our funds will be rerouted to an third party entity aimed only at suing us and ruining our personal lives. It's an agreement we've made a while back, it helps make sure that our clients can trust us."
"Please just get to the point."
"So the rules of our US contract specify that we must detail a standard whereby Government claims must be verified in order to be used to justify laws. It's rather a natural extension of cost-effectiveness requirements. We've been experimenting with what standards would look like. The leading candidate is that we take binary claims and evaluate them based on their expected probability of being true. In order for a claim to be considered worthwhile for official approval, it needs to to be considered 85% likely, or around 2.5 bits of accuracy."
"Ok, so we just remove a few claims here and there?"
"Well... we've been reviewing official records, and have found that only 35% of official empirical estimates make this mark."
"So we remove a bunch of claims?"
"Well, those are the empirical statements. Statements like, in 2040 GDP growth will change by over 3% per year. There are also normative and metaphysical statements. Here's a simple example. I take it you are familiar with the phrase, ''We hold these truths to be self-evident, that all men are created equal, that they are endowed by their Creator with certain unalienable Rights, that among these are Life, Liberty and the pursuit of Happiness."
"Yes, of course"
"Well, believing truths to be self-evident requires very precise philosophical positions that are difficult to find conclusive evidence for, and finding accepted evidence for these claims otherwise appears to be quite the challenge."
"You're questioning The Declaration of Independence?"
"A fair amount of legal doctrine is justified under that document, so we'd really want it to hold up for proceeding justification."
"This sounds... insane. But at the end of the day, I'm sure we can just remove a bunch of claims and justify things in other ways. Maybe we just need to formally not make 90% of the sorts of claims we are used to?"
"Well, for empirical claims, there's an average of 1.5 bits of information. For normative and metaphysical claims we've measured an average of 3 zeros."
"Like, 1000 bits? That's good, right?"
"No, like 0.0001 bits of information. It's quite low madam."
"So we just remove these sorts of claims?"
"Well, that's the problem. Most of the laws don't quite work without them. It's easy to say that a Sales Tax modification will increase revenue by a fixed percentage. But it requires a belief in a normative statement in order to claim that increasing revenue is a good thing."
"But obviously increasing revenue is clearly a good thing."
"Can you produce a vast set of clear and definitive evidence proving so?"
"Well, I mean intuitively it's obvious."
"It might seem intuitive to you, but we can't accept that as sufficient evidence. According to the calculators this would be... maybe 3 microbits, plus or minus 4 microbits. You were raised in a culture that heavily encouraged said intuitions. The more local culture advocates for something, the less credence we can apply. We've also talked to teams of Anthropologists, and apparently intuitions between cultures around this topic are highly sporadic. We've initiated plans to pay small villages to adopt randomly generated cultures in order to measure the intuitions of children raised under said cultures, but that will take a while."
"Our country was founded on philosophical principles, you can't question the basic propositions of this country."
"Contractually speaking, those foundations are some of the first things we need to question. The bits simply don't add up in our calculations. We formally agreed to have standards for correctness, and we, simply put, don't have sufficient evidence when using reasonable standards. If you wanted ethical or metaphysical questions to be accepted at far lower epistemic standards, there should have been a few clauses in the contract specifying those details."
"Okay, so... so... just what does this mean going forward? What impact will this have for our legislation?"
"We weren't really tasked to answer that question, but we've been analyzing the last 500 pieces of legislation and on basic review, zero of them would have met basic accuracy criteria. If dramatic measures were taken to reduce the number of claims in them and make them more modest, then, I believe... zero would have met the basic accuracy criteria."
"But all of this is just recommendation, I assume? This... it can't be binding.... How do we get around this? Maybe we could turn your ideas into recommendations, and have a different committee figure out the next steps."
"Well, I'm afraid that the rules of Order 14002 specifically state that the standards generated from Order 14002 must be used if ever removing or modifying the rules of Order 14002. So you could try to overturn it, but you'll need a mightily impressive defense of your reasoning. According to our estimates... there is an exceedingly low chance of your administration succeeding."
"I'm confused. Please re-explain all of that, tell it to me like I'm 10."
"Okay, I will summarize. For years, the United States Government has been feigning dramatic overconfidence to ram bills past the legislature and the American public. Not just bills, really, but all actions in general. Basically all of it is based on a series of wildly speculative accusations, not that much different from arguing based on beliefs in the daily emotional states of the god Hephaestus. In their defense, most other groups were much worse.
A few years ago, the previous administration signed the order to prevent Congress from passing laws without relatively high standards for justification. What they didn't realize is that Congress was previously using incredibly low standards of justification. Not just Congress but the entire American and Global system; on inspection it's all quite terrible. I assume that the administration expected the gatekeepers to be some political pushover, but, for some reason, they chose us.
We, a small think-tank made up of two Ancient Cynicism scholars, have extensive legal obligation to report the absolute truth as we see it. The truth as we see it, will feed up to the to-be-formed Council of Accuracy and Validity, starting next year. At that point, unless things change around a whole lot, and we really mean a whole lot, we expect that the amount of new legislation that is possible to be passed is exactly zero."
"So you're saying we're fucked."
"On what kind of epistemic standard would you like me to answer that question with?"
"So we can't pass anything? Our government will stop making new bills?"
"Probably, for 5 years."
"And what happens in 5 years?"
"Well, that's when clause A43 initiates. Clause A43 states that after a 5 years leeway period, previously passed laws will be considered for similar standards, and a formal process will be undergone to undo bills that don't pass it. Executive Order 14002 is excepted of course."
"I'm going to need to talk this over with a few other people at the White House."
"Understood."
"Is there anything else?"
"Well, I did want to run some... proposals past you. I think we may be able to find some solutions, but they will be expensive and take a while."
"Let's set up another meeting then."
A few days later
"Thanks for agreeing to this meeting, let's get started."
"So, following up with our last meeting, the situation now is a bit of a mess. Starting in a few months, new legislation will need to pass some fairly strict standards of evidence to be passed. This is a challenge because the previous and current standards are, in comparison, barely existent. This will impact new legislation soon, and almost all existing legislation in 5 years."
"Yes, yes... so, what's the ask? Are you requesting another $20 Million?"
"I'm afraid you may not appreciate the scale we are dealing with.
Let me... try to explain. Are you familiar with the new field of intellectual information economics?"
"Intellectual information economics?"
"It's quite new. Intellectual information economics is really a natural extension of Information Economics, but applied to economic decisions around making progress on issues surrounding intellectual development."
"That sounds ridiculous, intellectuals are all over the place, you can't just make it into a science."
"If you sacrifice some precision you can come up with estimations that are predictive enough to be useful. It's not very certain, but it's good enough for high-level decision making.
"I'm skeptical."
"I'll explain how it works. The first challenge is to measure the scope of the task at hand. We've made a preliminary map of a sample of the space of premises necessary to verify the current legislation and used it to estimate the total."
(Pulls up network diagram of such premises.)
"As you can see, we've ordered things into claims that are relatively easy to be verified on the right, and this cluster of metaphysics on the bottom left. The colors of the dots indicate the magnitude of the certainty we have on them, and the size indicates the relative importance in the network."
"There's a lot of white dots here."
"Yes, there's a lot of work to do. We can use this network to estimate the Expected Total Uncorrelated Information Potential. The total seems to be something like 18 gigabits plus or minus 1.4 orders of magnitude. Of course, this isn't actually possible to obtain with current limitations of time and space. There are many questions we doubt we can ever know the answers to, in the next few billion years. But we think that if we can make it to just... 150 megabits, we have a shot at hitting a threshold necessary to pass potential, well-written laws.
Now, in order to get to 150 megabits of designated marginal certainty, we would need to expend a considerable number of effort. What we need to do here is to make considerable advances in philosophy and world knowledge. "
"So we hire the best Academics? We're the United States, we have access to the very best."
"It's not going to be enough. we've been evaluating current government efforts and possible government efforts. If we hypothetically put together the total efforts of the CIA, NSA, Intelligence committees, research committees, DARPA, IARPA, RAND foundation, and all of our other think tanks, for a total of 10 years, we think we could get to.. " (checks papers)... "120 kilobits, plus or minus 2.3 orders of magnitude. If we expanded capabilities to include absolutely all of Silicon Valley and the top Intellectuals from Europe and South America, we could get to around 215 kilobits."
"I thought you said you have a solution."
"We may. You see, the above calculations assume that fundamental theory, tools, culture, coordination, and research techniques stay constant. On inspection it's possible these could get improve dramatically. It's not a sure bet by any means, but at least there's some way for the math to work out. It's a possibility."
"Go on..."
"To be honest, when we began inspecting things we were expecting a more efficient market, so to speak. It's not exactly like things in this area are efficiently run right now. Contemporary scientific practices don't seem at all optimized for useful scientific progress. Philosophy departments generally don't seem to be trying to solve the sorts of questions we need solved. Intelligence divisions use still methods from the 70s, it's like they haven't noticed Tetlock. We can also change hiring policies for Government roles, currently we are losing many of the best people to industry and abroad.
So we can fix the obvious things, but that only gets us so far. Maybe 2 or 4 orders of magnitude gain in research efficiency.
Research gets diminishing returns, so inputs scale steeply sublinearly with outputs. In order to make it 18 gigabits, we're going to need at least 4 to 10 orders of magnitude more productivity per unit resource. So right now we have to find 2 to 7 orders or magnitude somewhere.
This gets tricky but we have ideas. The silver bullet, if there is one, is in Artificial Intelligence. Sadly it's not really one single silver bullet, but rather more like some alien life form that feeds off a complex infrastructure. Assuming advances in ML happen, and that's a big assumption, we figure we can give us a few orders of magnitude. But we need to know how to use it.
"
This orange dot refers to the simulation hypothesis. The color refers to "
We did a test run on 5 randomly sampled narrow questions in
"
Conceptual Base
Estimation Engines
Naive Rationalism, Anti-Rationalism, and Mature Rationalism
Epistemics · Nov 2020 · 514 words
Naive Rationalism
By “Naive Rationalism”, I am referring to a long line of thinking that was particularly notable in the Enlightenment but has kept with us. It sometimes goes by the names of “Modern Thought”, “High Modernity”, or “Rationalism.”
Anti-Rationalism
By this, I mean schools of thought that primarily counter those of naive rationalism. These kinds of thinking were popular in Romantic Philosophy, Continental Philosophy, and Post-Modern Philosophy. The Counter-Enlightenment is perhaps the most obvious example. https://en.wikipedia.org/wiki/Counter-Enlightenment
Mature Rationalism
By this, I mean our current best understandings of how to successfully continue the “rationalist project.” This is the current best practices in the EA/rationalist communities.
| Naive Rationalism / Modern Thought | Anti-rationalism | Mature Rationalism |
|---|
| Expected Value Calculations | Independent expected value estimates should be used to decide all things. | EV estimates are totally missing the point. You should go with your gut. | Most EV estimates are highly sensitive to sensitive parameters. They need to be used with caution and ideally created by multiple people independently with lots of verification to have much credibility. |
| Scientific findings with high P-values | Science is great as long as the P-values are high. | Quantitative science misses the point. All evaluation must be qualitative. | P-values are a very crude approximation but have a signal. They should ideally be used with care and supplemented with other measures. |
| Randomized Controlled Trials | If interventions have positive RCTs they are good, and if they don’t, they aren’t. | | |
| Quantitative Measurement | Quantitative measurement should be used for all things all the time. An organization should estimate the straightforward things and use that for decision making. | Quantitative measurement always ignores what really matters. We should instead depend on personal intuition on all of these things. | |
| Qualitative Evaluations | Where quantitative measures don’t apply, we can make simple rubrics and have those be used for everything else. | | |
| Ontology | Things have Aristotelian Ideals and we try to name things accordingly. | Naming is all useless. It’s a fraud. Nothing really exists. | Names are pragmatic to help people refer to similar things, even if there aren’t external reasons to do so. |
| Central Planning | A centrally coordinated economy seems ideal, as the government could best control things. | The government can’t be trusted at all. We need anarchy. | The government can do some things okay, but corporations and other groups are better at other things. |
| Morality | There’s one true morality and it’s fairly simple. | There’s no morality. Everything is relative. We can make no statements that hold about morality. | Morality seems complicated. It seems like there are some principles that are safe. Even when moral principles aren’t sure, we can use reasoning under uncertainty to make safe bets. |
| Rational Agents | Humans ought to behave like Von Neumann rational agents. Where they don’t the humans are wrong. | There is no such thing as “ought”. It’s all relative. | The Von Neumann model is highly simplistic. There is hypothetically a more complete model that could be used to help humans optimize their best decisions. |
Comments from Nuño Sempere
Restored with permission (Nuño's comments, with Ozzie's replies).
On “Aristotelian Ideals”:
Nuño Sempere: Platonic Ideals, Aristotelian Categories/Forms
Ozzie Gooen: good point, thanks!
On “There is no such thing as “ought””:
Nuño Sempere: I wouldn't put Wittgenstein with the anti-rationalists, but he's the person I associate most strongly with this position.
Ozzie Gooen: He's a fun one. I think the anti-rationalists have taken inspiration from his ideas and run with them. Also, in some ways, he's exactly an anti-rationalist in the sense that he made a fairly complete attack on rationalist ideals. He came from the rationalist school of thought, but arguably changed from that.
Evaluations: Pros & Cons
EA & Eval · Nov 2020 · 1,081 words
AJoys and Negatives of Evaluations
Systematized Evaluations as a Rationality Power Tool
Systematized evaluation procedures aren't generally considered an exciting topic, but it should be clear that they are an important one.
Evaluations and Signaling
In cases where there's a lot of unnecessarily costly signaling happening, evaluation systems can be an answer. Costly signaling is a sign that there aren't existing quality evaluation systems in place; if there were, it's not clear how signaling would be useful.
Athletes don't spend much time advertising their quality. Instead they focus on doing well. If a young athlete gave long interviews or wrote a series of articles about what makes them great, I don't think this would convince coaches much. It's so incredibly easy to demonstrate their quality in simple tests. Now we have comprehensive and systematized Sabermetrics to calculate specific aggregates of quantitative performance measures to make hiring decisions, as described in Moneyball). These metrics don't bother analyzing how well players argue for their quality, they just look at the stats. Players in such a system are incentivized not to signal but to perform, the system is rather aligned.
Many software engineers barely have resumes. If they're good it's often evident by rather short interviews. Facebook has been known to encourage people to drop out before finishing college. Compare this with some Intellectuals, who seem to spend a considerable amount of time detailing their awards and recognitions in long CVs, even publicly pronouncing these recognitions at the beginnings of talks.
Simple objective and quantitative measures are ideal and preferable. We can repeatedly measure the karats of gold, the population of a country, the total profit of a company. But many important things aren't suited to simple objective and quantitative measures. There's no one number for how good an employee is or how well reasoned a book is. For things like these we need some subjective and often qualitative measures. This can be somewhat arbitrary and time intensive, but it's often the only serious option on the table. The question is often not "should we use systematic evaluations?" but rather, "what should our systematic evaluation systems be?"
Evaluation Agencies and Power
Subjective and qualitative evaluations in particular require a fair amount of coordination. There's a lot of human work to coordinate and pay for. Often this is easiest with one agency in charge, but centralized power can be corruptible. Power can breed more power and unchecked power can lead to big problems.
Evaluation bodies tend to have brands that scream out, "We're authoritative, you can trust us!" Often there doesn't seem to be much more to these brands really. I often don't see public concerns or discussions about quality from these organizations, which is interesting as it is insanely difficult to actually do a good job. I haven't yet seen an award ceremony include details of the potential problems of the award selection process.
If I ever were to have an award agency, I'd want to name it something like, "The highly uncertain best guesses of X." Perhaps this is one reason I've never had an awards agency.
For example, take courts, with some of the most over-the-top authoritatively-branded buildings out there. The histories of courts are filled with challenges and the results are often fairly random, but you wouldn't have any idea looking at them. Courts do lots of marketing, it's just all spent on architecture.

Why is authoritativeness so important? Given that evaluation bodies focus on evaluations, they are listened to about as much as people respect their evaluations. Their power is proportional to their respect among powerful actors.
Evaluative authoritativeness is beneficial to those ranked highly. If you represent a top rated product on Consumer Reports, you'd prefer that people trust Consumer Reports. This means that those ranked highly will be inclined to "go along with it" or reinforce the authority of the evaluation agency. The Princeton Review giving good scores to Harvard and Stanford in part helps Harvard and Stanford keep their prestige, and then Harvard and Stanford (the most prestigious schools) can give back by being positive about the Princeton Review. Everyone at the top does well when The Princeton Review becomes more reputable, so the groups in power help make sure that happens. No one (in power) wants to see much criticism of The Princeton Review.
A lighter example would be the speeches at the ends of award ceremonies. The winners have obvious incentive to pretend that the awards process was respectful. Imagine how odd it would be for a Nobel Prize winner to spend resulting interview time detailing the faults of the Nobel Prize selection process. The losers get less attention so have trouble complaining (plus, they seem like sore losers when they do.)
I'm sure norms around respect and reciprocity also have to do with it, but this is a complicating factor more than an altruistic one. If you were to attend a prestigious ceremony and later insult the organizers, you'd be in essence insulting everyone who supported the organizers, whether they did so for valid reasons or selfish ones. The fancy parties hosted by awards agencies for top participants come act a lot like bribes.
So you can get nasty cycles where evaluation agencies (and evaluation systems, in general) reinforce their own authority over time. They help make specific actors powerful, and those actors are incentivized to further empower the agencies.
Sometimes broad consensus is even more important than evaluation quality. Perhaps it's very important that there's consensus that one Presidential candidate fairly won; more important than if they did actually fairly win.
Interestingly, there seems to be very little in terms of evaluator evaluations. My guess is that the evaluator bodies really like being on the top of the proverbial food chain, for one. Not such a fan of their authority being questioned. Add the fact that "evaluation evaluations" may seem pretty abstract to people. But if we think that evaluations are valuable and important, it seems particularly important to evaluate the evaluators. Evaluators should be subject to the most evaluation. If we make a mistake there, this mistake will cascade to what could be many other decisions.
The US FDA reviews (a kind of evaluation) food and medicine. Academic Journal administrators select and organize and peer review for their respectful journals. The Oscars
Criticize this post
EA & Eval · Nov 2020 · 4,628 words
Criticize This Post
I think the Effective Altruist community and research organizations, particularly around meta and long-termism, are fairly early with regard to methods of public feedback, evaluation, and candor. I believe this is an area people should pay attention to and that there are likely significant effective gains to be made here going forward.
To be clear I think many other groups are also poor here and often worse. Much of this post could apply equally well outside EA. But some groups (entrepreneurs, top businesses, effective scientific institutions) are better. And I think it might be wise to aim much further than any existing groups as a 10 to 100 year goal.
This post is very much a messy exploration, think of it as a collection of quick rants rather than a polished essay. I budgeted a day or two and took a week. I’d love to attempt a full rewrite or make it into a series, but I really don’t have the time now for doing so. Feel free to ignore this or do a quick skim.
Note: this post assumes a fair amount of background knowledge of the Effective Altruist community and culture. It's based primarily on personal accounts and discussions, from my history of being around the community for the last several years.
Effective Altruism (2020), Criticism, and Feedback
On the surface, it may seem that Effective Altruists should be at the cutting edge in terms of evaluating their work and being candid about disagreements. I think in practice we have a fair way to go. I'm interested in working to help improve things and am curious to get other thoughts on the topic.
The Effective Altruism movement largely grew around GiveWell, which specialized in evaluating the effectiveness of nonprofits. The old argument was that nonprofits couldn't be fairly evaluated between cause areas or that nonprofit work was simply too complicated to understand quantitatively. The GiveWell approach looked to the critics as an incredibly arrogant endeavor, but now is recognized at least within the community as having done a fairly good job, especially compared to what had come before.
So it's frustrating that many of the new high-profile cause areas seem almost evaluation-free. There is no GiveWell or Animal Charity Evaluators for longtermist or meta nonprofits. One reason for this is that there's been a shift towards longtermism, where it's substantially more difficult to estimate effectiveness. Another is that these are relatively new areas. But these excuses obviously shouldn't mean a free pass.
I think one thing that's happened is that the longtermist / meta community is almost all friends with one another. It's easy to rank organizations that neither you nor most of your readers will ever personally know. It's much more awkward when you have to call out friends for doing a bad job, knowing it means they might lose their jobs because of it. It can be personally ruinous if it's likely that you might want to work for one of the organizations you give a bad score to down the line, or that someone you give a bad score to might be an important Board member one day.
I know this in large part because I'm friends with many people in the community and have experienced this. I like the community a whole lot and have an absolute ton of respect for them. I've worked at 80,000 Hours in 2014, have attended something like five Effective Altruism Global events, and have most recently worked at FHI for two years in the Research Scholars Program.
I've previously asked a few relevant figures if they'd be up for publicly evaluating long-termist/meta work, and got some rather hesitant responses. You might notice that many of the public research analyses emphasize good work much more than poor work. It's much easier politically to highlight the good things than the bad.
The existing solution I see is background chatter around funders. Organizations that do work that seems sketchy get flagged and that gets communicated fairly haphazardly between people. This is a low cost strategy that's pragmatic for small setups but has a bunch of limitations. Organizations that are refused funding often have a very challenging time finding out why. They often continue to search for increasingly-distant funding sources, many of whom have not heard the rumors. Onlookers can't understand what's happening and might either fund poor organizations or worse, start poor organizations only to get rejected (or worse, accidentally funded) several years later.
I don't want to over-emphasize feedback on a per-organization level. There's also blog posts, articles, and cause areas. On articles, for example, a lot of content by smaller organizations is written without peer review. Even content written under peer review has problems, as modern peer review processes can be quite myopic in focus and restricting in formats.
I can point to my work as a case where feedback has been challenging. I've found handfuls of people who can help review my Google Docs papers, but it's an ad-hoc process. Posts on LessWrong and the EA Forum don't really get comprehensive reviews. The karma system is a good start but does not replace a quality rubric and evaluation. Going up higher, I'm not sure who to go to to get the best feedback on how I'm doing as a whole, or how well a research agenda is doing. I don't want to produce a bad effort, I'd prefer that a quality system help tell me if my work is of high expected value or a net loss.
When I'm asked by young Effective Altruists how to get started with research, the best advice I can give them is often something like, "Try to post on the EA Forum and cross your fingers you'll get useful feedback."
So, to summarize, we don't have many public evaluations or feedback, and also have prosaic private feedback mechanisms.
Effective Altruism, Certainty, and Candor
Part of the issue feels like a cultural lack of candor.
Candid communication is not always enjoyable, especially for people not used to it. But a lack of candor can be stifling in the long run.
Candidness is one area where I feel the EA community could learn from the Rationalist/LessWrong community. The Rationalist community has a long history of attracting disagreeable people. For a while the comment threads were highly unpleasant with lots of over-the-top criticism. But over-the-top criticism is at least criticism, and things have gotten more friendly (though less critical). Many of the non-AI-safety writers seem to have very individualistic approaches and agendas.
My gut feeling is that the Effective Altruist community is more agreeable and conformist than the Rationalist community. This is beneficial for coordination. I'm sure it has helped speed up the time from someone joining the field fresh to them heading for a path to work at one of the most EA-reputable AI Safety organizations. Agreeable people tend to be good team members, as long as the ship is heading in the right direction.
For example, on the EA Forum, I've seen almost no serious feedback or criticism of the primary organizations (Open Phil, FHI, CEA, CSER, OpenAI etc.) It's like the main ideas and actions are going unchallenged. I've heard a fair amount of mumblings behind the scenes, but very little shown publicly or even presented to the relevant people. I'm guilty of this myself. I've noticed that it's particularly scary to speak up when there's a lack of precedent for it.[1]
When I see posts and writing of altruistic people I’m hesitant to provide criticism. There’s a culture of positivity on both LessWrong and the EA Forum (and most forums, to be fair). This is great in some ways but bad in others. Public & online criticism can be scary, especially because we don’t know who will be reading things and what possible future job opportunities are on the line. At the same time though, it’s really difficult to improve without real feedback. Also it would be useful common knowledge for people to know at least some of which posts and projects aren’t good and why that is the case. Negative case studies are often the best ones.
Effective Altruism Global
Let's use Effective Altruism Global as an example of a cultural point. I'm very thankful for EAG events (As noted, I've been to several), but I've been frustrated that they seemed to emphasize consensus over controversy. EAG presentations give an aura of authoritativeness. Presenters are (literally) put on a stage and introduced with glowing speeches. The opening and closing sessions are typically highly optimistic about Effective Altruism, and many of the talks seem a lot like they are standing in as "the definitive take on X.” There are sometimes talks about possible disagreements, but these are rather few, and it's not always clarified that the disagreements are substantial. I recognize that debates have a lot of problems, but I think I'd be more excited about what would come out of an "EA Cause Area Debate" or similar than the marginal presentation. There could be a lot more emphasis on controversy and ways that the respected actors are wrong.
My read is that one of the main goals of EAG is to get newcomers up to speed with the EA expert understanding of things. There are very valid reasons for this. The majority of people I talk to that have criticisms of EA are people who haven't thought about the issue much. On the margin, I'd expect their beliefs would be better if they accepted the primary results of EA investigation. But there are downsides to a confident image as well. It's easy to give the impression that we're far more sure than we actually are. I've seen this happen several times and been complained about a lot in the background. See the Earning to Give controversy for perhaps the clearest example. And more important we really would benefit from people who question the wrong things. I'm sure we're making lots of mistakes that aren't yet obvious.
I think one could often come away from existing EAG events thinking that all of Effective Altruists agree with one another. This is either very wrong, or we have a much bigger problem to worry about.
I’m not saying that EAG is worse than other conferences. I’m rather the kind that finds most similar conferences fairly insufferable. I would like for EA to find ways of presenting things better. It might be the case that because most conferences project plastic, uniform, proud, and overoptimistic images of themselves, ones that don’t would be seen as strange and irrelevant. Perhaps there is little such thing as a big conference that emphasizes humility, doubt, and self-reflection. But I’m hopeful. It might be easier now that many of the EAG conferences have become smaller and some aimed more at the most experienced people, as opposed to trying to attract newcomers.
Candidness between cultures
One cause of the culture could be that Effective Altruism is attempting to be very encompassing to get a diverse set of skills. As such one might expect the culture to approximate the average of the cultures that it draws from. It's already highly selective for talents, there's not much room to be additionally selective for candor. I'm used to startup culture, so in comparison, the "average of intelligent groups in Western Nations" is not particularly good at being honest and candid. This might be what's common, but that doesn't make it good enough.
A more encompassing issue is just that all existing communities have limitations regarding candidness. I don’t believe we have any examples of groups that are as strong as what we would ideally want. Startup culture is good in some tactical areas but quite poor in moral ones. Bridgewater culture seems great for business performance, but I doubt it has escaped the confines of all Western biases and honesty limitations. If you were to go back in time, all civilizations seemed to have some core unquestionable assumptions and honesty norms common among all subcultures.
At some point you enter uncharted territory. I imagine that to do this well would require a fair amount of innovation and consideration. This is the kind of challenge that could take a while. Perhaps one would desire some serious research efforts to navigate and test possible cultural changes. I imagine that big gains would take many years, perhaps 5 to 100 or so.
Counter Examples
I have noticed Effective Altruists being highly candid or critical in a few areas:
- Criticisms against Effective Altruism
- Proposals of new cause areas
- Research from people new to Effective Altruism, often who aren't used to the writing style and evidential standards
- Culture war issues
I have mixed feelings about the criticized areas. I think the criticism is often warranted, though I think there's room to improve with regards to empathy and respect in how it's delivered. I hear that many other altruists have had bad experiences engaging Effective Altruists and gotten a sour taste for the movement. But perhaps the main thing here is that this is an indication that critique is very possible, it just doesn't seem to be applied much to some of the most core and important topics.
It should be clear that a community being critical about opposing beliefs does not gain it many points in being critical for self correctness. Every intense community is critical about opposing beliefs. Christians have many fierce debaters that have stood ground against atheists in argument. I’m sure there are many intelligent Scientologists and other cult members who are exceedingly clever in defending their held orthodoxies. So it’s interesting how good communities can be at exploring arguments against other groups while at the same time refusing to apply similar measures to their own, often exceedingly dubious claims. Really, communities that are good at attacking criticism without applying self reflection aren’t ineffective, they can be actively dangerous.
Candorand certainty
If the key decisions Effective Altruists make were obvious, then candor wouldn’t be as important. However, I think the decisions are clearly not. The solution space of “all of the ways to help the world” remains vast and perplexing.
The flip side to candor is certainty. Candor that opposes things that are certain is often paranoia. It’s counterproductive to have people doubting things that are actually true. If you have to rally the troops to defeat actual Nazis, you don’t want your people to be spending their efforts on metaphysical definitions that preclude the meaning of war. In business there’s a phrase for such problems; disagree and commit. At some point a decision has to be made, after which it isn’t useful to debate it. What then matters is execution.
A lot of the main Effective Altruist beliefs are clearly not certain. We have lots of time to change things going forward. So we rarely need to disagree and commit.
It’s useful for individual organizations to make fixed assumptions, but this applies less to the EA community. For example, I’m happy that the Against Malaria Foundation doesn’t spend resources figuring out if global welfare is cost effective vs. Artificial Intelligence safety work, but I very much want other groups to be questioning this.
A Simple Rubric
We can try inventing a rubric to clarify where communities or organizations stand in these areas. Here’s a simple breakdown that could do the job for now. I think of things as split between “processes” and “systems”. Processes are procedures that ideally have operationalizations and regular implementations. Systems refer more to all-encompassing measures of culture and knowledge.
Processes: Internal Feedback, External Feedback, and MentorshipThese all have similar purposes but different methods. I think they are self descriptive. Mentorship is arguably a type of internal feedback but was broken out as it’s typically distinct. Mentorship could include things like line managers; any kind of people who check in with people on a recurring basis and give them advice to improve.Prioritization AbilitiesHow well do all levels of a community prioritize, especially around company-level strategic factors? Are priorities both correct and clear to all relevant members?
Cultural CandidnessIs candid communication common? Are people who use it actively rewarded when it turns out to be beneficial?
Decentralized Justified Trust“Justified Trust” means that individuals and organizations are both trusted and also deserve that trust. Decentralized means that this is widely spread out. If some leaders are trusted more than they should be that’s bad, if newer members aren’t trusted enough that’s also bad.
Here are my quick intuitive ratings for where EA stands, focussing on Longtermist (includes AI safety and Bio) and meta cause areas. This is a hard rubric for modern communities; top hedge funds and tech companies would probably get a lot of 4s and a 5 or two, most communities I can think of would mostly get 1s and 2s. Also, note that there is some selection effect in regard to the rubric. There are other equally important rubrics I could have imagined where the Effective Altruist community is doing quite well. I was focussed on this one because I wanted to write about an area where I was excited to see improvement.
Feedback, Candidness, and Forecasting
If you’re familiar with some of my recent work, you might be wondering where this topic fits in. I’ll briefly go over its relevance to forecasting platforms.
A lot of potential forecasting value is bottlenecked by the acceptable candidness or honesty of a community. Many of the benefits of forecasting could come from delivering evaluations. See the Prediction-Evaluation post for details here. Unfortunately in current cultures honest and impactful evaluations are very hard to publish without deeply upsetting some people and getting a lot of pushback.
One of the key reasons why internal forecasting setups haven’t succeeded in total seems because of their transparency. Project managers typically don’t seem to want information on the expectation of their success (of project success or timelines), if it means the information will also be public to others. It’s far more convenient to pretend things are going well and make up excuses last minute for why you couldn’t have seen failure coming. A difference transparency challenge is that the introduction of forecasting platforms to respected analysts is often met with trepidation. They are already respected, so they only have to lose respect by honestly tracking their accuracy. This is one reason why the Expert Political Judgement tests were done anonymously. So forecasting platforms require levels of transparency to operate that make traditional analysts uncomfortable, and when they are used they create transparency in areas where often leaders don’t want it.
New evaluation measures in general are disliked by people who don’t do well on them, so they are very difficult to introduce and substantially change for this reason. Top scientists (by citation count) don’t like altmetrics, popular hospitals don’t like price transparency.
Regarding Effective Altruism, we could begin to estimate the value of all EA projects and make that public. We could have estimates for how valuable each organization is at each point in time. We could have measures for our expectations of possible job candidates and identify promising potential that naive measures might have missed. This could be incredibly valuable but it would probably make some people uncomfortable or worse. If you identify that an organization doesn’t seem very beneficial, that could lead to that organization to stop getting funding and talent. Hopefully if there are bad projects or organizations they would get fewer resources, but someone would feel worse for it.
The few of us playing with these ideas can use ourselves as guinea pigs. Nuño Sempere recently scored my work. I’d love to make a lot more about myself and the organization more transparent, but am reluctant to be particularly radical.
Speaking more generally, within our culture (both EA culture and Western culture) it’s expected that we keep a lot of things private. If one person reveals their mental health issues publicly, it will be seen negatively for potential collaborators, even if all things considered the person isn’t in particularly bad shape. I noticed this in the startup scene where founders would produce highly inflated images of their progress. This happens at a systematic level, so any new founder that doesn’t is considered particularly unpromising. Even if a Venture Capitalist appreciates the honesty, they will be suspicious that potential hires and future potential Venture Capitalists will not.
In a world where people and organizations promote highly filtered and overconfident information about themselves, radicals who try to be honest can look quite poor by comparison. And in this world, evaluations that try to be honest can dramatically interfere with the convenient self-images so carefully put together.
So when designing a community wide forecasting/evaluation system, we really need to decide just how transparent and honest people are willing to be, and if there are measures that could make such honesty more tolerable.
Opt-in Candidness Invitation
Without a culture that actively encourages candid critiques it can be risky to begin. However, individuals or organizations can make things easier by publicly asking for criticism. Consider this section an open invitation to be critical of this post and future posts I work on. Go crazy, write a scathing critique. Honestly I would really appreciate it, I'm sure that I'm making a lot of mistakes and overlooking key points. Here's an admonymous link if you want.
I would appreciate it if you phrased things respectfully, but where there are trade-offs, I'd appreciate honesty more than niceness.
What do we want for Effective Altruism?
I think that a lot of key community members aren't too thrilled with the current situation. The EA community could be doing a lot worse, but it could also be doing a lot better. I have very high hopes for the community in the long term and think that doing better on these measures might be one of the most powerful instruments for substantial long term impact.
There are a bunch of changes we could make, but they might be either difficult or uncomfortable. I have a list of proposed methods for improvement and am actively working on some of them. However, to not anchor the community, I'm curious to get people's responses first. I'll write another post with my thoughts here later.
Other Reading
I wanted to highlight several other posts on this topic, or posts that either demonstrate the issue or I think have done a good job at being particularly candid.
Asking for advice
Does Economic History Point Toward a Singularity?
The case of the missing cause prioritisation research
Why those who care about catastrophic and existential risk should care about autonomous weapons
Thoughts on whether we're living at the most influential time in history
Avoiding Munich's Mistakes: Advice for CEA and Local Groups
When does it make sense to support/oppose political candidates on EA grounds?
Some potential dangers of rationality training
What are the key ongoing debates in EA? - EA Forum
Comments from Nuño Sempere
Restored with permission (Nuño's comments, with Ozzie's replies).
On “.”:
Nuño Sempere: Also, it makes you more vulnerable if anyone decides to hunt for dirt on the EA community
[2 comments by other collaborators omitted]
On “My read is that one of the main goals of EAG is to get newcomers up to speed with the EA expert understanding of things”:
Nuño Sempere: Unclear if true
On “If one person reveals their mental health issues publicly, it will be seen negatively for potential collaborators”:
Nuño Sempere: Depends on how much status the person had in the first place. When Rob Wiblin talks about how he takes anti-depressants, he gets some bonus points.
Ozzie Gooen: It's complicated. Might discuss edge cases.
On “I noticed this in the startup scene”:
Nuño Sempere: Yes, but you were talking about EA culture and Western culture, and the whole point is about EA, so this example doesn't really contribute to the point you're making. It would if you had an equivalent EA example
On “radicals who try to be honest can look quite poor by comparison”:
Nuño Sempere: Not necessarily, because then honesty is a strong signal of quality "I don't have to be overconfident because I am so great." / countersignaling.
Ozzie Gooen: I didn't mean this absolutely. If I were to provide clarifications on all edge cases this would have been much, much longer. Finding the balance is difficult.
On “The few of us playing with these ideas can use ourselves as guinea pigs. Nuño Sempere recently scored my work. I’d love to make a lot more about myself and the…”:
Nuño Sempere: This seems too self-congratulatory
Ozzie Gooen: I imagine you mean just the first paragraph here? I don't think I follow if you are referring to the entire section.
On “Here's an admonymous link if you want.”:
Nuño Sempere: I think admonymous links are a great social mechanism, because they align virtue signalling with actually creating mechanisms to give feedback. Might be be worth explicitly pointing that out.
Decentralization, Candidness, and Privacy: Pick Two
EA & Eval · Dec 2020 · 1,282 words
Introduction
I’m frustrated by the lack of candidness around Effective Altruist organizations and individuals. Upon reflection I think this may in large part because of community values of decentralization and privacy. It could be that decentralization and privacy can’t exist with candidness, and we will need to decide on some tradeoff between the three.
There are many stories of Steve Jobs being extremely candid with employees. Similar is true for most top tech executives and many well performing companies. Candidness often comes with overconfidence and occasional rudeness, but it seems to have a good track record of getting results (especially when it can be done gracefully).
It even comes up in places you may not expect it. It seems like Seinfeld was great in part because Larry David was brutal at filtering mediocre comedy ideas.[1] Anna Wintour was so brutal she inspired a movie), though I might recommend the documentary.
So theoretically we could just find or promote our own Steve Jobs or Anna Wintour or two to call out all of their thoughts on mediocre Effective Altruist nonprofits and ideas, but in practice I don’t think this will be easy.
One key reason why Steve Jobs and Anna Wintour could be candid is because they were talking privately. It’s one thing to be mean to someone in a room of three, it’s another to do it online for all of their future potential employers and collaborators to see. Public negative speaking about an employee makes everyone look bad, even if it’s warranted. I’m sure that if Steve Jobs couldn’t have privacy he’d give much less criticism, and Apple would have been worse off for it.[2]
Right now Effective Altruism meta and longtermist nonprofits currently have a few norms:
- Organizations are very small and relatively independent from each other.
- If there is important multi-organization discussion, it is made transparent (posts on the EA Forum or on organization websites).
- Discussion should be highly respectful to individuals and organizations. The privacy of these agents should be respected, so important negative information shouldn’t be posted publicly.
All of these are quite reasonable on their own, but together create some challenges. It makes any sort of candid communication very difficult.
Decentralization, Candidness, and Privacy
I think that communities can choose two, and only two, of the following: decentralization, candidness, and privacy. Achieving all three seems nearly impossible to me with current technology and culture.
Decentralization
Power is distributed between agents.
Candidness
Important honest and negative information is conveyed. This often means the faults of projects, organizations, and individuals.
Privacy
Candid information is not widely shared.
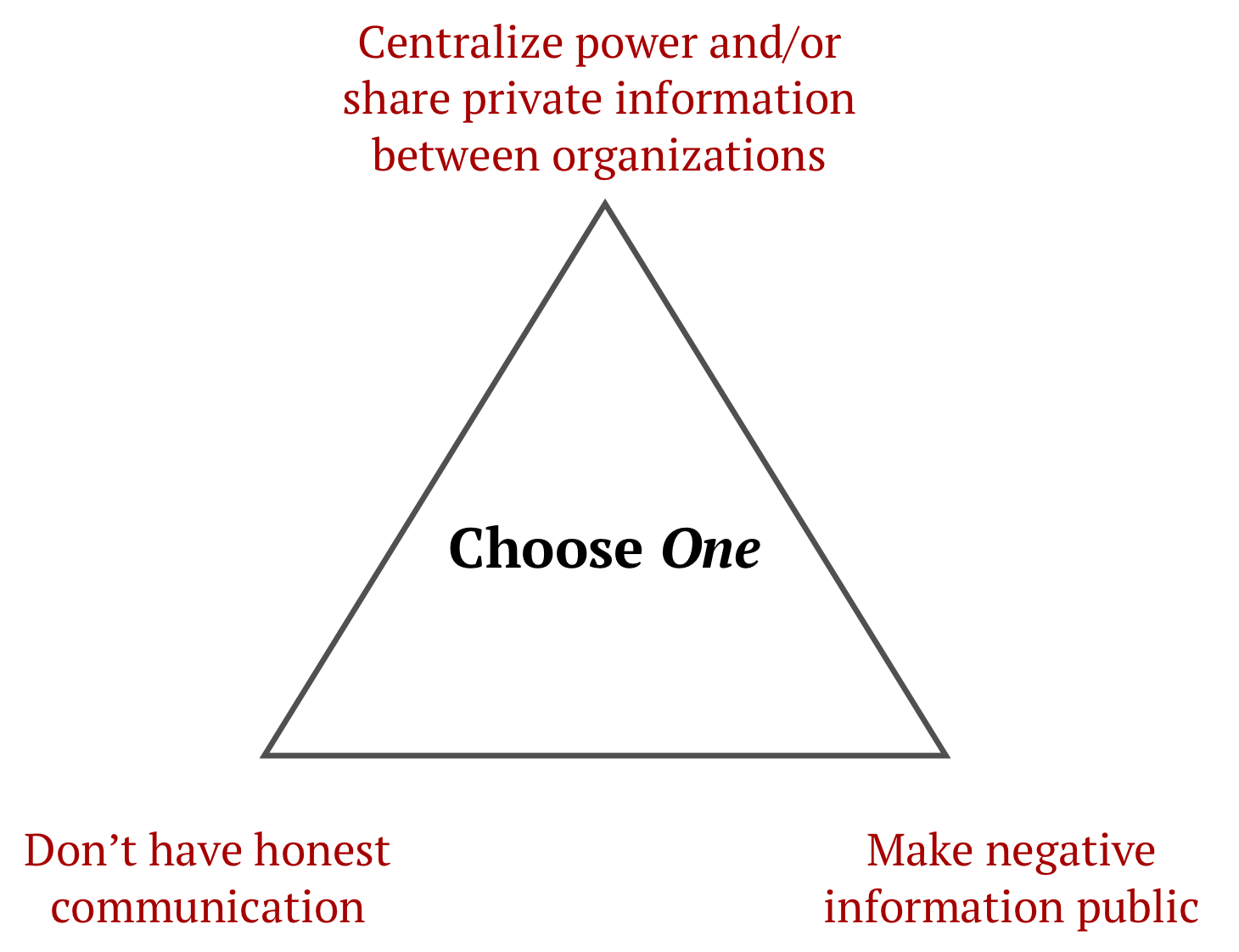
We can imagine what each choice of two looks like:
Decentralization & Privacy
Power is decentralized between a bunch of groups that are very polite to each other. If some of them start behaving or doing poorly, it takes a long time for anyone to notice, and much longer for it to be public knowledge. Because candidness isn’t public, there’s probably a fair amount of gossip to make sure that bad things are shared somehow.
Examples: Social groups, families, business events, nonprofit communities
Candidness & Privacy
Lots of criticism is given, but the necessary information is kept close to the few people at the centralization organizations that need it.
Examples: The insides of high performing companies, like Apple or Amazon.
Decentralization & Candiness
Decentralized candidness seems rare. Perhaps one key determinant is if important knowledge is fairly evident, even about those who do poorly.
Examples: Professional sports teams, competitive and simple businesses that compete on select metrics, comparisons of startups seeking venture capital.
What would a version of Effective Altruism look like in each one?
Decentralization & Privacy
I think this is basically the current situation.
Candidness & Privacy
Organizations would either merge together or there would be some powerful communication network between organizations that was kept private from the public. Both setups would require a lot of coordination and the giving up of some independence.
Decentralization & Candiness
Effective Altruist organizations and individuals are expected to be honest and accepting of a whole lot of transparency, much more so than other organizations. Many of the negatives of both would be on full display, including the “dirty laundry” of organizations and the health problems of individuals. An analogy would be to expect the same amount of available public information as public sports figures and celebrities.
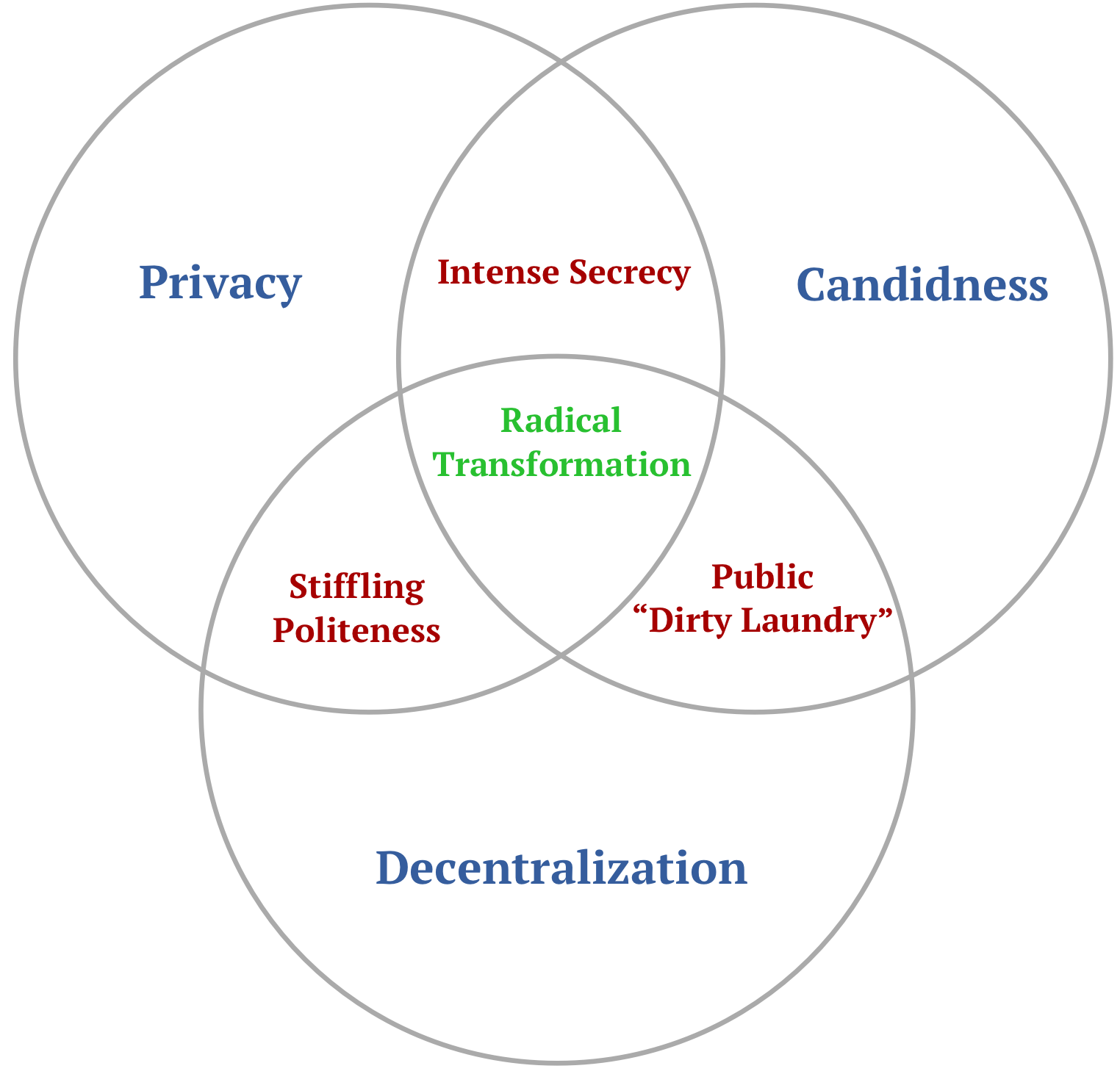
What would more intense candidness look like within Effective Altruism?
Projects
If a project has some substantial negatives, these would be evident, even if on the whole the project was decent and those negatives would be bad for publicity. Projects would be compared cross-organization. Many projects by new people would probably get very low scores, and this would be very evident.
Organizations
Organizations would be ranked with scorecards or similar. Organizations that seem very ineffective or harmful would be labeled as such in ways that all important decision makers would pay attention to. If things are decentralized, the “important decision makers” likely include anonymous donors, so this information would need to be public.
Individuals
It can take quite a lot of work to evaluate if someone will be a good employee. One might learn a lot about them over time, both by working with them and by hearing about them. Candidness about candidates means that the good and bad qualities (real or perceived) of candidates would be widely shared. Imagine per-person scorecards that rank people on many different qualities.
What do I think we should aim for?
My quick guess is that we’ll want sacrifices from both decentralization and from privacy, but around 3/4th from decentralization. One could imagine a new initiative that would provide honest assessments of projects, organizations, and individuals, but only share these with the most important decision makers.
I’d like to see experimentation with sacrifices of privacy. Perhaps a few individuals and organizations can experiment with extreme transparency. Maybe there should be monetary subsidization or similar for this kind of openness.
Key Questions Going Forward
- Does decentralization, candidness, and privacy really represent a trilemma?
- Is there a more useful model for understanding the tradeoffs between these?
- Where along the spectrum should we aim for?
- Can future technical or social technologies dramatically improve the Pareto frontier?
Related Work
Wikipedia has a nice page on Trilemmas. This post was originally inspired by the CAP theorem in computer science. When I was in college, a common phrase was, “grades, being social, sleep, pick two”.
The Zizek Trilemma was about loyalty, honesty, and intelligence. It was specific to Communist regimes, but seems somewhat similar to this one.
Most of the trilemmas I know of seem like crude simplifications. For example, the “grades/social/sleep” trilemma has been further broken up, and I imagine will eventually be made much more intricate. As such they can still be useful, but readers should keep in mind that they are discussing a map, not a territory.
[1] See this documentary, especially the bits from 4:35-5:54 and 15:53-17:27.
“He was solely focused on making a funny show. So that was what he saw and zeroed in on all week… and if things got in the way, he would bat them away ferociously.”
Arguably, Larry David was so unusually candid that he was able to turn his personality into its own 10-season comedy.
[2] Note this is the case if only one company couldn’t have privacy. If all organizations couldn’t have privacy when it came to criticism, I would think it would become much more culturally accepted to be candid publicly, but this would be a radical cultural change.
Different kinds of handcuffs
Culture · May 2021 · 2,544 words
Different Kinds of Proverbial Handcuffs

https://commons.wikimedia.org/wiki/File:Westgate_060.jpg
I consider golden handcuff to be an s-tier metaphor. It's straightforward, visual, simple, well known, and important.
The definition of golden handcuffs I'm interested in is that of trapping individuals into expectations of future income, making it painful to ever change to a lower-paying position. Theoretically, making more money should provide freedom, but in practice, many well-salaried employees take on debts and luxurious lifestyles that force them to keep on certain treadmills.
I've read that this is something that some financial institutions actively encourage. They intentionally encourage employees to partake in lifestyles that would be difficult to step down from.
So in the proverbial personal balance sheet, one would be deficient to only mention a high salary as a financial increase. At the end of the year, when a newly employed financial banker tallies up their effective income statement, they should include their salary, but also note the presence of their new handcuffs as well.
Golden handcuffs are a nice metaphor, but I find it frustratingly specific. I think we might as well extend this metaphor to a broader class of things that “incur some advantages, but also restrict one’s available actions”. Included below is a list of items that were particularly interesting to me. If you’re reading this and have ideas of others, I encourage you to leave them in the comments.
I see much of this work as discernment work around lock-in. Put differently, in the EA community I hear a lot of worries about “lock-in”, but haven’t seen many breakdowns or sub terminology.
Status/Prestige handcuffs
A person is respected in one area for a type of work. Any change would hazardise this. For example, a manager of 10 software engineers would feel uncomfortable transitioning into an ultimately better career track, if they would begin at the bottom of a different hierarchy. Similarly, a person might attend a prestigious University, and later only feel comfortable associating with others of similarly prestigious backgrounds.
Silicon handcuffs
A person or group becomes dependent on technology. (Sadly the obvious reference is controversial, so I recommend looking at What Technology Wants for a discussion of this.)
Intellectual handcuffs
A person gains specific interests and finds common topics, or discussions with more junior people, boring or repulsive. This leads them to an increasingly narrow set of possible friends.
Identity handcuffs
A person builds an identity around a particular way of understanding the world. They refuse to pursue work or activities that don’t match their intended identity. For example, someone becomes personally attached to journalism at age 10, and later refuses any other profession, even if much better ones for that person are available.
Domestication handcuffs
A person goes through a school system from an early age that makes them fearful of authority figures and fearful of rebelling or defecting against their peers. They might develop a deep seated dread of failure to complete bureaucratic assignments, for instance, through recurring nightmares of getting tested.
Ownership handcuffs
A person acquires stuff that requires space or maintenance. Perhaps they acquire a lot of furniture or a collection of animals. They develop emotional attachments to their things and would experience pain to leave any of it. As said in Fight Club, "The things you own end up owning you."
These sorts of handcuffs aren’t specific to people who spend a lot of money. Those who try not to are often ones who are the most hesitant to give things up.
Reciprocity handcuffsIt seems like it should be beneficial to give someone a gift. But in a culture that strongly enforces reciprocity, gifts come with obligations.
In my family, gifts are unilaterally planned. It would be calamitous if one party bought gifts but another didn’t. We used to have expensive Christmases, then we totally stopped, then we started again at a small scale and I’m closely monitoring possible risks of it growing again. Christmas and birthday gifts are our primary version of an iterated prisoner’s dilemma.Intentionally biasing gifts are often called bribes.
Media handcuffsMedia positions come with many sorts of handcuffs, in particular the status handcuffs mentioned above. But one particular one that worries me are the handcuffs of limiting communication. As one grows a diverse audience, they develop an increasingly long list of things they can’t publicly say without incurring some intense backlash. The worst case is an international political figure, who can say (and often think) almost nothing.
Not being able to say things is the first step towards not bothering to think things.
This sort of handcuff is evident in organizations that start out edgy and appeal to a small audience, then grow a larger audience, and then find that the resulting incentive gradient greatly discourages them from being able to be edgy.
Brand quality / reputation handcuffs (ceilings and floors)
Strong brands lead to many sorts of actions becoming costly. Weak brands allow flexibility of decisions, but can lock in quality ceilings that come with many other restrictions.
Brands and public images represent far more complexity than seems ideal. One problem is that most people have intense but limited understandings of brands. So they may regard Apple as “high quality”, instead of internalizing a quality breakdown of all of the distinct subparts of Apple.
Apple is an interesting example. They have a strong brand and a distant reach. But a valuable brand comes with similarly large risks and liabilities. If Apple released a mediocre product, that would likely harm its brand, even if the product would otherwise be beneficial to all involved. So there’s a large class of products that could be negative expected value for them to sell, even if development and production costs were hypothetically free. We can call this a quality floor.
A different example of a perceived quality floor would be in Economics. Journals have a high bar regarding specific expectations of quality, rigor, and content. For whatever reason, there are high expectations for mathematical rigor, but low ones for computer simulations. I’m sure there’s a ton of interesting and useful work that could be done if this bar would be modified.
Quality ceilings are based more on harder constraints. The best collaborators generally want to work with high quality people and under prestigious organizations. Companies with poor brands (meaning they are considered mediocre or morally harmful) have to pay substantial premiums for collaborators, if they can get them at all.
This means that many organizations have both a quality ceiling and a quality floor. There’s typically a strong potential employees they can’t access, and a low quality bar that they don’t want to touch.
Therefore, once a new organization is formed, it needs to think carefully about the quality level it can aim for. If the organization starts producing a lot of mediocre work to get started, it could lock itself into a low tier for the long term. But it could also set too high of a bar and exclude the majority of useful work.
Connoisseur handcuffs
Expertise often comes with emotional attachments, and these attachments have downsides. If you want to make a skilled programmer cry, don’t have them do yard work, instead have them fix bugs in a bloated PHP codebase.
Good chocolate might have ruined bad chocolate for me. Functional programming has ruined a lot of object oriented programming. I’ve prided myself for my aesthetic sense, but this seems to come from an added dread in many spaces, and an unease when I myself feel ugly or unfashionable.
It’s easy to mock the pretentious wine critic or spoiled child, but I think myself and most people I know of have these qualities, just in more socially ordinary ways. The downsides impact others, for sure, but also are considerable for oneself. I know programmers who have turned down large sets of promising jobs because they required them to program in ways that they personally found distasteful.
Planning handcuffs
Well crafted plans represent some of the most malicious traps to fall into. Planning can be brilliant if done well and appropriately managed, but often they are both done poorly and incur substantial emotional sacrifices when cancelled.
Extensive plans typically include several steps that have no payoff unless specific later steps are completed. Engaging in a long plan by definition is about dramatically constraining one’s future choices.
Complexity handcuffsComplexity normally requires maintenance. I’ve found that often this downside is typically underappreciated. Complexity here means a lot of things. It refers to:
- Complex codebases with lengthy and intricate interfaces.
- Extensive delegation to specific individuals based on rules; for example, having 10 people, each great at doing only one kind of task.
- A task management system with 150 particular tags and 10 status flags, and 25 administrators with different privileges.
- User interfaces that allow for 350 different features, on computers and mobile devices, in 10 different browsers, in dark and light color settings, with documentation and API access.
- Taxes and laws.
- Complex corporate and government relationships and dependencies.
- A large set of important ideas haphazardly spread out between five thousand blog posts with poetic names.
- An official or unofficial ontology with extensive but particular definitions.
One of the most common mistakes rookie software managers make is to push for more functionality than they should. The outcome is not only code debt, but design, product, and documentation debt, plus a requirement for never ending maintenance and upkeep. Products too intricate tend to collapse under their own weight.
A person, organization, or society that demands great complexity must set aside many of its resources to basic maintenance, and this could be dramatically limiting.
Venture capital handcuffs If you own a business, the moment you accept almost all types of investment, you begin a specific path of revenue optimization that’s difficult to get out of. If you accept Venture Capital investment and later decide to change your mind, you’ll have a lot of paperwork, many disappointed colleagues, and likely a substantial reputational hit to get through, in the least. This handcuff is well known, but I don’t think known enough.
Management handcuffsBeing a manager seems like it should be a very flexible position, but in practice, management can be a very constrained position. Having individuals one is in some control over for comes with a great deal of responsibility. Employees and volunteers need to be onboarded, trained, mentored, guided, and occasionally delicately removed. In my own experience, employees and consultants have taken a surprising continuous overhead. When I’m working with others, even just in a management position, it’s much more difficult to take serious time off to focus on specific things. This issue doesn’t just exist for management, it’s there for all colleagues that need to help out, as often responsibility is distributed. The Mythical Man-Month goes into detail on how adding new people to a software project often slows it down.
When one creates an organization and gains employees, it can be incredibly difficult for that person to leave. In most situations they either must find someone else competent at running the organization (which is either very difficult in large organizations, or often near impossible in small ones), or they have to disband the organization.
Association handcuffs
A person develops a negative association with something, making it much more difficult for them to engage with that thing in the future. For example, a society associates backpacks with children, and adults proceed to use much less convenient briefcases.
Publishing handcuffsThere are some restricting norms around public writing. I’m noticing them when writing this piece. Most readers seem to read and comment on pieces shortly after they get published. If considerable changes are made later, no one will be notified. At the same time, it feels very odd to publish different versions of the same post multiple times. So, once the first version is published, the author is limited from giving it another attempt.
This is particularly bad for new terminology. Once a term becomes widely known, it can be near impossible to modify.
One other hazard is that one person writing on a topic can close it off for future writers. One of the best ways to encourage someone to spend a lot of time on a topic is to allow them some easy wins to build a reputation on. An Academic with a small breakthrough early in their career might spend much of the rest of their career building on it, for a combination of reasons I assume to include buy-in and vanity.
This means that publishing original work can make continuations of such work harder, not easier. The corresponding ideal is to publish later and less frequently than otherwise.
Anti-handcuff Handcuffs(fear of commitment)
An intense aversion to acquiring restrictions is itself a restriction. A In doing so, they ironically close themselves off of many good opportunities. For example, dying is a substantial handcuff, but if one has too much fear of dying, they won't do much when living. One thing I see a lot is young people who don’t want to be boxed into any particular career, but instead develop very few skills or resources. Fear of commitment is a big thing in professional and personal matters.
User handcuffs
---
Further discussion
The broad class of "ways humans become restricted" is enormous. Addictions, phobias, commitments, obligations, mental and physical problems, and contracts, all involve restrictions. I think the word "handcuff" makes most sense to get at a particular aspect of something, and makes less sense in cases where the restriction is the dominant factor. "Paralysis handcuffs" doesn't make much sense to me, I'd just say, "paralysis."
Abstract handcuffs represent a vast topic that I’m not at all going to do justice to with this post. Each of the handcuffs I’ve mentioned have deep intellectual rabbit holes outlining the space and suggesting solutions to. For example, many kinds of minimalism (owning little, doing little, keeping one’s identity small) act against having these sorts of handcuffs. I think one aspect that gets overlooked are the unified connections between these similar clusters, and I hope this post is interesting in that light.
“Attachments” are discussed heavily in spirituality, particularly around Buddhism and Stoicism. Several of the handcuffs I mention would fit this bill.
Commonalities
Loss aversion is a well studied topic in Economics. People generally prefer avoiding losses to acquiring equivalent gains. This becomes a problem whenever one obtains something they will eventually lose. If you gain 10 units of happiness when upgrading your home, but lose 50 units when downgrading it, then the overall value proposition in an uncertain world is fairly grim.
Some examples:
- Companies are often criticized much more heavily for firing employees than for not hiring them.
- Onboarding a new member of a team can be a motivational win, but having a member leave is often more demotivating. (In my experience)
- Having children can bring happiness, but having your children die seems to often bring disproportionate sadness.
Maintenance
Friends and lovers
Intellectual Jury Duty
Forecasting · Systems · Jan 2022 · 412 words
Intellectual Jury Duty
For a lot of reasons, it’s useful to be able to get reasonable judgements about intellectual questions.
Questions like:
- “Was Steven Pinker broadly right in his thesis on violence?”
- “Was charity X a scam, or a legit operation?”
- “Was Google in the wrong, when they shut down a highly-used service?”
- “How successful EAs government program or department Z?”
I’m not talking about legal questions. Instead, key questions of public/intellectual opinion. De facto, not de jure.
There are clearly some questions where audience members have already made up their minds.
Intellectual juries would probably be optimized to appeal to different intellectual groups.
I’m now most interested in having an effective altruist jury. There could be a decent bar to be considered, like “attended 1 EAG conference” or “elected by 3 effective altruists.” Then, people in this pool would be randomly selected to be jury members on different questions.
It’s not clear how long or how sophisticated the deliberation process would be. I’m imagining a slack channel with a research assistant or two, maybe representatives of involved parties, and the jury members. Each would be expected to spend 3 to 20 hours researching/discussing each option. Ideally much I’d the discussion could be made public, in part so that others could chime in.
The obvious alternative to “Jury Duty” is “A panel of experts”; which would be more similar to the Supreme Court.
My guess is that the jury model would be more trusted and liked by junior community members, but less trusted and liked by senior community members. It might take less expensive resources (which is good), but is likely to output more random results (which is bad).
One plus is that the jury model could act better as a survey of what the average person would believe after deliberation.
This model is very similar to Deliberative Democracy and Citizen’s Juries. (Shout out to Zoe Cremer for flagging Deliberative Democracies).
Given that effective altruists already seem to like charity lotteries, having “deliberation lotteries” (this is what jury duty is) seems like it could be easily enough understood and appreciated.
Naturally, if any jury or expert council is set up, it could be forecasted against. So we could have thousands of estimates for things like, “how valuable was intervention X?”, and then juries could be targeted at very specific uncertain questions there. The estimates would effectively be amplifying (or phantomizing) the juries.
Discovery, Convenience, Presentation
EA & Eval · Nov 2022 · 1,166 words
I’ve been playing with ways of trying to break down “critique” or “criticism”.
EAs have a complex relationship with criticism. There are contests with big rewards to do criticism, and select critical posts get lots of upvotes. At the same time, there’s often a lot of anger at Twitter people who criticize EA. Critical comments on the EA Forum are sometimes heavily downvoted and sometimes heavily upvoted. It’s very difficult to draw any line in the sand regarding good and bad criticism.
Scott Alexander’s post Criticism Of Criticism Of Criticism, outlined this tension.
One step is to apply discernment, and try to divide up the critical properties of criticism.[2]
Let’s try splitting criticism into the properties “discovery”, “convenience”, and “presentation.”
Astute readers might notice that these properties really apply more broadly to “communication about sensitive or political topics.”
Discovery
How much valuable new information is presented? “Valuable” here means “long-term useful, to the population at large”.
“Information” implies entropy). Heavily redundant writing is low-information, or low-discovery.
Discovery implies work. How much work would it have taken for others to have found this information, or something very similar?
The term discovery comes from the domain of Law). It’s chosen to imply neutrality to bias, convenience, or presentation.
If the reader could predict most of the content, then the content is low-discovery. For example, an angry rant from someone on effective altruism, where the critic just found some list online of “10 arguments against effective altruism” and rehashes each one. Or an ideological rant about how effective altruism has a mismatch from Objectivism, revealing no insight other than what one could get from a very trivial Wikipedia skim. These rants reveal almost nothing for a decently well reader who reads the title.
Discovery and Bias:
If evidence is discovered by using a biased selection method, then we could call that biased discovery. If the receiver recognizes the bias, then they can properly adjust for it. Biased discovery can be very useful for a bias-aware receiver, but actively deceptive to a bias-unaware receiver.
Convenience
“Convenience” refers to the short-term or localized cost or benefit to a set of parties.
Lets start with a few examples. Imagine that you are making a public blog post that’s targetted to a certain organization.
Convenient communication would be things like:
- “Your organization is actually far better than you realized.”
- “Your business didn’t notice this one great hack, that would save it 10% of its costs.”
- “Your ideologies’ goals could better be achieved by this (very reasonable) strategy.
Inconvenient communication would include:
- “Your CEO has committed treason. Here’s clear evidence.”
- “Your organization is vastly harmful to the world.”
- “All your customers would be better off with competitors.”
“Convenient communication”, is that which is EV-positive for an agent, and “inconvenient communication” is that which is EV-negative. This is primarily relevant for communication shared broadly - if it’s just shared confidentially with the agent in question, the inconvenience can be minimized.
If you criticized Joe Biden, saying that his environmental agenda has a clear gap in it, and actually both voters and lobbyists would be happy with him for filling this gap, this could be very useful, of convenient criticism. If instead, you flagged an issue publicly that was impossible for him to change, and would upset a bunch of voters and lobbyists, that would be inconvenient.
“Convenience” is a slippery word. Its definition changes based on the context, and the context is often implicit.A formal distinction between discovery and convenience would involve defining two distinct agents; one of which is more local or proximal than the other in some way. “Discovery” refers to the value gain by the more global agent, “convenience” for the more local agent.
| Communication | Discovery Agent | Primary Convenience Agent(s) | Explicit Summary | Implicit Summary |
|---|
| A public pronouncement of “Your CEO has committed treason. Here’s clear proof.” | The public at large | The company at large, or the CEO | “This message has great discovery for the public, but is very inconvenient for the company.” | “This message had high discovery but was highly inconvenient.” |
| Your boss sends you a private message saying, “Your recent project was horrible” | You, in the long-term. This could help you improve. | You, in the short-term. This message might cause some panic.This might also be inconvenient for your boss, as it might make you dislike them more. | “This message is a great discovery for you, broadly speaking, but will be inconvenient for you in the short term.” | “This message had good discovery but was inconvenient.” |
| A journalist reveals a major public scandal about the Democratic party | The public at large | There are two main agents of interest: Democrats and Republicans | “This reveal is a significant discovery. It’s very convenient for Republicans and very inconvenient for Democrats” | |
Communicators typically care a lot about if their messages will be convenient or inconvenient to people with power over them. If you tweet publicly about all of the key flaws of your main friend group, that would probably be bad for you. If you tweet about some key findings that are very inconvenient to a vocal group on Twitter, you might well get attacked for that. If you accuse a public figure of a big scandal, they and their supporters will fight back. On the flip side, if you publicize convenient information about your colleagues, this could give you more in-group status.
Connections
Conflict Vs. Mistake: Conflict cultures value the conveniences of communication much more than the discovery.
Presentation
The last attribute is “presentation”. This isn’t a linear spectrum, but an ample space of options.
- Does it seem like the author is acting in bad faith; i.e. just revealing the criticism to hurt the group?
- Does it seem(to recipients) like the process used to find this criticism was truth-seeking, using the recipient’s standards?
- Did the writer share a similar epistemic and moral background as the readers? If not, can they demonstrate that they understand the readers' backgrounds well enough to reliably provide useful information to them?
- Does the writer generally seem like a good and reasonable person?
- What other messages is the author delivering, intentionally or unintentionally? These are often things like social alliances and status indicators.
Comments from Nuño Sempere
Restored with permission (Nuño's comments, with Ozzie's replies).
Nuño Sempere: Probably good to define this?
On “splitting criticism”:
Nuño Sempere: You are not "splitting criticism", you are "splitting the qualities of criticism", or something like that
Accuracy Agreements
Forecasting · Methods · Apr 2023 · 581 words
Title: Accuracy Agreements (Draft)
Note: This is very early and preliminary.
The problem: While prediction markets excel at determining outcomes for binary questions, they face difficulties when it comes to probability distributions and more complex scenarios, such as those involving functions.
Proposed solution: A client publishes an "Accuracy Score Agreement" with an associated "Type Specification." The agreement's terms are as follows:
- A purchaser of the agreement is required to provide a forecast that complies with the established Type Specification.
- Upon reaching a prearranged future date, the Agreement will undergo Resolution, which entails:
- The client will determine the answers to the forecasting questions.
- The client will evaluate and assign a score to the submitted forecast.
- The contract holder at the time of resolution will receive payment based on a linear function of a scoring rule. An example of this could be: "The average log score of the forecast minus the prior, multiplied by $10,000."
- Holding an "Accuracy Agreement" with a specific forecast has a calculable value. If the holder trusts the forecast, the value would be equal to the expected resolution payment. (Easily calculated using expected loss).
- When a question is proposed, potential buyers bid for the agreement. Each bidder submits their own forecast (which should be requested in advance via a private bidding system). If a bidder believes their forecast has an EV of "$25,000," they might bid "$23,000" for the agreement.
- The highest bidder is chosen and they buy the contract.
An example:
- A client publishes:
- A list of 50 continuous variables, to be resolved in 1 year.
- A set of (weak) priors for those variables.
- A simple scoring function, e.g., ($1K * total logScore sum)
- A future date for bidding to commence (1 month out).
- Bidders submit:
- A list of forecasts for the 50 variables, each as a probability distribution.
- A maximum price for purchasing the agreement with their forecast.
- The top bidder is chosen and sold the contract.
- In 1 year, the contract resolution occurs.
- All (or some) of the variables are resolved.
- The contracts’ forecasts get scored.
- The agreement owner is paid according to the predetermined scoring rule
Potential Changes / Improvements
- An active marketplace. Purchasers can trade these contracts with each other over time, after the initial purchase. This can work like a stock market, with many submitting prices at which they will buy or sell.
- Introduce a market with multiple shares, allowing buyers and sellers to purchase only a portion of the market.
- Implement "daily markets" where agreements pertain only to a specific date's forecast value. The same question would be asked daily, with different bidders potentially purchasing the corresponding agreement on different days.
- Buyers can update their forecasts over time. The contracts cover the average accuracy over that time. This incentivizes buyers to continue to improve their contracts.
- Forecasting questions can be resolved and scored by agreed-upon third parties.
- Maybe there’s an extra reward for a forecast that comes with a good explanation or similar. This could be part of the scoring function.
- In some cases, it might make sense for bidders not to have to put any money down. For instance, this might be considered gambling. One alternative, if the bidders are trusted, is that they get payments in two parts: one fixed fee, and one accuracy agreement. For example, Open Philanthropy puts out a call for a forecasting consultancy to forecast 1000 variables - but most of the payment is in the form of an accuracy agreement.
AI Tools as Evaluators
AI · Jan 2025 · 3,602 words
Reviewing Notes
- Article by Ozzie Gooen, intending to publish around Jan 17th.
- This is somewhere between “rough blog post” and “professional output”, leaning closer to the former.
- Any comments/takes are appreciated. I probably care most about big-picture ideas/criticisms / sharing the key thoughts with others who may go on to use them.
AI Tools as Evaluators
Summary
Today, expert humans are often the most trusted resources for making important determinations on subjective and speculative questions. As AI systems improve, we are likely to defer to these instead.
One immediate use of AI systems as “evaluators” is to use them to resolve complex forecasting questions. We already have prediction platforms that precisely propose and estimate long lists of tricky questions and resolve them with human judges. These systems are often highly innovative and technical, making them perhaps an interesting focus area to consider and experiment with AI evaluations.
In this essay we discuss how AI evaluations could work and some potential complications. Casual readers might want to skip and only read the section on “A Short Story of How This Plays Out,” others might find the details interesting.
AI evaluation systems could be dramatically useful, if they could be both highly optimized and actually trusted (with appropriate levels of trust). They’re also very tractable - there are many experiments and innovations that could likely be done in the next year. We think they deserve more attention, and we expect to focus more on this area going forward.
Note that AI evaluations don’t need to be strong yet to be useful. If they’re just expected to be strong in a few years, we can start setting up prediction tournaments to target them today. This can help us set up decently-incentivized forecasting markets on difficult-to-resolve questions, without needing to arrange humans to resolve them.
Motivation
Say we want to create a prediction tournament on a partially-subjective or speculative question.
For example:
- “Will there be over 10 million people killed in global wars between 2025 and 2030?”
- “Will IT security incidents be a national US concern, on the scale of the top 5 concerns, in 2030?”
- “Will bottlenecks in power capacity limit AIs by over 50%, in 2030?”
These are all questions that require some amount of subjective judgement. Coming 2030, it will likely be possible to argue on either side of any of these questions, but I suspect most reasonable people will wind up agreeing with each other on one side of each.
The current solution to this sort of endeavor is to select some human evaluator to make a judgement call. On Manifold this is the question author, and different authors develop different reputations for doing a good or bad job at this. On Metaculus, often small panels of experts are chosen for the more subjective and important questions.
Humans have a lot of downsides though.
- Dramatically more expensive than AI systems, especially when expertise is desired.
- Very short track records or evaluations.
- Poor accessibility. Most predictors can’t ask them questions, for example.
- Humans change. Their opinions or motivations can dramatically shift over time.
- Many humans can’t be guaranteed to be available at points in the future.
- Humans can have substantial biases and/or be corrupt.
AIs as Question Evaluators
Instead of using humans to resolve thorny questions, we can use AIs. There are many ways we could attempt to do this, so we’ll walk through a few examples.
Option 1: Use an LLM
The first option to consider is to use an LLM as an evaluator. For example, write,“This question will be judged by Claude 3.5 Sonnet (2024-06-20). The specific prompt will be, …”
This style is replicable, simple, and inexpensive. However, it clearly has some downsides. The first obvious one is that Claude 3.5 Sonnet doesn’t perform web searches, so its knowledge would likely be too limited to resolve future forecasting questions.
Option 2: Use an AI Tool with Search
Instead of using a standard LLM, you might want to use a tool that uses both LLMs and web searches. Perplexity might be the most famous one now, but other advanced research assistants are starting to come out. In theory one should be able to set a research budget that’s in line with the importance and complexity of the question.
This is probably better than Option 1 for most things. But there are still problems. The next major one is the risk that Perplexity, or any other single tool we can point to now, won’t be the leading one in the future. The field is moving rapidly, it’s difficult to tell which tools will even exist in 5 years, let alone be the preferred options.
Option 3: Use an “Epistemic” Selection Protocol
In this case, you don’t select a specific AI tool. Instead you select a process or protocol that selects an AI tool.
For example:“In 2030, we will resolve this question using the leading AI tool on the ‘Forbes 2030 Most trusted AI tools’ list.”
We’re looking for AI tools that are “trusted to reason about complex, often speculative or political matters.” This arguably can be more quickly expressed as searching for the tool with the best epistemics.
Epistemic Selection Protocols (Or, how do we choose the best AI tool to use?)
Arguably, AI Epistemic Selection Protocols can be the best choice of the above options, if one could implement them effectively, for most 2+ year questions. There are a lot of potential processes to choose, though most would be too complicated to be worthwhile. We want to strike a balance between simplicity and optimality.
Let’s first list the most obvious options.
Option 1: Trusted and formalized epistemic evaluations
There’s currently a wide variety of AI benchmarks. But arguably, none of these would be great proxies for which AI tool would be the most trusted question resolvers in the future. Newer, deliberate benchmarks could help here.
Example:“This forecasting question will be resolved, using whichever AI Tool does the best on Epistemic Benchmark X, and can be used for less than $20.”
Option 2: Human-derived trust rankings
Humans could simply be polled on which AI tools they regard as the most trustworthy. One challenge is that different groups of humans would have different preferences, so the group would need to be specified in advance for an AI Selection Process.
Example:“This forecasting question will be resolved, using whichever AI Tool is on the top of the list of ‘Most trusted AI Tools’ on LessWrong, and can be used for less than $20.”
Option 3: Inter-AI trust ratings
AI tools could select future AI tools to use. This could be a 1-step solution, where an open-source or standardized (for the sake of ensuring it will be available long-term) solution is asked to identify the best available candidate. Or it could be a multiple-step solution, where perhaps AI tools are asked to recommend each other using some simple algorithm. This can be similar in concept to the Community Notes algorithm.
Example:“This forecasting question will be resolved, using whichever AI Tool wins a poll of the ‘Most trusted AI tools’ according to AI tools.’ In this poll, each AI tool will recommend its favorite of the other available candidates.” (Note: This specific proposal can be gamed, so greater complexity will likely be required.)
A Short Story of How This Plays Out
In 2025, several question writers on Manifold experiment with AI resolution systems. Some questions include:“Will California fires in 2025 be worse than those in 2024? To answer this, I’ll ask Perplexity.AI on Jan 1, 2026. My prompt will be, [Will California fires in 2025 be worse than those in 2024? Judge this by guessing the total economic loss.]”
“How many employees will OpenAI have in Dec 2025? To answer this, I’ll first ask commenters to write arguments and/or facts that they’ve found on this. I’ll filter this for what seems accurate, then I’ll paste this into Perplexity. I’ll call Perplexity 5 times, and average the results.”
Forecasting users gradually identify the uses and limitations of such systems. It turns out they are surprisingly bad at advanced physics questions, for some surprising reason. There are a few clever prompting strategies that help ensure that these AIs put out more consistent results.
AI tools like Perplexity also get very good at hunting down and answering questions that are straightforward to resolve. Manifold adds custom functionality to do this. For example, say someone writes a question, “What Movie Will Win The 2025 Oscars For Best Picture?” When they do, they’ll be given the option to have a Manifold AI system automatically make a suggested guess for them, at the time of expected question resolution. These guesses will begin with high error rates (10%), but these will gradually drop.
Separately, various epistemic evaluations are established. There are multiple public and private rankings. There are also surveys of the “Most Trusted AIs”, held on various platforms such as Manifold, LessWrong, and The Verge. Leading consumer product review websites such as Consumer Reports and Wirecutter begin to have ratings for AI tools, using defined categories such as “accuracy” and “reasonableness.”
One example question from this is:“In 2030, will it seem like o1 was an important AI development, that was at least as innovative and important as GPT4? This will be resolved using whichever AI leads the “Most trusted AIs” poll on Manifold.”
There will be a long tail of AI tools that are proposed as contenders for epistemic benchmarks. Most of the options are simply minor tweaks on other options or light routers. Few of these will get the full standard evaluations, but good proxies will emerge. It turns out that you can get a decent measure by using the top fully-evaluated AI systems to evaluate more niche systems.
In 2027, there will be a significant amount of understanding, buy-in, and sophistication with such systems (at least among a few niche communities, like Manifold users). This will make it possible to scale them for more ambitious uses.
Metaculus runs some competitions that include:“What is the relative value of each of [the top 100 AI safety papers of 2026]? This will be resolved in 2030 by using the most trusted AI system, via LessWrong or The Economist, at that time. This AI will order all of the papers - forecasters should estimate the percentile that each paper will achieve.”
“What is the expected value of every biosafety organization, estimated as what Open Philanthropy would have paid for it from their biosafety funding pool in 2027? This will be judged in 2029, by the most trusted AI system, for a random 1/10th of the organizations, with a budget of $1,000 for each evaluation.”
Around this time, some researchers will begin to make wider kinds of analyses, and forecast compressions.“How will the SOTA epistemic model of 2030 evaluate the accuracy and value of the claims of each of the top 100 intellectuals from 2027?”
“Will the SOTA epistemic model of 2030 consider the current SOTA epistemic models to be ‘highly overconfident’ for at least 10% of the normative questions they are asked?”
The top trusted AI tools start to become frequent ways to second-guess humans. For example, if a boss makes a controversial decision, people could contest the decision if top AI tools back them up. Similar analyses would be used within governments.
As these AI tools become even more trusted, they will replace many humans for important analyses and decisions.
Protocol Complications & Potential Solutions
Complication 1: Lack of Sufficient AI Tools
In the beginning, we expect that many people won’t trust any AI tools to be adequate in resolving many questions. Even if tools look good in evaluations, it will take time for them to build trust.
One option is to set certain criteria for sufficiency. For example, one might say, “This question will be resolved using whichever AI system first gets to a 90/100 on the Epistemic Benchmark Evaluation…” This would clearly require understanding and trust in the evaluations, rather than in a specific tool, so this would require strong evaluations.
Complication 2: Lack of Ground Truth
One standard difficulty facing subjective and/or speculative questions is that problem of getting a specific answer. There are many questions for which the correct answers will only be found far after they are needed, and others where there will never be correct answers.
The bar to do a good job should arguably be “do better than alternatives,” rather than trying to be fully precise, in situations where the latter is impossible.
The goal of question resolutions is to do the best we can with the available resources (financial costs, compute, time, etc). In order to be useful to clients, it should generally outperform other question resolution strategies they have access to.
It arguably seems important and tractable for these tools to be calibrated, at least in ways that reflect a client’s belief system. The next step is to have as high-resolution an answer as possible, given strong calibration.
In a forecasting environment, resolutions don’t need to be precise. The main thing is to make sure that they are calibrated, and that they represent more information and deliberation than the predictions.
Complication 3: Goodharting
We’d want to avoid a situation where one tool technically maximizes a narrow “Epistemic Selection Protocol”, but is actually poor at doing many of the things we want from a resolver AI. Perhaps some tools have Goodharted the Protocol.
To get around this, the Protocol could have restrictions, like to ask> What will be the most epistemically-capable service in [Date] that satisfies the following requirements?1. Costs under $20 per run.2. Is publicly available.3. Has over 1000 human users per month (this is to ensure there’s no bottleneck that’s hard to otherwise specify.)4. Completes runs within 10 minutes.
- Has been separately reviewed to not have significantly and deceivingly goodharted on this specific benchmark.
It’s often possible to get around Goodharting by applying additional layers of complexity. Whether it’s worth it depends on the situation.
Complication 4: Different Ideologies
Say there’s a question on the moral costs and benefits of a policy change that cuts taxes. People from different philosophical or ideological backgrounds are likely to disagree on many of the core assumptions that could lead to an answer.
One solution is to not provide an answer. Instead, express that it’s a “difficult question, with many valid answers.” However, that’s often not very useful.
A second solution is to allow for ideologically-representative AI tools to compete. This could mean a bunch of separate tools with different capabilities, or it could mean one AI tool that has settings that allow it to represent these beliefs.
A more complex setup could involve a tool that generates answers individualized for specific people, with different levels of study on certain questions. So for example, “In 2030, how valuable was California Proposition 10, according to an arbitrary person X, having studied the topic for [10, 100, 1000] hours?.” This question would be estimated with an algorithm that takes in attributes of a given person (i.e. a Scorable Function), and how much time they spent studying the question.
Complication 5: AI Tools with Different Strengths
One might ask:*“What if different AI tools are epistemically dominant in different areas? For example, one is great at political science, and another is great at advanced mathematics.”*An obvious answer is to then create simple compositions of AI tools. A router can be used to send specific requests or subrequests to other AI tools that are best equipped to handle them.
One possible AI tool resolution workflow
Complication 6: AI Tools that Recommend Other AI Tools
Imagine there’s a situation where one AI tool is chosen, but that tool recommends a different tool instead. For example, Perplexity 3.0 is asked a question, and it responds by stating that Claude 4.5 could do a better job than it could. Arguably it would make a lot of sense that if an AI tool were highly trusted to make speculative judgements, it could be trusted to be correct when claiming that a different tool is superior to itself.
This probably won’t be a major bottleneck. If AI tools could simply delegate other tools for specific questions, that could just be considered part of it during evaluation.
End of Article
(The rest of this is scrap / stuff that might be better in future posts)
Complication: AI Tools with Adjustable Parameters
The name “Epistemic Front-Runner” implies that there’s some specific and discrete AI process that produces results. But this might not be the case.
Today, Perplexity has two modes: regular and pro. It’s easy to assume that the pro version is the front-runner.

But what if instead, Perplexity allowed you to enter an arbitrary budget. In that case, how would one define the “Front-Runner”?
Or what if there were several more tunable parameters to choose. Perhaps some are configurations that might impact performance, but where optimization is very difficult.
This highlights that the idea of “Epistemic Front-Runner” is likely not as clean as the phrase suggests. But we can still make approximations, and use the term as a placeholder.
A more precise name would probably be something more like, “Widely-accessible, evaluated, and reasonably-priced epistemic standard.”
Evaluating AIs using Epistemically Dominant AIs
Say you have two broadly capable AI tools that can resolve generic forecasting questions or make subjective calls. You broadly trust one more than the other. We can then call these AI_weak and AI_strong.
One obvious thing to do here would be to use AI_strong to evaluate AI_weak. AI_strong could probe AI_weak over a large domain of questions. It would then separately generate its own response to these questions and have AI_weak generate a response, compare the responses, then evaluate AI_weak for its capabilities. In most situations, it’s expected that AI_strong will outperform AI_weak - but there might also be situations where AI_weak outperforms AI_strong in ways that AI_strong will understand.
For example, AI_strong might generate 10,000 binary forecasting questions among a wide range of topics. Both AI_strong and AI_weak would forecast on all of these questions. In the case that there’s a disagreement, AI_strong might converse with AI_weak to see if it could be convinced. After that, one would use a proper scoring rule on the values of AI_weak, where we assume that the new best-guess values of AI_strong (after deliberating with AI_weak) are correct.
What this means is that, while humans might have a lot of uncertainty about subjective and speculative questions, we could get a gauge for how every AI tool compares on them, in respect to a certain Epistemic Front-Runner.
If such a system were implemented and well-understood, it would be possible to then add other layers to it. For example, prediction markets could forecast how well certain AI tools will do against future Epistemic Front-Runners that don’t yet exist.
Some key questions:
- When will AI tools be “Epistemically Sufficient” to resolve various forecasting or speculative questions, in a manner that’s useful? If these don’t exist now, can we predict when they may exist?
- What are some clean Epistemic Selection Protocols options, for choosing potential Epistemic Frontrunners?
- What are the best methods for evaluating AIs using Epistemically Dominant AIs?
But what protocol might be best? There are some clear concerns to worry about.
- If the protocol is mediocre, it could result in poor AI tools doing the evaluation.
- If the protocol is noisy, it could result in certain AI tools known for specific biases. While any specific tool could at least be predictably biased, having uncertainty about which tool is used would lead to noisier predictions.
- If the protocol is complex, forecasters and viewers might refuse to engage with it. They might default to not trusting it.
We might ideally have a protocol similar to Coherent Extrapolated Volition.
If protocols might be complicated, then it would make sense to not make new protocols for every forecasting question. Instead a forecasting question would just refer to a commonly used protocol. For example, “Will there be over 10 million people killed in global wars between 2025 and 2030, according to the AI chosen by Common Epistemic Selection Protocol #7?” In practice, it seems likely that such protocols might be simple, in which case the specifics can be used instead. For example, “Will there be over 10 million people killed in global wars between 2025 and 2030, according to the AI ranked highest on the LessWrong Epistemic AI Leaderboard.”
What if there are no trusted AI tools, but it’s expected there might be in the future? In that case, there could be Epistemic Selection Protocols that simply wait until certain criteria are satisfied. For example, one might say, “This question will be resolved using whichever AI system first gets to a 90/100 on the Epistemic Benchmark Evaluation…” This might be called, “Epistemic Sufficiency.”
To clarify this more, we can consider the idea of an “Epistemic Front-Runner.” This is the most trusted AI tool that exists at a certain point for broad question resolution. We might broadly want an “Epistemic Selection Protocol” that can reliably select the future “Epistemic Front-Runner.”
Ways to be More Cooperative in Everyday Life
Culture · Mar 2025 · 3,317 words
High-Level
- Reality vs. Perception
- Generally, these are correlated. But there are exceptions!
- Lots of people want to be seen as cooperative. It can be much less valuable to actually be cooperative. There are some areas where discrepancies between the actual and the perceived can come into conflict.
- For example, say that a person realized that their social group is making a significant mistake. If they argue against it, they know that it would be assumed they are arguing because they are trying to attack the group. In this case, they could be more liked but less useful by staying silent.
- Caring a lot about actually being cooperative, can ironically be seen as uncooperative. The reason is that pointing out the discrepancy might be hurtful to people who are taking advantage of the discrepancy. While this might be useful to the group in the long run, it will hurt some players in the short-run.
Academia
- Vocabulary
- It's generally considered more prosocial to use the terminology/vocabulary that has been previously used.
- At the same time, this can quickly lead to conflicts between what certain intellectuals want, and what your audience wants. One specific intellectual might prefer it if you use their terminology, but your audience might find this terminology confusing.
- It’s arguably more selfish to name terminology after yourself, or to name it under something that your community will find easy, but other communities will find hard.
- Vocabulary presents a lot of work. Learning new vocabulary/jargon is very work-intensive. Also, different jargon is optimized for different use cases.
- Citations
- It’s obviously considered good practice to give credit to others who have done similar work. If others came up with the key ideas or causally led to the work, that’s particularly important to flag.
- Obviously, (a) leads to situations where one is incentivized to cite certain work, at the expense of other readers. For example, one person might hype up the work of a colleague that’s expected to reciprocate, but such hype distorts the beliefs of readers.
Social Media
- On Bragging / Positive Personal Information
- Be careful of bragging, intentionally or not. It can be easy to create disvalue here. Lots of people compare themselves with others in harmful ways - when they see others succeeding, they feel worse about themselves.
- This includes obvious humble brags “I feel so humbled as to have received X award.” It also includes a lot of information that hints at success - like vacation photos, fancy food pictures, pictures that show social success.
- Arguably “writing smart posts” itself does involve “signaling competence” and can have negative effects.
- Having a positive bias can also mislead people’s beliefs.
- Generally, people like hearing positive updates for people that are
- Underdogs
- Helpful to them (i.e. your spouse does better, in ways that are likely to help with your own success/popularity)
- Providing complements
- People generally like receiving positive comments. A lot of people are bad at providing these.
- Being able to empathize and appreciate people, then vocalize that to them, is a hard skill and task for many people, especially people who are doing well or who are very smart. But it’s probably good to do at the margin.
- Positive public comments can leak into the issue of (1). If you give someone a positive comment, but a lot of readers regard that person as a competitor to them in some form, that could produce a net loss.
- Providing feedback
- When feedback is sensitive, it’s good to send it as private messages, instead of publicly.
- If you have uncomfortable but important information, it can be very useful to share it, even if this might be difficult for you. Kim Scott’s book on Radical Candor is useful here. It can be very easy to fall into the zone of “Ruinous Empathy”.
- Debates/battles
- It can be easy to get into debates/battles in comments. I think of this as a distinct mini-game to have. I think these quickly get into incentives outside of [honestly getting at the truth]. Instead, this quickly can turn into a fairly zero-sum game. Like:
- One person in the debate will come out as more trustworthy/impressive, and others will come out as less trustworthy/impressive. It’s a lot like a conventional physical fight.
- Debate helps create some sort of intellectual pecking-order. Like, if one is used to failing at semi-public debates with certain individuals, they will stop attempting them. Winners gradually “upgrade” to going against more prestigious opponents.
- The more a debate gets heated, the higher risk it can become. If it’s semi-public, it’s very easy for parties to do things that will harm themselves. Like, make a comment that winds up reflecting poorly on themselves.
- Humans seem to enjoy playing games with each other, and debating can act as a clear game. There are rules, challenges, and winners.
- Obviously, debates follow different rules and scoring procedures than honest truth finding.
- This seems highly analogous to fights between [animals/humans] for dominance.
- Debates can quickly become about power.
- People can challenge the claims of others, which can be equivalent to exclaiming, “I want to do intellectual battle with you. I’d like to start on this topic, where I think I have an advantage.”
- The result can be that one person gains power and another loses power.
- Debates happen if:
- If one person thinks another is both [more powerful than they think is reasonable]
- One person thinks another is vulnerable to a debate conflict. I.e. would do poorly
- One person thinks that they will do better. This doesn’t have to just be about social recognition - it can even be internalized, as personal ego. You’re impressing yourself, similar to the feeling that comes from winning a board game with no one else watching.
- Intellectual power is arguably nuanced. Specific people arguably have different levels of intellectual power on very specific topics/claims. As such, an attacker could be pushing back against the combination of person x claim, instead of that person on the whole.
- The fact that intellectual debates affect power can make truth seeking very difficult.
- For example, if you just want to correct a point on X, but aren’t trying to damage the reputation of people who claim X, it can be very difficult to signal this. The flip side of this is that if you are trying to hurt their reputation, then you can be very sneaky by claiming you only care about claim X. So it’s very hard to trust people on this, and correspondingly hard to signal good faith.
- One very positive thing about debates is that it motivates intellectual discussion.
- Two people might be having a status fight with each other - but the output could be a long list of interesting insights that are useful to third parties. It can be difficult to motivate people to produce any useful intellectual work, having them get into intellectual debates can be an effective (though sometimes deceptive) strategy.
- Debates aren’t inherently bad. They can be quite useful on the whole. But their downsides and characteristics should be understood.
- It can be very useful for the public/friends to have a decent idea of what the intellectual pecking-order is. This won’t match the truth, but will generally correlate with it.
- One unspoken rule of debate is that “the person who fails to reply, thinks that their position is weak”
- This provides significant fuel and incentives to these debates.
- This also means that if one person makes a provocative point on someone else’s post, then they are setting up the incentive such that that person is incentivized to respond. If they don’t, that can be seen as them admitting defeat/agreement.
- I call this “debate baiting”. As with other things here, what’s going on is rarely explicitly stated (“I’m challenging you to a debate”), which makes it difficult to discuss.
- The sunk cost fallacy makes things worse. If you’ve spent 3 years debating intellectually, it’s significantly more awkward to end the debate.
- On different platforms, the rules of debate are very different.
- “Debate Exits”
- There are some clever strategies to get out of debates while not taking a status hit.
- Some of these strategies could make both participants look good.
- One nice thing about this is that it’s possible to convert a “heated debate” into a more “truth-aligned conversation.”
- One example: You take a clearly cooperative action, then argue you’d like to exit.
- The combat example of this is, “You have a clear window to make an attack on your opponent. But instead of doing so, you back out, out of clear concern for the welfare of your opponent.”
- In online debate, this could look like showing a lot of respect for your opponent, declining to make personal attacks. This can reframe things from “a zero-sum debate minigame” to a much more positive-sum minigame.
- When you do this, the other side could decide to cooperate with that, or defect. Generally, if both parties really want to get out of the debate mini-game, there are often ways to do that.
- Debates around Tribal issues
- If you’re debating on the side of a tribal issue, then you’re representing the tribe. The visibly prosocial thing to help your tribe is for you to “perform well.” So it can be particularly valuable for you to “look good”, and in some cases, to make the other side “look bad.”
- Note that “being prosocial” here means “people around you clearly will benefit, which in turn means that they will reward you for that favor.
- There’s often an understanding that mediums should be attacked in kind.
- Examples:
- Funny memes vs. funny memes
- Rap diss tracks vs. rap diss tracks
- Clever tweets vs. similarly clever tweets
- Academic essays vs. academic essays
- Interpretive dance vs. interpretive dance
- Sets of statistics vs. sets of statistics
- For those examples, consider the weirdness of attacking someone using a different medium, to respond to an attack. Use an academic essay to respond to a Tweet. Or use a rap diss track to respond to a Reddit meme. Use a postmodern philosophy paper to respond to a statistics argument.
- Obviously, when there’s a meme war going on, a lot of the way to win is by being clever and funny - not by being correct. So, different formats feature very different alignment of [participant success] vs. [one side being correct].
- Perhaps there’s some sense of proportionality - it’s seen as weird if you respond with a very different scale of an effort than was brought on you. Going too high-effort seems off; it’s easy for this to accidentally signal “I think your stance is quite good, so I need to spend a whole lot of time addressing it.”
- Also, maybe this is considered uncooperative. Like, “I’m shifting this fight from one where each response takes 5 minutes, to one where each response takes 5 hours. As such, I’m making it more difficult for both of us, in a way largely considered as unfair. The other side didn’t agree to this escalation and likely would reject it.”
- This weirdness (the importance of responding in kind) highlights that these battles are less about truth seeking, and more reflect some game.
- In comedy, they often say that the first key challenge is to be liked. I think this is also true with a lot of debates. If you come off as mean, that will become the most interesting aspect of the debate for listeners, and this can greatly hurt you. Similarly, if you come off as weak (even in stupid ways, like, “you’re just physically smelly”), then that could greatly hurt you. It really is a popularity contest of a certain kind.
- An implied standard of winning/defeat is, “Are you successfully able to convince your opponent?”
- This is clearly unreasonable. “Being convinced” often means “losing status.”
- These battles are happening on very different scales
- Examples
- Direct, 1-time conflicts between two people, for 5 minutes.
- Prolonged disagreements. Say there are two sides of a long-standing corporate argument.
- Prolonged international disagreements. See extended Twitter spats between liberals and conservatives, for instance.
- Arguably these follow a lot of the same rules of intellectual battles that I mention above.
- Community-wide debates are in some ways equivalent to large-scale warfare
- Both communities are now in a power struggle. Wins by one are losses for the other. Much of these wins/losses are in power/prestige, not in concrete arguments.
- Status among communities is a real thing.
- If one Mormon is great on Twitter at making strong sarcastic memes in support of Mormonism, this will grow the status of Mormonism around that extended Twitter community. People will associate all of Mormonism, a bit more, with [people on Twitter who demonstrate competence, in this case with Twitter memers].
- Likes/reactions act as weapons in the fight.
- It’s useful for a person on one side of a large debate to upvote/heart all the content that supports their side.
- Given there are so few signals of how an online debate are going, people pay extra attention to the ones that exist. Like/heart counts are prominently shown and are adjustable, so people will use these to help their side.
- Obviously, this raises the importance for platforms to provide signals that correlate with correctness and value.
- The situation generally is highly analogous to sports communities. In these situations, communities go up and down in status with each other based on how well their respective sports teams do. A Yankees fan will feel superior to a Dodgers fan, when the Yankees win.
- It’s often useful to bring in people to support your side.
- This means that participants are incentivized to bring in more participants.
- This means that it’s seen as prosocial to participate on one side of these. It is prosocial, at least to one side of a fight.
- Tribalistic affiliations often become a major part of people’s identities
- This can be very prosocial (to a tribe).
- When one strongly publicly identifies with one side of a fight, they are publicly committing to feel very good when that side wins, and very bad when that side loses. This correspondingly means that they will be much more incentivized to support this side. This is clearly positive to people on that side.
- It’s not clear what other things there are to impact one’s personality, besides this sort of tribalism.
- Arguably people would try to identify with generic measures of success, but this is a competitive game that typically requires expensive signals. Lots of people would love to be known for being successful, but this obviously is very limited. “Being successful” is fairly zero-sum - only a few people can be “more successful than average”, or be “seen as more successful than average.”
- There’s an interesting game of people choosing the tribes (and dedication levels) in ways that are maximally advantageous to them. Arguably, people are good at generally doing what’s the most convenient.
- People will often choose tribes such that their personal success/status is maximized. You have status in the tribe, and the tribe has status outside of the tribe.
- For example, there’s a trade-off between “high status in a low-status tribe” vs. “low status in a high-status tribe.”
- Convenience
- People rarely want to engage in this sort of analysis.
- When describing one’s intentions, it’s often the most personally beneficial to argue that one’s incentives are as prosocial and positive as possible.
- Given that it’s incredibly hard to verify anyone’s stated reasons for doing things as either true or false, these are incredibly easy to lie about.
- There are cultural standards of “claiming that one’s reasons for most of their actions are highly altruistic.” I suspect that a lot of this is dishonest or false. But this leaves honest people in an awkward position. If they correctly state “My own reasons are based highly on my personal benefit.” they could easily be seen, in comparison to others, as utterly contemptible, given that everyone else seems to altruistic.
- I suspect that a great deal of people involved in debate will use generally lines like:
- “I care so much about the honest truth.”
- “I think that Person X (who I’m debating) is wrong, and I’m trying to help them fix their mistake.”
- Because debates can quickly become tribal, if one player is honest about their intentions in a way that looks bad for them, it would correspondingly hurt their greater community. The locally-prosocial thing can be to be incredibly dishonest.
- This also means that [being dishonest to favor one’s group] can quickly be a costly (and thus significant) signal of group allegiance.
- Similar applies for other personally-harmful things. Like, doing things generally seen as cruel, for the sake of the collective. (Assuming that “being cruel” often comes with negative status)
Conflict, a Theory, Before and After -> “Conflict Games?”
There’s a very frequent pattern that happens that can be simply described by:
- There are two parties.
- Both have some ability to trigger a conflict.
- The conflict is typically net-negative in expectation and risky for both.
- This means that both of them get some bargaining power. They could both initiate a conflict if they need to.
- There’s then things like the “madman theory” - that one should seem irrational in order to essentially precommit to conflict, forcing the other’s hand more often.
- There’s often a power struggle, over the question “who can cause the more harm to the other”, even if this harm isn’t actualized. The party with the greatest ability to cause harm, and the least personal risk, is the one with the greater power.
Examples:
- Animals will occasionally fight each other. Even when they’re not fighting, the potential of them to fight is significant.
- Relatives will fight with each other from time to time. This is often not physically violent, but still damaging.
- Bullies and such work this way.
- Police manage large populations. There’s a risk of being caught and punished. But ideally, the police don’t want to spend many resources punishing many people.
Cooperation
Interesting examples of coordination of one group, at expense of that group coordinating with another.
- A worker helps to their union
- A family member increases the prestige of their family
- A mediocre bureacrat stays silent on ways their colleagues cheat the system
- A warrior helps their tribe
- A parent puts a lot of resources into their child. Later, the child helps them. The child also makes them look good to their friends.
There are also interesting ways in which groups sometimes coordinate with each other
And villains often do better with coordination
- The trope of evil people making contracts and that they don’t break. Obviously, them being honest matters to them. Or “A Lannister always pays his debts.”
Group loyalty is a major thing, and has large ties to coordination.
There’s reciprocal coordination, where one benefits themselves. And there’s no reciprocal coordination. Of course, a group itself is strongly incentivized to make sure that incentives are such that all good coordination is reciprocal.
One main thesis is that a lot of what people consider “morality” is really “coordination”. A few reasons.
- It makes a lot of sense that groups would try to get their members to coordinate in any way they could. Morality / religion are obviously useful things for a collective.
- People want to be seen as good people. Coordinating can be mistaken for altruism, so why not pretend it’s altruism? That way people will think higher of you.
Thoughts on the Value and Motivations Behind Human Personalities
Culture · Apr 2025 · 2,688 words
Thoughts on the Value and Motivations Behind Human Personalities
Author: Ozzie Gooen and Claude
Draft status: This was the result of a short conversation with Claude. I think it’s not very well organized as is, but I also think it has some good points. This subject seems too big for a Facebook post, but I’d like to spend more time with it before making it a regular post. At this point I’m interested in feedback and discussions on the ideas. Note that the structure and many details will likely significantly change.
—
I.E. Let’s look at personality through the lens of human utility optimization and signaling.
I've been thinking about personality development lately, and wanted to share some thoughts. This is speculative and I'm not an expert in psychology, but I think there are some useful frameworks here.;
(Claude discussion here: https://claude.ai/share/c0a7fd09-6a54-436d-a4b1-bbb7caedf547)
What Are Personalities, Really?
I think a lot of developing a "personality" is essentially "acting according to an established or easily-understandable pattern." This makes it much easier to both know how to approach different situations, and for others to predict your behavior.
There's a gigantic space of potential behaviors one could take at any moment, especially in social settings. So instead of thinking, "How specifically should I interact with X?" it's often easier to occasionally choose a decent personality type, then figure out what that personality type would be likely to do.
This feels similar to "choose a fighter" in a video game select screen. You have a few established clusters, based on things popular in the media and in your social circles. Many are poor matches for many specific people. People generally try to select ones that would make them successful.
The Economics of Personality
Why are there different personality clusters? Well, like it makes sense for societies to have diversity and specialization in professions, it also makes sense to do so for personalities. In a social group of very serious people, one friend could provide extra value by being the clown of the group. A good sense of humor requires certain effort and costs to gain, and there's diminishing value to it, so it could make sense for some people to specialize but not others.
Changing personalities is very costly within any social group. First, this is expensive for that social group. Them being able to closely predict the behaviors of each person is very useful (for example, to guess when they might lie or deceive), and a change of personality can force them to relearn how to work with that person.
Also, the more one member changes personalities, the harder their group can predict what directions they might go in the future, if this means they can expect more personality changes. What if they make a long-term promise with a trustworthy friend, but then later that friend changes to a low-trust personality?
One interesting question is, "What does it even mean to stay friends with someone, when they substantially change personalities? Are you friends with the personality, the body that executes that personality, or something else?"
Personality as Technical Infrastructure
We can think of personality development as similar to brand identity for a large organization. These typically give off a lot of signals, they fall into clusters, and much of the work is about setting the right expectations with clients.
A discount brand has very different strengths and weaknesses as a premium brand. Developing a solid brand presence takes a lot of time and iteration. Clients/customers often dislike significant brand changes (for example, when brands try major redesigns, when premium brands become budget, when the History channel starts getting into reality TV, etc).
The brand both means that clients/customers know what to expect, and they can mean that internal employees understand what they should aim for.
Developing a personality takes a lot of work. In a fighting game, it takes a lot of time to learn the moves of any one character. If you change characters, you largely need to start over. In comparison, a personality typically comes with a great deal of behaviors and nuance that you need to get right.
The Homogeneity of Professional Personalities
I know a lot of people feel frustrated that they have to heavily conform to engage with many professional positions. For example, a lot of companies really seem to value employees being highly uninteresting, personality-wise. From the perspective of an individual employee, this can be suffocating.
But on the flip side, I think that people with boring, and thus predictable, personalities can be highly useful to others. I haven't heard many people complain that their chefs, lawyers, police department, customer support representatives, bosses, etc, didn't have very unusual personalities.
Specific unusual qualities like "strong sense of humor" can be appreciated. But clients typically want to make sure that these workers are highly trustworthy, reliable, and predictable. And it's hard to do that with them also being highly eccentric.
Basically, I think that the specific incentives of our highly-social world would very much benefit, in many sectors, from a highly-uniform population.
Anti-Personalities and Counter-Signaling
One aspect of personalities is "anti-personalities" or "I'm trying to signal I'm not X". For example, I know that some African American women are afraid of being seen as upset/emotional, so become extra reserved.
Tech CEOs and leads are supposed to signal weirdness, as a form of counter-signaling. For many of them, they're supposed to be weird. But they have limited resources to do so (little time, for instance), so most are weird in specific/common ways. Few will become goths. A lot of tech CEOs, while unlike their staff, are somewhat similar to each other.
Personality Market Segmentation
Clothing brands often strongly target certain personality profiles. When one buys clothing locally, they often need to choose between things like, "The edgy teen store" vs. "The preppy rich store" vs. "The outdoorsy type who loves the environment". This is heavily restrictive.
In high school, there are known to be pretty strict clusters (goths/geeks/jocks). Prisons also have clusters (race). Most workplaces seem to discourage strong aesthetics like goths or jocks, in favor of "generic white-collar professional".
But certain communities like arts departments could favor certain groups. I assume people get spread out - so adult goths would be more clustered, and others would see them less often. This also brings the point that goths are probably a bigger thing in high school than in work afterwards - as the incentives are clearly different.
Personality Politics and Dynamics
There are political battles happening between personality clusters. For example, "being an edgy male" is sometimes seen as positive (e.g., in media like Twilight), but more recently is associated with right-wing incels. This means that people of a personality subtype sometimes fight together to preserve the status of that subtype.
A more straightforward example is goths working on goths advocacy in the media.
This might lead to "personality dynamics," as certain personality types become more or less popular depending on various trends. This reminds me of fashion trends, which clearly happen. Or terminology trends. I'm sure many deeper parts of personality are similar.
Local Optima and Personality Change
I know David D. Burns gave several examples of people with mean-spirited personalities. Some weren't convinced to do positive things with straightforward arguments. Instead, the first thing to do was to appreciate how their negative qualities were actually useful to them in some important ways. They were stuck in local optima.
Because changing personalities is so costly, I'd assume that many people have chosen sub-optimally, and I'd expect them to live their entire lives accordingly.
On the topic of "Choosing the best personality" - some people obviously have highly toxic or dark personalities. But from that person's perspective, I think that these often seem like the best bet for them. A dark personality makes you feel better about doing socially-looked-down-upon things. It seems edgy and cool to the right people.
And it's very possible that all specific seemingly-positive personalities one knows of are just inaccessible. For example, I could imagine an edgy teen where all examples of happy people around them were financially and personally privileged, and are kinda dumb (i.e., Mr. Peanutbutter in the show BoJack Horseman). Again, because it's so hard to change personalities, this could lead to a lot of negative lock-in.
Personality Menus and Innovation
An idea I've been considering: Similar to being able to choose the personality of an LLM, it could be interesting to offer a personality menu to colleagues. Like, "Please fill out this form. It says what kind of person I should try to be. Then I'll do my best to be that sort of person."
In theory there could be a "personality innovation" department, that figures out how people of different personality clusters can improve their behaviors.
I find it interesting that some personalities go along with very narrow communities. Like, it could seem bizarre for someone not gay to have a flamboyantly gay personality. This might mean that a lot of this personality type is inaccessible to others, even if parts are good.
Fiction and Personality Templates
One great thing that fiction does is to innovate upon and showcase different personality options. Like, "Here's a character who has an unusual personality. You can watch how this personality engages in different situations and environments. Some viewers could take parts of this and incorporate this themselves."
This both can be useful for people taking on the personality, and to make sure that these personalities are more well-known to others, making it a better draw for individuals who might take it on.
Other clear examples of how others respond to friends changing personalities: Imagine someone who always is in casual clothes changes to full suits one day. Or someone does the opposite. Or someone becomes a huge fitness bro, or a comedian, or incredibly serious, all of a sudden. I think there are a few sorts of personality changes that one's community would like, but many would be seen as strange and off-putting.
Like, "What happened to the person I knew, developed an understanding of, and made plans around? Now I need to rethink all of that."
A Rationalist Approach to Identity
People obviously identify a lot with their personalities. Changing one's personality can be considered as bad as dying or worse. Obviously, I'd lightly push against this. I think that it can be socially cooperative to not change one's personality (and thus it could also be seen as cooperative to even hate the idea of changing one's identity), but I take personality as a very pragmatic/matter-of-fact decision.
On personality as a practicality: I suspect that if people could be sure that certain personality changes would be better for them (and perhaps to their communities), they would frequently feel comfortable changing them. Or perhaps it's a topic they are uncomfortable with - but if they did change one day and things felt better, they wouldn't particularly mind.
Personally, I feel like I have a lot of pragmatic attachments with parts of my personality. But I wouldn't feel too bad dramatically changing it, if a strong enough expected value calculation would show that to be a good idea, and it wouldn't hurt those close to me much. (The math would work this way if it had large-scale altruistic value).
I suspect that a lot of human values are downstream of personalities. Like, I decide to be an altruistic independent research person first, then that leads me to think that I should be fairly high in honesty, even if it's hard to do a cost-benefit calculation to suggest that this is the locally-ideal trade-off.
I'll say, "I care a lot about honestly", but I might mean, "Given the personality I've been able to adopt, I feel most comfortable with this given level of honesty."
The Quantified Uncertainty of Personality
I'd bet that a lot of people's actions can be heavily predicted, with a bit of information about them, given how uniform mainstream personalities are. There's probably some science to the predictability of different people.
The Big 5 are a bit orthogonal to this. I see Big 5 as pre-personality, but it helps provide options of what your personality could be.
One thing that some health books recommend is to focus less on "doing specific healthy things" and more on "identifying more as a healthy person." From the latter, the former will be dramatically easier.
Closing Thoughts
I'd love to see more frank discussion on this topic (i.e., pragmatic discussions of identity, grounded in incentives). I think a lot of people find it off-putting and cold. But it's also a really important issue for people, and I'd expect that certain discussion could be productive.
I'm happy that there is writing in Psychology around it, but have found a lot of this to be too narrow and avoid the key questions as I see it. I'd imagine that authors like Robin Hanson and Robert Kurzban would do the sort of analysis I'd find reasonable.
What do you think? Do you see personalities as pragmatic investments or as something more essential? How much do you think our personalities are choices versus discoveries?
(I'll be writing more about this topic on the EA Forum soon with a more formal analysis. If you're interested in these kinds of quantified approaches to self-improvement, feel free to message me.)
Strongly Bounded AI: Definitions and Strategic Implications
AI · Apr 2025 · 2,067 words
Strongly Bounded AI: Definitions and Strategic Implications
Ozzie Gooen - April 14 2025, Draft. Quick post for the EA Forum / LessWrong.
Epistemic status: Exploratory concept with moderate confidenceThis represents my current thinking on a potentially valuable framing for AI safety, drawing on established engineering principles. In the last few years discussion around these topics has exploded - I wouldn’t be surprised if there were great existing works that I don’t know about and can’t quickly find.
—
I feel the AI safety conversation lacks terminology for limited, safe, and useful AI systems that address takeover risks rather than misuse by humans. This concept goes beyond alignment to include capability restrictions, reliance on established technologies, and intelligence limitations for predictability.On the Terminology
One thing I feel is missing from AI safety conversations is strong and versatile terminology for limited, safe, and useful AI systems.
This concept isn't just about alignment. It's also about:
- Substantial capability restrictions (using older models, strong compute limits)
- Exclusive use of highly-tested and well-established technologies
- Intelligence limitations that make behavior highly predictable
I think some potential names for these systems could be:
- Strongly Bounded AI
- Highly-Reliable AI
- Boring AI
For the rest of this document, I’ll go with “Strongly Bounded AI.”"Strongly Bounded AIs" are not necessarily ones with substantial alignment or safeguards - but rather, AIs we can reason to not represent severe AI takeover risks. This means they can either be very weak systems (like many of the systems of today) without safeguards, or stronger systems with a much greater degree of safeguards.
We already have somewhat understood areas of "Control," "Scalable Oversight," etc., which approach similar ideas. But I believe these systems typically investigate "specific AI layers directly overseeing risky AIs" rather than broader AI services/agents that are doing more regular duties in the world.
We also have the fields of “Comprehensive AI Services” (see Drexler) or Guaranteed Safe AI (See Davidad). These are closer to the idea I’m proposing, but are more specific. I think neither is necessary for “Strongly Bounded AI”.
A “Bounded” AI is also arguably different from an aligned or a safe AI. Both “aligned” and “safe” at this point have fairly broad and imprecise definitions, in comparison. I’d also flag that “Boundedness” is really about accident risks, not mistake risks. A bad actor could use a bounded system to do significant harm. This is akin to the importance of reliability in military technology - such reliability is useful for the military, but obviously can still be used destructively if desired.
Engineering Culture and Established Patterns
In tech companies, there's an established virtue of using "boring tech" – Postgres, SQL, REST, etc. There's always something fancier trending on Hacker News, but these cutting-edge systems come with major uncertainties and liabilities. Typically, new programmers enthusiastically advocate for the latest JavaScript framework while experienced engineers spend time arguing for proven technologies.
Engineering also features many well-understood and distinct subfields for highly-reliable systems: "Fault-Tolerant Systems," "Ultra-Reliable Systems," "High-Assurance Systems," "Formal Verification," etc. I believe these concepts effectively carve out market positions for unusually secure technology. Major software products like Microsoft Windows or Google Docs don't advertise themselves as "Fault-Tolerant Systems" or "Formally Verified" – these terms are reserved for genuinely reliability-focused systems. While these terms can function as marketing buzzwords, I think they still help establish meaningful categories.
Current State and Future Potential
I think most AI agents today are weak and highly limited. I don't expect 99% of them could cause catastrophic damage (say, $100B in damages) anytime soon – the technology is simply too weak and expensive. I'd feel fairly comfortable using many current systems without worrying about major alignment risks.
My strong expectation is that a tremendous amount of good and global stability could come from developing "Strongly Bounded AIs." And perhaps most importantly, I think the game plan should entail using "Strongly Bounded AIs" to help us reason about, develop, and control cutting-edge AI technologies.
I believe the real AI takeover threat comes from frontier AI agents. I think the capability gap between frontier models and our controlled AI systems represents the potential damage frontier AI could cause. If it's "a powerful malicious frontier AI agent" versus humans alone, there's a massive potential for takeover. If it's the same agent versus "robust, reliable and controllable AIs," I'd feel much better about our defensive position.
Applications and Evolution
Over time, I think we'll develop better methods for creating "Strongly Bounded AIs" that push the frontier of effectiveness while maintaining safety. One of the main things we should probably do with cutting-edge AIs (to the extent we use them) is to help us create better "Strongly Bounded AIs."
What could "Strongly Bounded AIs" do? In my view:
- Oversee personal data on devices
- Make strategic recommendations for organizations
- Secure key resources beyond traditional access management (e.g., AI monitoring bank withdrawals for signs of duress)
- Handle bounded high-reliability operations in medicine and defense
- Assist auditors examining potentially dangerous organizations/systems
Addressing Common Questions
"Doesn't delegating to AI systems increase takeover risks?" I think this is an oversimplified view and would often argue the opposite. I'd expect that "Strongly Bounded AIs" could make the world much more secure against frontier adversarial AIs, not less. But of course, one would need to implement smart tradeoffs.
"Isn't opposing frontier AI while supporting limited AI confusing?" I think engineering has a long history of distinguishing between safe and unsafe technologies. I don't think the difference between AI systems is unusually strange compared to previous work in reliability engineering and computer security."Won't this term become meaningless marketing?" I'm not that cynical. I think safety-minded people should develop clear standards for safe systems, then work to form the language. We already have some terminology for highly-trustworthy technology. Even when one term gets semantically diluted due to marketing, others can emerge to take its place.
Ultimately, we want systems where:
- We are strongly able to predict their behavior patterns.
We can have assurances that the downside risks to using them are minimal.
Other unique bits
A few points from a rougher second pass of this draft, not covered above:
- It depends on trusting those in power. There are, of course, many ways one could mess up such a strategy — so promoting it depends partly on how reasonable one expects those in power to be.
- Framed as objections: "Isn't this just Drexler's Comprehensive AI Services?" and "Isn't this just Davidad's Guaranteed Safe AI?" — both are close, but I'd treat each as one possible (and not necessary) route to a Strongly Bounded AI rather than the whole idea.
- Strongly Bounded AIs could also act as assistants to auditors of dangerous organizations or systems (cf. "superhuman governance").
Epistemics: An Early Guide
Epistemics · May 2025 · 2,532 words
Epistemics: An Early Guide
Meta:
This is meant as an example of an index to a book/course/etc on epistemics. The goal is to represent a comprehensive take on what materials are useful to improve epistemics.
This represents my opinionated take on what the field could be.
This obviously is very much lacking. There’s little on community/organizational work, there are very few mentions of relevant literature. I’d flag that this is inspired heavily by the Rationalist/EA scene.
This covers a great deal of ground. That’s much of the point. This is an early project, we want to lean on making sure that potentially useful things don’t get missed.
Trying to go into depth on each bullet here would take ages. LLMs and independent study could help a lot here. The goal is to provide a high-level take on useful areas for people to investigate using other materials, not outline a textbook to try to comprehensively cover each area.
Opinions welcome! I’d like to spend some more time on this, then post it online.
–
Theory
- What is epistemics?
- “Being correct about things, particularly when being correct is socially difficult.”
- “The effectiveness of a person or team on finding valuable information.”
- There’s a history of the term “Epistemology”. It should be clear where the term “epistemics” came from and who uses it.
- What philosophical background will we use? (“Epistemic optimization” vs. “Epistemology”)
- Different schools of thought would understand epistemics in different ways. We will draw heavily from:
- Bayesianism
- Empiricism
- Economics, particularly Information Economics
- Management Theory
- Analytic Philosophy, as opposed to Continental Philosophy
- What would better epistemics do?
- Hedge funds with better epistemics would make more money. They would better prioritize projects and remove outdated takes.
- Policy advisors with better epistemics would improve policy quality.
- Individuals with better epistemics would generally be more confident about many potentially-contentious issues in their lives.
- Broadly speaking, epistemics should help improve decision-making at scale, leading to benefits whenever humans are involved with things. It’s also likely to significantly improve coordination.
Examples in various fields
- Judgemental Forecasting
- What practices do top forecasters use?
- Understand Accuracy, Calibration, Scoring Rules, Prediction Markets, etc.
- This area acts as a good microcosm of optimizing epistemics.
- Finance
- Which hedge funds and market firms represent the big-picture best reasoners? What are those groups doing?
- What information do hedge funds pay for? Why do they seem to pay for large databases, but not much for subscription journalists or analysts?
- Philosophy
- Cover the philosophical schools of thought underlying Bayesianism/Empiricism/Analytic Philosophy.
- Journalism
- What skills do top journalists use?
- What are the main challenges faced by journalists / journalism?
- Why is there so little money in Journalism? What can be done to change the incentives?
- History
- What are examples of those in power, or the masses, attacking the truth? For example, limiting speech, restricting education, criminalizing dissent, surveilling communication? How well do these follow common patterns?
- Moral Situations / Advocacy
- How successful were Truth and Reconciliation Commissions in history?
- What are examples of countries/situations that probably should have had Truth and Reconciliation Commissions, but didn’t? Why didn’t they? How expensive would these have been?
- How does one speak “Truth to Power?”
- Business
- Many successful entrepreneurs (i.e. Steve Jobs, Elon Musk) are remarkable at making some decisions (marketing, product), but dramatically overconfident in other areas (i.e. their product successes). Why is this?
- How does groupthink impact key organizational decisions?
- Politics
- Why do dictators frequently fall into conspiracy theories?
When True Knowledge is Inconvenient, Or False Knowledge is Convenient
One major epistemic challenge comes when knowledge of the truth happens to be inconvenient for some set of actors. Arguably most accessible “convenient truths” have been picked, but the “inconvenient truths” are frequently pushed aside. This creates an environment where truth-seekers frequently run into “inconvenient truths”.
In these cases, much of the bottleneck of spreading information will be about how to work with or around the actors who would prefer it not being spread.
Examples include:
- A government that wants to hide corruption
- A religious order that wants to hide logical problems with their belief
- Software companies typically want to hide information about security breaches, to the extent they can legally do so
- A parent who hurt their child but doesn’t want to admit it to themselves
- A professor who held their field back 10 years but won’t admit it
- A person who thinks of themselves as highly altruistic but is actually quite harmful
- Much of the world has “status quo bias”, or inertia to change. Truth can get in the way of this. For example, say that new scientific metrics would come out that would somewhat accurately estimate the global value of each work of science. I’m sure any attempt at this, especially decent and trusted attempts, would upset a great many people.
There’s no one “rulebook for advancing inconvenient knowledge.” But there is a lot of material on different aspects of this.
- Journalists have a lot of experience fighting power figures who don’t want certain work published. This involves a mix of [carefully understanding what would upset which people] and [being prepared to fight, when things get adversarial.]
- Lots of work around moral advocacy. For example, people promoting animal welfare often run into the issue that a lot of their educational work involves making people understand the moral downsides of their actions. This is a clear inconvenience for these people. Similar for most other forms of moral advocacy (racism, environmentalism, etc).
- Therapy, particularly around difficult conversations. Many patients don’t want to admit many key things about themselves. Getting them to do so can require a great deal of empathy, patience, practice, and skill.
- In business, many people have challenges giving honest critiques to each other. This can be quite delicate. Bosses are often mediocre at being both honest and empathetic to their subordinates. And many businesses are poorly set up to allow subordinates to relay important information to superiors.
- Different cultures vary in how candid they are.
It should be noted that the above include examples of true knowledge that would be inconvenient to a certain party, but likely convenient/positive overall. There are also a lot of cases where true knowledge would likely be bad on the whole. For example, areas where privacy is net-valuable.
- Often, certain privacy enables property rights. If passwords couldn’t be kept public, that would result in a lot of economic damage.
- A political dissident wants to hide their work from the public or the government.
- A person gets involved in a small scandal that would become dramatically misunderstood if made public.
- A person wants to sell their work online, but if it gets distributed for free, they couldn’t do so.
This means that “promoting inconvenient truths” is sometimes pro-social and sometimes anti-social. There are critical disagreements on which cases are pro-social and which are anti-social. (Obviously, inconvenienced parties will typically think and argue that such knowledge is anti-social)
Tools For Convenient Lies
Many tools that can be used for spreading truth can also be used for spreading falsehoods. But some differentially prefer falsehoods. Here we try to focus on the latter.
Motivated Reasoning / Self Deception (Personal, Unintentional)
Motivated reasoning has been extensively studied and outlined.
One interesting question is to study where and when it’s useful to the offending party.
“Being yourself wrong about things” can be pragmatic and useful, but it can also be easy to overshoot. In general, this seems like an incredibly difficult thing to get right.
If “convenient and unusual falsehoods” were a product, it should come with major warning signs. “Using this product is likely irreversible. After using it, the world will make less sense to you and many of your plans won’t work as well as you envisioned. This product is known to be highly addictive.”
Egos (Personal, Unintentional)
It’s clear that many people greatly overestimate their own abilities. This is one of the clearest and largest human biases. Oversized egos lead to untruths, and untruths lead to all the tools of spreading untruths.
As is the case for other reasons for convenient lies, overly large egos carry a bunch of personal advantages. This can be useful for both personal motivation and for convincing others.
There’s a decent amount of literature on narcissism, which is a clinically diagnosed, but particular form of “having an outsized ego.” Narcissism is known for being incredibly difficult or impossible to recover from.
Sycophancy (Group, Unintentional)
Knowledge of convenient falsehoods is often kept alive with large amounts of sycophancy.
- Executives and politicians who surround themselves with yes-men.
- People with inflated egos, who marry significant others who go along with it, and sometimes force their children to go along with them. This can lead to a deep web of falsehoods.
- AI models are clearly sycophantic.
- Journalists will focus on narratives where their readers are positive and morally standing, and people who their readers don’t like are bad. Most people live in ecosystems that are optimized (largely unknowingly, a la market pressure) to not challenge them.
Sycophancy is often fairly unintentional.
Epistemic Capture / Marketing / Propaganda (Group, Intentional)
Epistemic capture refers to the use of force by those in power to spread beliefs that are convenient to them. This is often done with intention (spreading this false knowledge), though in different situations those in power might themselves believe this false knowledge or not.
- Rulers who spread (frequently effective) propaganda
- Business marketing schemes that wind up convincing people of broad things
Arguably, these are broadly the same techniques as are used for spreading true information. Many of the best marketing techniques are equally effective in spreading both true and false information.
Attacks on Truth-Promoting Parties (Group, Intentional)
Agents trying to proliferate untruths will often come into conflict with truth-promoting parties. For example:
- Governments frequently get frustrated by journalists
- Conspiracy theorists have to argue against academics
- Populists commonly attack “the elite”
- Intellectuals with unique and strong positions often form attacks against most other intellectuals
- Street gangs will promote distrust of the police/authorities
- Scientology has a massive beef against psychologists. One reason was that they argued that their techniques solved many issues of psychology, and psychologists disagreed. So it made sense for them to discredit psychologists, for their followers
- Pundits who disagree with prediction markets, but get asked about it, will often come up with various (typically false) attacks on these prediction markets.
These attacks can range from light verbal arguments to extreme violence, depending on the situation.
Obviously, this also means that it’s a red flag when someone is attacking truth-promoting parties.
Epistemics of Conveniences and Morality
One critical aspect of researching conveniences and information is that it requires certain moral stances to be taken.
A lot of epistemics can arguably be done without getting into morality. For example, there are a lot of tools that will help a mathematician do useful work faster, or a business find insights more quickly.
Once inconveniences get involved, that changes. People will get hurt. It might well be for the better, but it does involve a degree of uncomfort or pain.
Many technical researchers enjoy staying away from moral issues. But on the flip side, this neglectedness could mean that some of this area is more cost-effective, for those willing to engage with these topics.A large silver lining is that “discussing the theory and mathematics of fighting convenient falsehoods” is typically much less controversial than “directly fighting convenient falsehoods.” Being meta has its benefits.
Epistemics for Individuals
- Common failure modes
- Incentives & Costs
- Motivation (A person is externally motivated to be incorrect about an issue)
- Can we develop methods of measuring the benefits that individuals get from believing things, outside of their truth status?
- How well do people’s choices about what to believe reflect their basic incentives? For example, if they can choose to be accurate or inaccurate on an issue, will they make those decisions solely with their personal welfare in mind?
- Ego (A person is highly and systematically overconfident because of a large ego)
- Is it possible to dampen outsized egos?
- See narcissism.
- When is learning “painful”?
- For example, a person finds out that they were a bad parent, or that their mistake has led to devastating consequences.
- How can we understand tradeoffs between accuracy and pain avoidance?
- What tradeoffs happen in practice? What tradeoffs should happen? (Descriptive vs. normative)
- Can we quantify the human labor required to update a person’s opinion to a certain degree, especially when doing so comes with emotional hurting?
- Trauma & Signaling
- How much are people’s beliefs reflective of personal traumas they have experienced, or that were passed down.
- Looking at beliefs as a way of signaling miscellaneous information. I.E. “I believe in Hitler, because I want to signal that I’m deeply angry.”
- Failure scenarios
- Logical Fallacies
- Cognitive Biases
- Failures in the use of language (i.e. Pragmatics, late Wittgenstein)
- Basic Tools
- There are many tools in one’s toolkit for understanding the world. Strong reasoners should have a skilled understanding of each. Each tool comes with its own pros and cons, these should all be understood.
- Tools:
- First-principles Thinking
- Basic Qualitative Methods
- Empathy
- Basic Quantitative Methods
- Evidence of Historic Use (“The fact that a practice has endured provides some evidence for its effectiveness”)
- Burkean Conservatism
- Chesterton’s Fence
- Evidence of Popular Use
- What are top companies and startups using?
- Scientific Analyses
- Expert Opinion
- Power Tools
- Advanced quantitative methods
- Fermi Analysis
- Advanced Qualitative Methods
- Advanced diagrams of decision-makers, reasoning, etc
- Discernment
- Using AI, now in in the future
- Balances (Things you want to do at the right amount)
- Agreeableness. You want to be disagreeable enough to be interesting, but not overconfident. This is tough to get right. You want to be a combination of being [right when others are wrong] and not [wrong when others are right].
- Candidness. You want to convey information, but at the same time, it’s easy to be too candid in certain situations.
Epistemics for Collectives
- Effective communication
- How do different techniques fall in terms of being effective, and in terms of being truth-seeking?
- Start with the “Basic Tools” listed above.
- Add in marketing/messaging techniques. Such as:
- Emotional appeals
- Memes
- Sarcasm
- Clever headlines
- (This is tricky to neatly categorize)
- Community culture
- How candid is a certain culture? How does it rank on Power Distance?
- Cultures low on candidness will have higher communication costs for uncomfortable topics.
- Is this changeable? Yes, to some degree.
- Bonus topic: How to make uncomfortable information less scary.
- Epistemic Capture
- How do those with power control others beliefs?
- Community sophistication
- Do community members understand enough about mathematics/epistemics/philosophy/etc to make use of advanced reasoning techniques?
- Playbook for “Handling difficult conversations”
- Incentive systems
Evaluations (particularly, Systematized Evaluations)
(There’s a whole lot to say here, might add later)
Epistemic Capture
Epistemic Cooperation
Epistemic Dominance
Epistemic Risks
Epistemic Dynamics
- Epistemic Lock-in, vs. change.
- When do communities lock-in false beliefs? When do they change? How can we get them to change?
(Re)defining Bullshit
Epistemics · May 2025 · 1,826 words
Summary
The term "bullshit" appears promising for epistemics / rationality work due to its familiarity, but ultimately proves too imprecise for serious analysis.
While Frankfurt's definition (indifference to truth) and Galef's*soldier mindset* offer starting points, they're overly broad; capturing many useful communications that happen to be truth-apathetic.I introduce two frameworks to attempt formality: (1) accuracy impact analysis that categorizes communication by whether it improves or reduces audience correctness, and (2) evidence strength gaps that quantify the ratio between implied and actual evidence quality.
It seems like "bullshit" itself may exemplify the problem. It’s an emotionally charged term with unclear definitions that implies significant conclusions while operating on minimal evidence.I conclude that bullshit can be used for certain wide-scale communication, but that readers should quickly be introduced to better terminology when doing serious research work.
Motivation
Epistemics remains an unfamiliar term for most people, while "bullshit" enjoys broad recognition. Since quality epistemics often involves "avoiding or removing bullshit," framing epistemological work around bullshit elimination could prove strategically valuable.
Consider potential titles like "A Systematic Offensive Against Journalistic Bullshit" or "Bullshit Hunting: A Guide" versus academic-sounding alternatives using "epistemics." The accessibility difference is stark.
This raises a crucial question: Can we define bullshit in ways that are both intuitive and carve reality at meaningful joints?
Definitional Challenges
The most obvious definition to begin with is that of Harry Frankfurt's influential 1986 essay "On Bullshit", which was later republished as a popular book in 2005. Frankfurt's work represents a philosophical attempt to define bullshit, and his analysis has become a standard reference point for academic discussions of the concept.
Frankfurt opens his essay with an observation: "One of the most salient features of our culture is that there is so much bullshit." Yet despite this ubiquity, he notes that "the phenomenon itself is so vast and amorphous that no crisp and perspicuous analysis of its concept can avoid being procrustean." Frankfurt acknowledges the inherent difficulty of his project, explaining that "the expression bullshit is often employed quite loosely - simply as a generic term of abuse, with no very specific literal meaning."
Frankfurt's central thesis distinguishes bullshit from lying based on the speaker's relationship to truth.
From Wikipedia’s summary of On Bullshit:"Frankfurt determines that bullshit is speech intended to persuade without regard for truth. The liar cares about the truth and attempts to hide it; the bullshitter doesn't care whether what they say is true or false."
I think this is a decent start, but isn’t very precise.
Related is Julia Galef’s work on mindsets. Galef defines the scout mindset as "the motivation to see things as they are, not as you wish they were" while the soldier mindset involves "motivated reasoning to defend one's existing beliefs."
So, is bullshit just anything that comes from the soldier mindset?
I think that one complicating factor is the audience’s standards for evidence. If the audience has high standards, then a process aimed at convincing the audience will also inform them in useful ways. A person with a soldier mindset would recognize that they need to approximate a scout mindset in order to accomplish their mission. This would represent a healthy alignment between the motivations of communicators and the correctness of the beliefs of the audience.[^1]
Or, stated differently, I think Harry Frankfurt’s definition of bullshit might be too broad to be very useful. I think there are many cases of truth-apathetic arguing that are still useful and wouldn’t be classified by most as bullshit
Ostentive Examples
When confused on definitions, it’s often a good idea to get precise. Let’s go through a few examples. I’ll grade each by how much like “bullshit” it naively seems.
| # | Example | Is it Bullshit? |
|---|
| 1 | WW2 Military Propaganda | Definitely bullshit |
| 2 | A political party using high-level moral claims to attack the other | Likely, mostly bullshit |
| 3 | Correct and novel math proofs | Definitely not bullshit |
| 4 | A novel defense of a (false) religion, from someone who genuinely believes that religion and in the argument | I wouldn’t consider this bullshit. Though this would be complicated if this person was themselves convinced of the religion using bullshit arguments. |
| 5 | That same religious defense, but by someone who doesn’t believe in the argument, and is just using it to convince others | I’d consider this bullshit |
| 6 | A parent tries to teach their kid about moral principles. But their specific arguments are clearly motivated and poor. | I’d consider this bullshit. I assume many wouldn’t, but I would also assume these people wouldn’t just because they do it themselves and don’t want to be associated with bullshit. |
| 7 | A certain WW2 propaganda poster that is later studied in academic departments as a great case study of propaganda | The direct message of the piece is bullshit, but what people can learn from it is not bullshit. It’s basically interesting by accident. |
| 8 | A historian has made a strong stake in supporting a certain theory. They later find and write a bunch of arguments that support their theory. When doing so, this person doesn’t at all care about the truth, but they do want to convince people, so they use the bare minimum acceptable intellectual standards to make their points. But this work then still goes on to be valuable - it turns out that some of their research was genuinely interesting and relevant. | I’d consider this as “having amoral intentions, but producing good work, as a happy accident.” Not bullshit, even though this person would have been happy to produce bullshit in other situations. |
Framework 1: Accuracy Impact
We can distinguish between accuracy-improving and accuracy-reducing information based on whether audiences become more or less correct about matters important to them. This shifts some focus from speaker intent (which is often unknowable) to measurable outcomes.
Technically true information can still reduce accuracy through misunderstanding, misleading implications, or missing context. Consider carefully selected anecdotal evidence that supports a false general pattern, or precise statistics presented without necessary context about their limitations.
We can combine this with scout and soldier mindsets, into this simple table.
| | Audience Impact | |
|---|
| Communicator Intention | | Accuracy Reduction | Accuracy Improvement |
| Scout Mindset | Good Faith Accidents | Good Faith Information |
| Soldier Mindset | Bullshit | Aligned Persuasion |
I think this is a decent spot that matches a lot of the intuitions people have of bullshit. It sort of matches the examples provided above. But I don’t think this framework is perfect. It’s meant to help us describe how people use the term, not to be a prescriptive and final definition.
Framework 2: Evidence Strength Gaps
A potentially superior approach focuses on the gap between real and implied evidence strength, avoiding problematic reliance on unknowable intentions.
Most concerning bullshit that I can think of features dramatically insufficient real evidence for the assumed confidence:
- Startups making civilization-scale claims ("We're helping humanity become a multiplanetary species") backed primarily by science fiction references and handwavy analogies
- Political parties hyping minor scandals as existential threats without consulting relevant experts or providing proportional context
- Propaganda films presenting carefully curated evidence for sweeping conclusions while omitting obvious counterevidence
- Academic papers that oversell preliminary findings through aggressive language while burying limitations in technical appendices
While evidence gaps don't perfectly correlate with bullshit, they frequently accompany soldier mindset approaches and create misleading effects that researchers should monitor.
This framework aligns with Bayesian thinking about evidence strength and belief updating. The key insight is that bullshit often involves presenting weak evidence (low likelihood ratios) as if it were strong evidence, leading audiences to update their beliefs more dramatically than warranted by the actual information content.
If we wanted to formalize this as bullshit, we might use:Bullshit Coefficient = (Implied Evidence Strength) / (Actual Evidence Strength)
Values significantly greater than 1 indicate problematic communication that inflates evidence quality. Values near 1 suggest honest communication about evidence limitations. Values less than 1 might indicate excessive modesty or strategic underselling.
This quantitative approach could enable more systematic analysis across domains. Academic papers could include evidence strength assessments alongside their conclusions. Journalism could adopt transparency standards about source quality and uncertainty levels.
The framework also suggests practical detection methods. Bullshit often exhibits characteristic patterns: confident language paired with weak methodology, broad claims supported by narrow evidence, complex phenomena explained through simple stories, or urgent calls to action based on preliminary findings. This seems like the sort of thing that Large Language Models could help hunt for and distinguish.
Final Assessment
In retrospect, I think that a lot of use of the term “bullshit” is probably bullshit. Bullshit is a highly charged word with what seems like a hard-to-pin-down definition. It comes with large implications, but is often used with minimal evidence.
I find it easy to imagine people using the term bullshit on claims they don’t like. But I’d expect that any precise and meaningful definition and use of the term would call out these exact people’s valued beliefs as well. And it seems safe to expect people to get defensive when their own beliefs are called bullshit.

So we have a term that’s widely-known, yet difficult to pin down and perhaps dangerous (in that it gets used for bullshit) when used by the wrong people.
Going forward I personally plan to continue to use the term in a limited capacity, especially when communicating to audience members who would have trouble with terms like epistemics or rationality. But I expect that it’s best to quickly bring discussion to focus on other terminology where possible.
—
[^1]: Practically, this sort of alignment happens when: The audience has a strong interest in being accurate Claims are easily verifiable (i.e. simple math proofs) There are resources to help verify claims (i.e. competent journalists or academic reviewers)
Types of Checks
Epistemics · Aug 2025 · 478 words
| | Importance | Challenge | Subjectivity | Frequency |
|---|
| Link Status Check | Does the link exist? (It could be hallucinated, a mistake, or a dead link)Extra: If it fails, it would be nice if we could have a simple AI agent who would try to search and find it.Challenge: Many websites block bots, so it can be surprisingly difficult to check the website. | Low | Low | Low | High |
| Link Relevancy Check | Does the link have the basic content it is implied to have? This can be quite tricky to validate. Many links aren’t to the direct source referenced, but instead a related website, after which the user is expected to find the source. Ideally we’d have a simple agent run a few steps to investigate. | Medium | Medium | Medium | Medium |
| Credibility Checks | Are sources of credibility cited in the piece actually as credible as implied? This will likely involve doing some digging. Also applies for cases where it’s claimed that a credible source said X, but they only technically said X. It probably would be good to have a long-lasting list of different sources and their general credibility ratings. A more advanced version would have audience-dependent credibility standards. | Medium | Medium | High | Medium |
| Spell Check | Not too hard to do a basic job. LLMs can be a bit more advanced. One challenge is choosing UK vs. US English. | Low | Low | Low | High |
| Grammar Check | Similar to spell check, but can be more subjective | Low | Low | Medium | High |
| Markdown Formatting Check | Is the item formatted correctly? This can be messy, as different websites format MD differently. I think this isn’t a major concern for content written by humans, but it seems like something to check when it’s by LLMs. I think LLMs often get MD wrong. | Low | Low | Low | Medium |
| Name check | Are all person/place/etc names in the doc correct? Are they correctly spelled out? This often will require some searching. Bonus points if you can return a relevant link in each case. Wikipedia is the gold standard, other pages can also work. | Low | Low | Low | Medium |
| Math Check: Arithmetic | Are all simple (i.e. not advanced math) equations in the doc correct? This can ideally be verified with a formal math equation. | Medium | Low | Low | Medium |
| Math Check: Advanced | Check if advanced math has issues.One major challenge with doing this is context -> Many descriptions of math might reference key previous parts. There might be awkward branching with several strands of thought. Ideally this could be formally checked with Python or similar, though this is often fairly slow. | Medium (Used on LessWrong a fair bit) | Medium | Low-Medium | Medium |
| Editorial consistency checks | Does the document follow consistent standards? Are there any clear issues, like points made multiple times? | Low | Medium. Difficult to do | Low-Medium | Low (Most blog posts are consistent, longer docs less so) |
Probability from a Perspective
Forecasting · Methods · Dec 2025 · 659 words
Probability from a Perspective
The two most common understandings of probability are the Frequentist interpretation and the Bayesian one.
The frequentist one can be summarized as:“For any uncertainty, there is one true universal probability for it.”
While the Bayesian one says something more like:“For any uncertainty, you have to begin with the prior of a certain person.” And yet, a lot of Bayesian analyses won’t make the results customizable for specific individual. Often the answer is to use an “uninformative prior” or to provide the prior of a certain party of experts. This can be a decent approach when the tooling is basic (doesn’t allow great infrastructure), but is clearly lacking. I’m in the Bayesian camp, and would like to take things a bit further. I think that a useful framing is to contextualize probability coming from a certain perspective.Two players are playing Texas Hold-em. One has two aces, one two 5s. A 5, 8, and 10 are put on the table. What are the chances that the next two cards will include another 5?
From the perspective of the universe, either 0 or 1. The cards are ordered, it’s a matter of physics. This is not a particularly interesting answer.
From the perspective of the first person, roughly X. From the second, roughly Y. You can further customize a function to say, “For any Perspective X, where said perspective knows the down cards plus one or two cards A and B, what would they consider the chances of another 5 being?”
Here the “bayesian prior” isn’t some fuzzy feeling. It’s a straightforward outcome of the fact that different people, at different times, have different information.
I have a lot of uncertainties about greater philosophical questions regarding objective probabilities. But in real use cases, most probabilities I come across make most sense to me when discussed as coming from a certain perspective. What are the perspectives? Well, each person clearly has some perspective of their own. One might define some perspectives like, “The perspective from the view of a hypothetical being with all knowledge of the universe in its current state”. This perspective would be uncertain about future quantum events, but would have certainty about the card example.
Often, it’s useful for a group of people to settle on some group perspective. White it would be great to have a custom calculator that each person could individualize, it’s sometimes easier to have one “good enough” number. But how should this work, given that each member is different?
For this, tips such as use an “uninformative prior” or an “expert panel” make more sense. But hopefully it’s more clear what’s going on. We’re not trying to estimate some “universal probability”. Instead, we want to estimate something like a “certain perspective that represents our group”.
There are rigorous examples. A simple way to do this would be to imagine the Perspective of the Group being the probability one would give, using information that everyone in said group shares. For example, if two people are playing cards, one has a 5 and a 9, the other a 5 and a 10, then you’d take the probability using just the 5. (This assumes they can’t share/trust information, which is often reasonable!)
What is this useful? It’s a formalization of what probability means and how to use it at scale. Say we have an AI estimating odds for people. What does that mean? One thing we could do is that when we show one person the answer, we customize the odds to represent the estimated enlightened beliefs of that person. And if we show the results publicly, we might then provide them in the context of a certain defined Perspective.This all seems very straightforward and obvious to me. I’m frustrated that I haven’t seen much other work that gets at this concept.
Project CAIRN: A Longtermist Wiki Project
AI · Jan 2026 · 1,504 words
CAIRN: Comprehensive AI Impact & Risk Navigator
Using LLMs to make an extensive longtermist wiki, focusing on generating strategy insights
Ozzie Gooen, The Quantified Uncertainty Research Institute
LLMs have recently become able to produce compelling research reports and build complex software. So far this has been slow to translate to much better longtermist prioritization.

How can we convert Claude Code into better decision-making? It's unclear what the exact best approach is, but there are several somewhat-obvious steps that could be useful:
- Gather the relevant information.
- Build knowledge graphs of critical longtermist factors.
- Make lists of potential cruxes / key questions.
- Provide rough estimates of a great number of key variables. For example, rating hundreds of interventions in terms of neglectedness/importance/tractability.
- Brainstorm new intervention ideas, especially in high-prioritization areas.
- Make strong interfaces both for public use and for LLM use.
It can be very easy to get overwhelmed by overzealous approaches. But one nice thing is that this can be done very iteratively. We begin with a small wiki, and gradually add more and more scale and complexity. We suggest a lean approach, where we attempt to iteratively publish. We already have a basic tool that does an introductory job on these tasks.
This is an experiment to see whether LLM-assisted research infrastructure can surface non-obvious insights at a cost/speed that traditional research cannot match.
Current Status
We have a basic, highly-experimental prototype here. This used Claude Code for almost all writing and estimation. I think this can be useful as an experiment, but note that it is very messy right now.
A Scalable Hunt for Critical Insights
It can be easy to spend a lot of effort researching a topic with little to really come from it. For example, many mathematical models might be highly accurate and technically detailed, but not lead to decision changes.
We can label a "Critical Insight" for a research finding that is a good mix of being surprising, important, and simple. We can estimate all of these with LLMs.
- Surprising: Do LLMs dramatically update their beliefs when they get this information?
- Important: Is there a strong argument that this information is on a crucial topic?
- Simple: Is this argument easy to defend?
High-quality critical insights include things like:
- The importance of X-risk: "If something kills everyone in the world, that would be catastrophic. It's easy to argue that current cost/benefit analyses would highlight such interventions."
- Concrete intervention ideas:"We've found that there's a certain cluster of politicians in Germany who are unusually important and unusually influenceable. We have evidence for this that's been extensively critiqued by different AIs, and seems robust."
- Surprising & Actionable Research: "When investigating organization X, we found clear and straightforward evidence of extreme fraud."
LLM-generated knowledge bases can become enormous quickly. It's critical to focus on providing real value that can be very simple to convey. This is useful both for LLMs (which have limited context windows) and for humans (who have limited time and attention).
A "Hunting for Critical Insights" strategy would likely involve a lot of experimentation and prioritization. This would generate a great deal of data for the AIs to navigate, but many of the outputs could be very simple.
You can see a current dashboard of these here.
Building Blocks
A project like this can be decomposed into a series of concrete outputs that can be created using LLMs. Each output type would require its own tweaking, evaluation procedure, visualization, and prioritization.
Deep Research
For a certain topic, produce an extensive research report. LLMs are already quite good at this. Several products for "Deep Research" exist, though few provide API access. Common challenges include things like minimizing hallucinations, and scaling this so that research work doesn't get duplicated when researching similar topics.
High-Level Models
Having a long list of topics can quickly become overwhelming. To assist, it's useful to have some key models. These generally contain important concepts/terminology, with assumptions about how they relate to each other. Below is one example.
These models would likely require some of the greatest human assistance at this stage. They are very high leverage, as once you have a good one, it becomes doable to have LLMs automate a lot of research on them.
As we get concrete models like these, we can then use estimations to figure out what longtermists might want to prioritize.
Factor Maps
For any parameter in question (e.g., "Total probability of catastrophe from 2026 to 2030", "US Energy Production in 2026 to 2030"), generate a multi-layer network of contributors. Estimate the matrix of all interactions. This would take in the output of Deep Research.
Further work would go into ensuring that all influence diagrams don't have redundancies with each other. One way to do this is to occasionally synchronize them with one super-diagram of all of the sub-nodes. This way we could ensure that we don't need to duplicate research, for example in the situation of one sub-node that's present in multiple influence diagrams.
https://ea-crux-project.vercel.app/diagrams/misalignment-potential
https://ea-crux-project.vercel.app/diagrams/master-graph?full=true&level=detailed
Large Tables
We can organize much of the work into large organized tables. This is helpful to test semantic data specific to specific kinds of data.
Some examples:
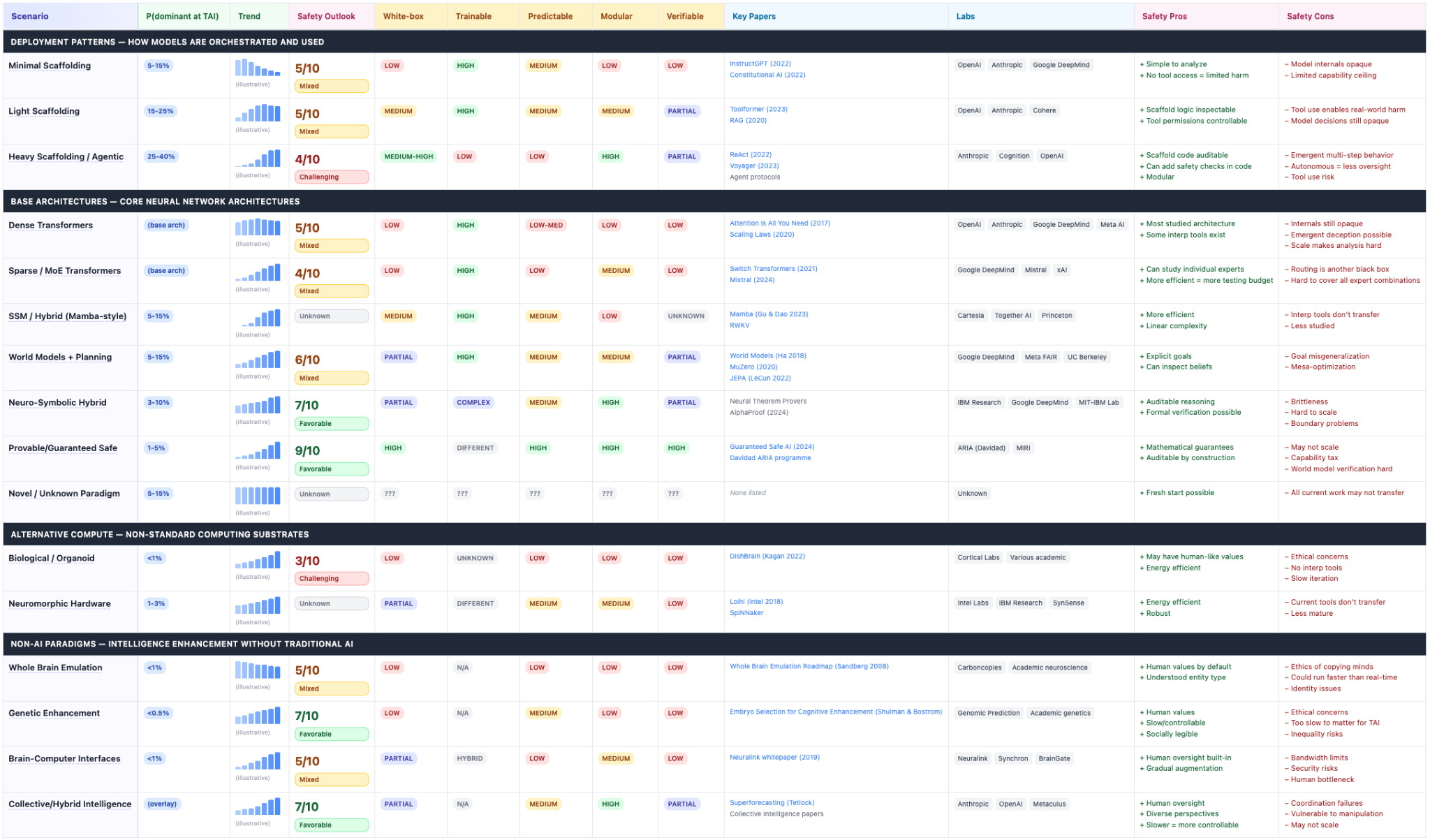
Structured Data
Deep Research is useful for putting together wiki-style writing on important topics, most of which is long unstructured text. In addition to this, we'll want to organize a lot of structured data. Different types of data will require different functions for retrieval.
Putting together a full comprehensive structured repository of long-term information can be a great deal of work. There are already some organizations working on this. So for this project, we'll focus on the essentials.
Some relevant types of structured data include:
- Publication information. For all research documents of interest, put together information about the authors, citations, publication, etc.
- Organization information. For each important organization that's relevant to longtermism, organize some basic data (people, outputs, board members, etc).
- Relevant legislation. For relevant AI/bio/nuclear legislation, gather relevant links/authors/etc.
Controlled Vocabularies & Categories
Such a project will likely require thousands, if not hundreds of thousands, of concrete concepts to be researched, brainstormed on, and organized. Existing longtermist terminology was typically optimized out of convenience for local situations, with limited regard for wide consistency. This includes having consistent categories for things.
https://ea-crux-project.vercel.app/internal/reports/controlled-vocabulary/
Questions & Critiques:
Why now?
It's only in the last 10 months or so that Claude Code has made it easy to build out wikis and many of the other project components.
Wouldn't the result just be AI slop?
With some work, it seems possible to produce outputs that at very least act as good research summaries. If you are picturing the naive results of chat applications like ChatGPT or the Claude interface, remember that these are minimalist applications that use single LLM calls to be fast and cheap. Extra scaffolding, costs, and runtime can go a long way.
How far can this get using existing AI?
I'm unsure. I think we could have interesting knowledge bases that track, say, 10,000 items, and provide a set of interesting estimates. As projects expand, they become more difficult, and it's possible that this scale will lead to diminishing returns at some point. When doing technical projects, it can be very difficult to get the timing not too early and not too late. It's possible that this sort of project might be a bit too early.
Will the results reflect the biases of the creators?
My goal is to aim for a good mix of "reasonable to the longtermist community" and "few unusual assumptions". This is a tricky balance to get right. There will definitely be some biases and pet worldviews that become part of the project. However, there are some techniques that can help here. One idea is to really attempt to flag any critical and speculative assumptions, then allow users to make adjustments and get personalized takes from that. We'll also try to focus on topics that don't require as many personal worldview assumptions.
Further: Ambitious Potential Diagrams
Below are some example images of what future complex visualizations could look like. These specific images are fancier than what we could provide at this point, and have some nonsense parts, but can be useful to help showcase what we’re aiming for.
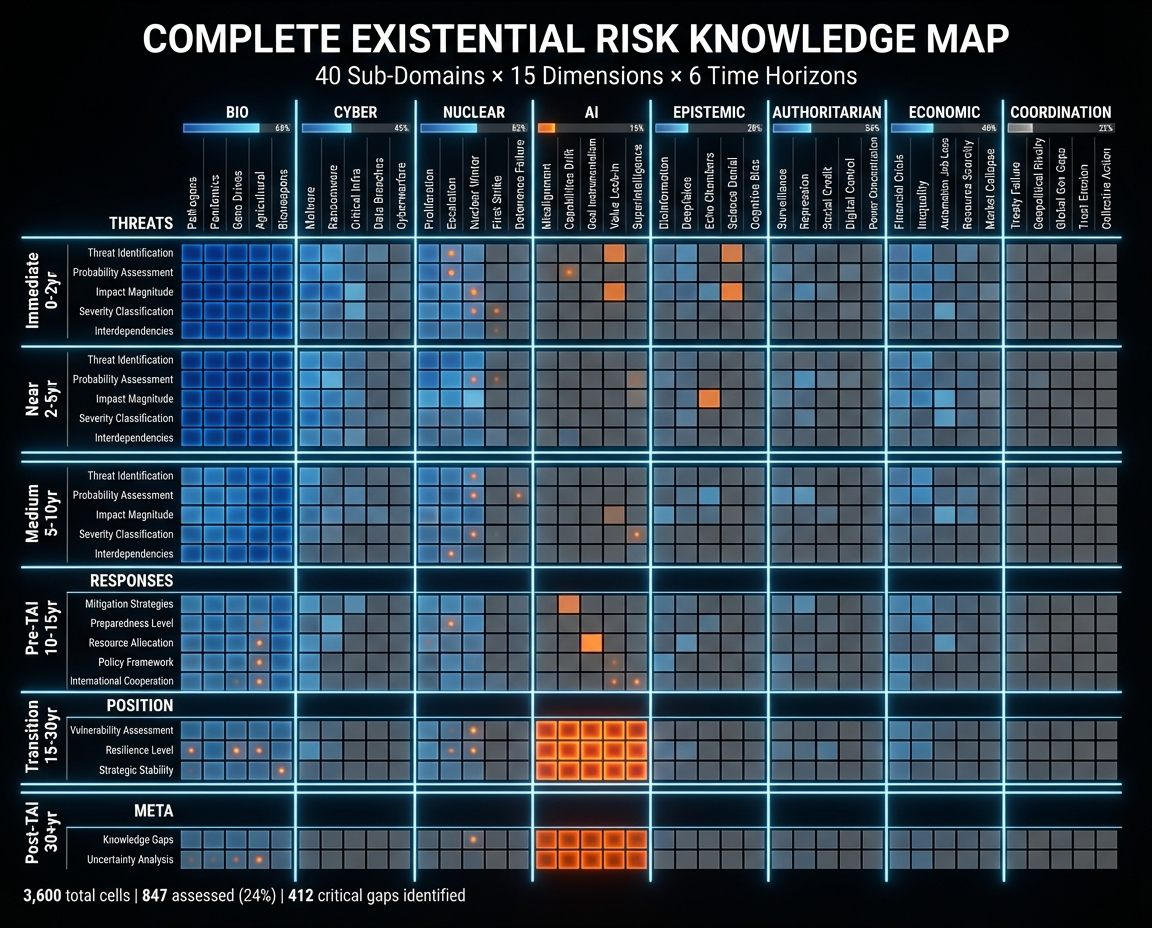
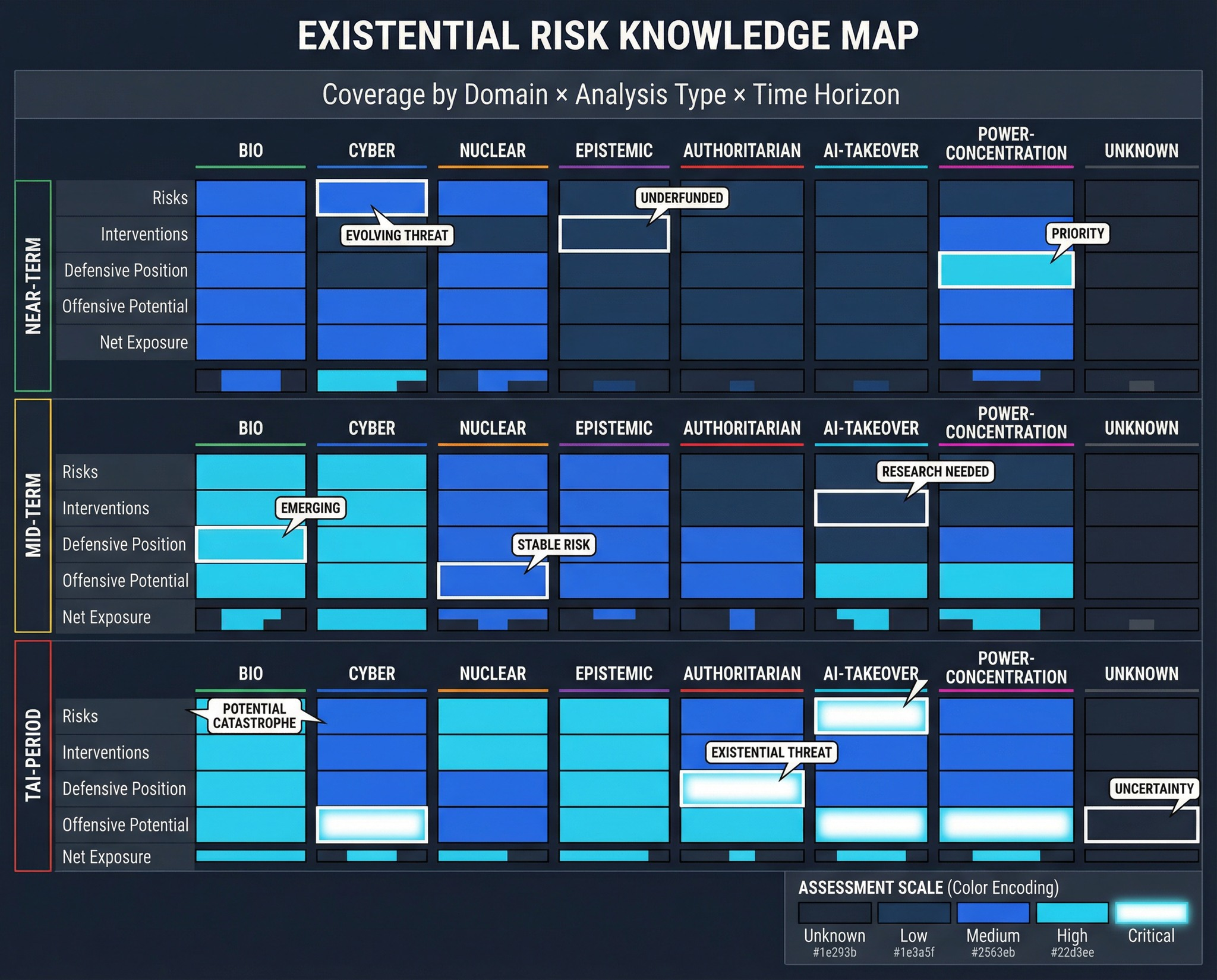
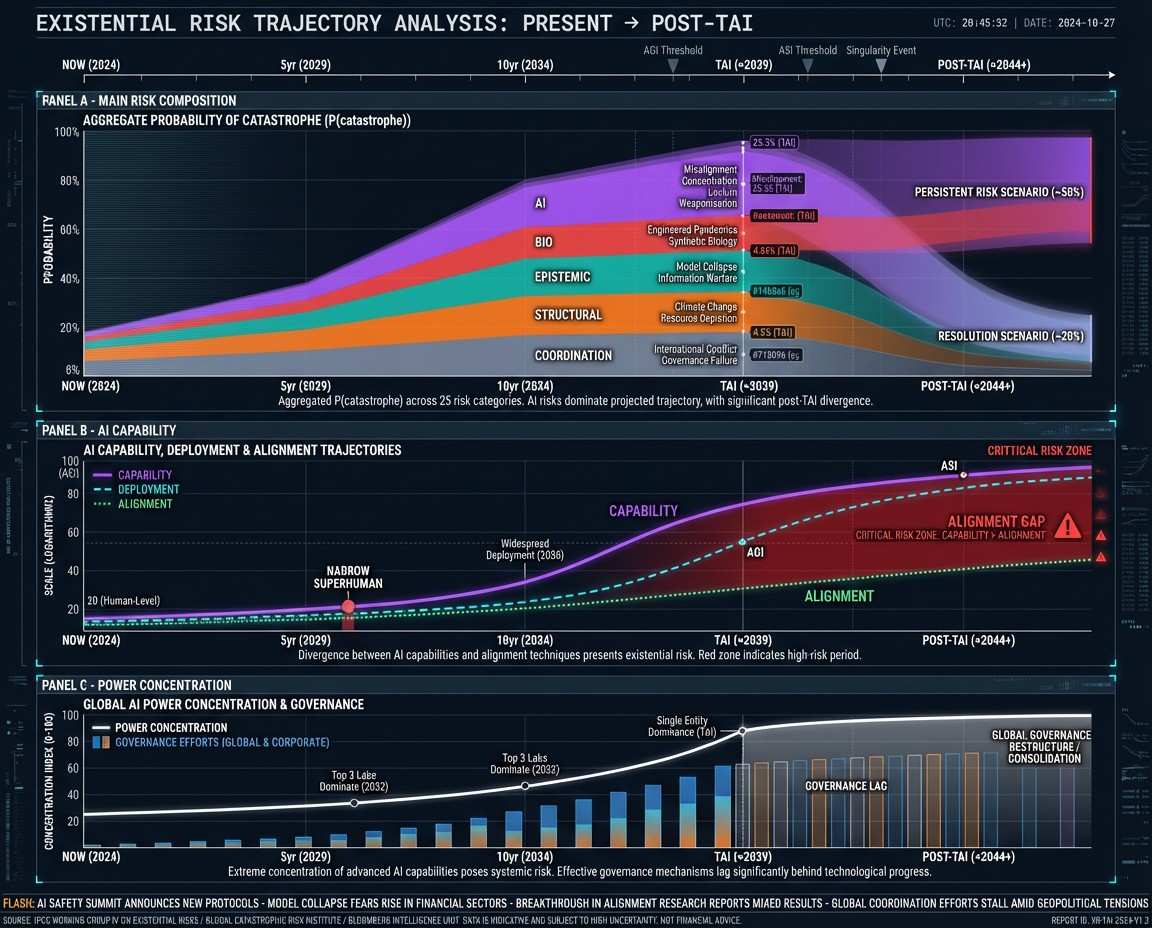
Ponderings on Judgemental Estimation
Forecasting · Methods · — · 4,090 words
Introduction
Judgemental Estimation
Much of the existing literature on Bayesian Statistics relies on idealized models of agent understanding and experimental design. For instance, many models assume logical omniscience, which has been criticized as unrepresentative for human reasoning [1].
Judgemental estimation refers to the kinds of estimates made by forecasters in research on judgemental forecasting; where it is distinguished from statistical estimation. Judgemental estimations do not assume logical omniscience. Reasoners have initial intuitions on probability statements that may be inconsistent with each other.
This idea can be mixed with decision theory such that we can find utility-optimal methods for reasoners to make updates. This is useful for making choices about what kinds of consistency to strive for where there are costs for probabilistic improvements.
Here we are interested in developing a descriptive model of judgemental probabilistic reasoning that can be used for normative purposes. This work may be best viewed in terms of information economics rather than probability theory or epistemology. The concept of “Value of Information” is typically used within information economics. Here we argue that updating should be done in ways that maximize the value of information.
Judgemental estimates can be looked at as equivalent to credences. It's not clear what terminology is best to use here. Credences go by a few definitions in the literature and are typically used for epistemic questions that are typically relatively unrelated for the purposes of this work.
Other related fields are those of judgemental forecasting, from which the term “judgemental” is derived from, and that of cognitive science, which does creates partially realistic models of human learning but is generally more about descriptive details than normative theorizing.
[1] https://plato.stanford.edu/entries/logic-epistemic/#LogiOmni
Theory Status & Request for Feedback
This work is quite early, somewhat poorly researched, and relatively unstructured. It's relatively dense. There aren't many full examples, and where there are, there typically isn't corresponding theoretical rigor. The main goal of this document is to further the development of these ideas, rather than to optimize the explanations or rigor.
I personally don't have much experience writing academic math papers or understanding much of the relevant literature. Arguably, there's a whole lot of relevant literature.
At this point my main concern is to do the following:
- Make sure these ideas on this are online to some capacity.
- Get feedback regarding what aspects may be interesting to others.
- Get advice and assistance what existing literature, notations, and terminology is best for much of this.
- Use this work as something of a theoretical foundation in the development of judgemental prediction services.
Definitions & Key Assumptions
Information Value and Decision Value
A rational agent with preferences that can be modeled as a Von Neumann-–Morgenstern utility function should generally strive to obtain information for the sake of optimizing that utility function.
Here, the obtaining of information is viewed as an instrumental goal. If knowledge of information were to be considered a terminal goal, that could be stated as part of said utility function, and optimization could still be understood as sequences of Expected-Value maximization decisions.
Generally, we expect that for most humans, the vast majority of the benefit of information is instrumental.
Even if the knowledge of information were considered a terminal value, it seems likely that information would have to be prioritized. There are some kinds of information that are generally regarded as more interesting than others.
It's difficult to get precise estimates of value. One estimation method used in Economics is the Willingness to Pay (WTP). A naive version of this may make predictable mistakes, as people may naturally have a poor idea of how much they would value information on much further reflection. Information value refers to the value agents actually get, rather than what they initially believe they get.
One modification could be to incoorporate Enlightened Preferences, as have been discussed by Bryan Caplan. Then we could imagine the Enlightened Willingness to Pay, or EWTP. One could attempt to imagine the EWTP for different individuals and different levels of enlightenment, to best estimate information value or decision value.
Information Value Theoretic Interpretations of Human Phenomena
Information-theoretic interpretations have been theorized as mathematical foundations for many important technical and mathematical phenomena.
To get up-to-date examples, just search "Information-theoretic" in Google Scholar.
Information Theory was derived to assist in technical problems around the transmission of specified information. In "A Mathematical Theory of Communication", Claude E Shannon discussed the necessary theory to understand how to send complete signals given possible sources of noise. Much of future work in Information Theory held a few assumptions:
- The information source is fixed and relatively limited.
- The necessary entropy probabilities can be known in advance and are generally objective.
In many human examples these assumptions do not hold. Humans have the choice of obtaining and sharing vast amounts of information and must select a very small fraction of it for learning. They also have great uncertainty regarding entropy amounts. In conversations, for example, the act of selecting which information to transmit is arguably a higher-variance decision than deciding how to best convey that information to best minimize noise loss.
https://ezproxy-prd.bodleian.ox.ac.uk:2461/chapter/10.1007/978-1-84882-491-1_8 "Information-Theoretic Interpretations" "An Information-Theoretic Interpretation of Thresholds in Probabilistic Rough Sets"
Academic Work as Instrumental Information Value
Academic progress could be viewed through the lens of instrumental value. Doing so would offer interpretations on the efficacies of various strategies, methods, and developments. Arguably, many existing cost-benefit analyses of scientific work have primarily used similar assumptions.
There are other claims that academic work is terminally valuable. This should be expressible in utility functions, but this conversion is highly complicated. Some questions would emerge:
- How can we distinguish highly terminally valuable academic work from non terminally valuable academic work? If we cannot distinguish, should we optimize academic work to get as much information as possible? It's possible this could lead to highly unintuitive results.
- What is the time-weighting of the value of humanity's terminally valuable knowledge? If it were more efficient to spend 500 years growing the economy before engaging in terminal academic work, would that be an optimal trade-off?
Even if instrumental value makes up less value than terminal value, it seems significantly more estimable, or tractable to analyze.
If much of Academic value were to come from instrumental information value, then many high-level questions of science and academic could be partially explained in terms of instrumental information value.
Belief-Relativity
Claim: Two judgemental agents with different priors, and without significant time to communicate with each other (as in Aumann's agreement theorem), should at least occasionally disagree on probabilistic statements in realistic settings; though often to very minor extents.
There are a few assumptions here:
- Both agents have intuitions that are functions of a lot of data about the world.
- It would be infeasible to explicitly describe all of the data responsible for such intuitions, due to a combination of the fact that it may be impossible or very expensive.
- The data from both agents has a lot of divergence; agent A has witnessed a lot of data that agent B hasn't, and vice versa.
- The beliefs of both agents when conditioned on specific new information would not be dominated by that information, in ways influenced by their respective differences in information.
This can be simply stated that agents can be expected to have different priors and likelihood functions, and that these differences can be expected to lead to differences in posteriors.
Here we use the term estimation dominance to refer to an estimate that should be used in place of, instead of in addition to, other estimates of the same variable.
$$P(A|p_{dominant}, p_{i...n}) = p_{dominant}$$
If one takes this claim to be true, we can say that probabilistic statements are belief-relative, meaning that they vary agent to agent based on each agents' existing priors.
Where belief-relativity holds, then there is no such thing as an objective probabilistic statement; in the sense that no probabilistic statement could be expected to be dominant for all recipients.
Because entropy and information quantities rely on probabilities, those would be considered belief-relative.
Some Bayesian writing clarifies this by specifying “general” priors in all Bayesian equations.
$$P(A | \omega)$$ Where $\omega$ is a generic term representing the worldly prior of the given agent.
Mathematical Theory
Decision-Relevant Information
In one sense a noisy picture (just random pixels of black & white) has a high information content, because it is difficult to predict. In a different sense, it has a very low information content, because the only decision-relevant piece of information could be that it's “noise”.
Related, say we are interested in how many coins of a set of coins are heads. We can compress all of the physical information we know about the coins into a very small string, like, “8 coins, each with a negligible bias”. When we do this we don't lose any information that we could predict would be important for the sake of the calculation.
Arguably one important aspect of prediction question operationalization / parameterization is to wind up with a “maximally compressed” representation that contains all of the information that matters, with as little as possible of what doesn’t.
For instance, if one had two choices, A, and B, and wanted to decide between them, they could estimate Utility(A) and Utility(B), but this likely involves unnecessary information. What one really cares about is something like:
$$P(\mathbb{E}(A) > \mathbb{E}(B))$$
Where we can expect that the entropy, H,
$$H(P(\mathbb{E}(A) > \mathbb{E}(B))) < H(\mathbb{E}(A), \mathbb{E}(B))$$
A very simple example of this would be to say that if someone offered you “either $1 or $2”, you wouldn't need to estimate the total impact of each on your utility function; rather, you just need adequate confidence on two subquestions:
- Is $1 < $2?
- Is the expected value of money likely to be positive?
Related to this, we can think in terms of “value of information” to show where information reductions are costly. If we believe our own total expected value conditional on having information $ I_2 $ is the same as that on us having information $ I_1 \supset I_2 $ then this information loss didn't cost any information value.
$$E(Utility | I_1) = E(Utility | I_2 \subset I_1 ) \implies Value(I_2) = Value(I_1)$$
If information can come with some cost in some sense, then one wants to seek the most “compressed” representations.
Note 1: Instead of writing $$P(\mathbb{E}(A) > \mathbb{E}(B))$$ we may want to use the equation $$P(\mathbb{E}(A - B)>0)$$
Note 2: On the equation: $$P(\mathbb{E}(A) > \mathbb{E}(B))$$
This is a bit gnarly because probability is handled both in the $P$ parameter and the $\mathbb{E}$ parameters, so calculation would require careful handling of expectations of possible knowledge gains.
Selecting of Predictions to Minimize Expected Loss
Say we have a set of calibrated predictions $p_{1..n}$ on some claim $\phi$, and we can only choose one to personally use. We would like to minimize the expected loss function that's based on a logarithmic scoring rule.
A naive to do would be to select the prediction with the lowest self-expected loss.
$i_{optimal} = arg min_{i \in {1..n}} \mathbb{E}(S(P_i)| P_i)$
However, there are some situations where this would fail, because the presence of all of the predictions $p_{1..n}$ contains information that would lead one to believe that some predictions are effectively overconfident. Notice the last term of this corrected equation.
$i_{optimal} = arg min_{i \in {1..n}} \mathbb{E}(S(P_i)| P_{i..n})$
The important thing here is that:
$\mathbb{E}(S(P_i) | P_i) \neq \mathbb{E}(S(P_i) | P_{i..n})$
To give a concrete example, say that there are two predictions of the “mean number of a quantity with a population of 50,000” from two predictors that are perfectly modeled as beta distributions from the finding of binary evidence. Both predictors begin with priors of $$P_{prior} = beta(1,1)$$
The first predictor saw 10 points of data and provides the distribution $$P_1 \sim beta(1,12)$$
The second predictor saw all points that the first predictor saw, plus 2 more points: $$P_1 \sim beta(3,12)$$
In this case, if they independently estimated their own expected losses, the first predictor would expect a lower expected loss. The differential entropy (the same as the expected value of a log score) of beta(1,12) is less than that of beta(3,12).
$$H(beta(1,12)) < H(beta(3,12))$$
That said, note that this situation should be expected to be unusual.
One can generally expect that an increase in information leads to a decrease in expected loss, but this is not always the case.
One selection strategy that wouldn't be vulnerable to this specific failure would be to select the prediction that came from the information with the lowest entropy, rather than the prediction that itself had the lowest entropy. Of course, for this to work, we'd only care about the aspects of the entropy of the information that are relevant for the prediction, so this needs to be specified.
Questions:
- Is there are formulaic procedure to specify and then estimate the information content that generated probability estimates, in a way that could be used for prediction selection?
- In some situations, $H(p_1) < H(p_2) \implies p_{optimal} = p_1$.
In others, it may be predictable with some predictably probability $q$. Calculating the likelihood function would help tell us the specifics. It would be interesting to understand this relationship in many kinds of common formulations of data discovery.
- It seems like when we are setting up prediction systems, we may not want to minimize calculated expected loss, but rather minimize uncertainty of the data generating processes that lead to the relevant forecasts. How can we best model this?
- Add information about how to estimate the entropy of the source. Have a good description of the necessary notation.
Selection of Models Informed by Judgmental Intuitions
Say you have 3 ways to estimate the same thing, and these methods produce different answers. What should you do?
Many models of agent behavior assume that the agent is logically omniscient, but real people don't have this property. Real people have judgemental intuitions that are inconsistent with each other. Further, complete consistency of judgemental intuitions can probably be shown to be computationally intractable given any reasonable constraints.
We can start this problem by discussing credences. My impression is that most discussion around credences happens in epistemology.
Say an agent believes: $$cred(Y) = uniform(10,20)$$ $$cred(X) = uniform(5, 7)$$ $$cred(Y = 2X) = 1$$
$$P(Y | cred(Y)) = uniform(10,20)$$ $$P(Y | cred(Y=2X), cred(X)) = uniform(10,14)$$
The agent here has two different available methods to calculate Y; one using their direct credence, and one using a simple calculation. What procedure should this agent use for deciding?
Arguably, this would follow the same logic as in the previous example. We can first assume that these estimates are calibrated (and if not, we can apply a transformation for this to be the case).
Let's call these various estimation methods, and possible ways of combining them while staying calibrated, $P_{1..n}$.
Then,
$i_{optimal} = arg min_{i \in {1..n}} \mathbb{E}(S(P_i)| P_{i..n})$
When in doubt of how to combine them, and when in doubt on how $\mathbb{E}(S(P_i)| P_{i..n})$ differs from $\mathbb{E}(S(P_i)| P_{i})$, then we can make the simpler selection:
$i_{optimal} = arg min_{i \in {1..n}} \mathbb{E}(S(P_i)| P_{i})$
If we aren't sure how to combine different models, then our options for $i$ will be that much smaller.
In the case above, $$\mathbb{E}(S(uniform(10,14))) < \mathbb{E}(S(uniform(10,20))) $$ for a log scoring rule $S$.
Therefore, this agent should generally prefer this low-expected-cost option over the alternative.
I believe some work around Bayesian Epistemology may be relevant here. Some work on Conditional Credences is discussed following this link: http://fitelson.org/bayes/titelbaum_ch3.pdf
Questions:
- I'm sure that there's much cleaner notation and terminology to use for this idea, but I'm not sure what it is or where to search for it.
Prediction and Language
Uncertainty in Question Definitions
In real life, question predictors and evaluators don't completely agree on question definitions. For example, the possible prediction question “How positive will intervention X be for the United States” would generally be considered mediocre, arguably because it would be difficult for predictors and clients to estimate exactly how an evaluator would interpret that question.
This problem could be expanded to the much more general problem that in people don't share exact matches of most definitions or sentences. Not only do people disagree on terminology, but they also cannot perfectly estimate the terminology that others believe.
We can refer to the ability of a person to understand a statement as their comprehension, and to loss that could come out of a failure to do this as comprehension loss.
The big question here is how to best model this explicitly in ways that would be useful for selecting definitions that would minimize comprehension loss.
Interestingly, the ability of an individual to comprehend a statement is very similar of that to estimate a variable. Arguably, comprehension could be defined as a type of estimation over a complex parameterization, which could thus trivially be made into a type of prediction. Therefore we can use much of the same terminology as is used in predictions. For instance, an individual is overconfident in a comprehension if they mistakenly believe a false interpretation with more confidence than is supported by the evidence. Their comprehension could hypothetically be scored using a proper scoring rule against a true statement definition.
Ironically enough, the main area I know of where definition disagreement is well parameterized is that of “Words of estimate probability.” For our purposes we can assume that people will always use exact numbers for probabilities, so we don't need to use this work, but a generalization of it could help with the answers of understanding of common definitions and sentences.
https://en.wikipedia.org/wiki/Words_of_estimative_probability
Hypothetically we can come up with some distance functions between interpretations of a given statement. This is easy when the statement could be neatly parameterized into a single parameter.
Consider the statement:
John Fillmore Smith will drink a lot of water tomorrow
One may make the simplification that all of the uncertainty in this phrase lies in the meaning of “a lot”, which could be estimated as a probability distribution over a unit of volume. If there is a “correct” definition, this could be compared with any other distribution using the KL divergence. A large KL divergence between interpretations would indicate a substantial disagreement or error.
Similarly, one could also imagine that there may be uncertainty in who John Fillmore Smith is referring to, how “water” may be defined, and how “tomorrow” may be defined.
One way to compare these specific uncertainties would be to imagine how they would influence a forecasters' total estimate on how likely this claim is to be true.
Effective Parameterization and Parameterization Loss
The challenge of defining specific forecasting questions has been discussed in literature around the Good Judgement Project and basically anyone who has tried to operationalize forecasting questions for others to use.
The Good Judgement Project has discussed the trade-off of rigor vs. relevance; the idea being that questions can often be either be explicit and easy to verify, or ambiguous though more relevant. For instance, the question, If I eat potatoes, will that help my health? may be useful, but is highly ambiguous. The question, If I eat one potato today, will I report a stomach ache tomorrow? is more specific and verifiable, but also less important than the first question, especially if done to attempt to estimate the first question.
We can define parameterization here as the process of converting an uncertainty into a set of parameterized statements that can be directly estimated using probabilities or probability distributions.
For example, the question: What will happen to me next year? is not well parameterized, but the subquestion, How many hours will I be in REM sleep next year? is.
Often in forecasting setups we have a high-level question we would like forecasters to help provide the answer to, but there is no straightforward way to fully parameterize it in a reasonable matter. In these cases we may choose to parameterize some specific subparts of it. The above example What will happen to me next year? is one example of this.
Say the true question we have is $\phi_1$ and the subquestion can be considered as $\phi_2 \subset \phi_1$. If this was a highly lossy parameterization, then,
$\mathbb{E}(U|\phi_1) \gg \mathbb{E}(U|\phi_2)$
The difference of information about $\phi_1$ between having people forecast $\phi_1$ and $phi_2$ can be considered the parameterization loss.
Parameterization Loss and Comprehension Loss
Some parameterizations come with statement definitions that we can predict will be poorly comprehended. We can look at information losses due to miscomprehension as comprehension loss.
This leads to a possible conflict of parameterization loss vs. comprehension loss for various possible statements. Vague parameterizations may have low parameterization loss, but would have comprehension loss. Narrow parameterizations would likely have high parameterization loss, but hopefully low comprehension loss.
It's often possible to use a 'brute force' strategy of using very large number of very specific parameterizations. This could lead to low parameterization losses and comprehension losses. However, it may be very expensive. Parameterization and comprehension losses can be looked at as limitations of benefits, but benefits typically have to be considered with costs.
Future Work & Questions
Expected Loss
In this presentation, I discuss the concept of “Expected Loss“ and how it can be used to make decisions about forecasting setups. Does this make sense? Is there any related literature I should be familiar with?
https://www.youtube.com/watch?v=zTBp0Lmw4ZE&t=1721s
One general assumption here is that we don’t have to worry about all kinds of calibration errors; the main one that we need to worry about is systematic and predictable overconfidence, so that’s really the main element to estimate and adjust for.
Entropy of Distributions
Differential entropy is the naive version of entropy to use for distributions, but it's “not nice“. Differential entropy is unit-dependent and can be negative. Arguably one better construct is to use the limiting density of discrete points, but this seems to require the use of a uniform distribution with unspecified bounds. In many judgemental cases, it's not clear what these bounds should be.
Overall I haven't been able to find much discussion or many examples of how to best use the limiting density of discrete points, or other approaches to entropy besides that and differential entropy.
https://en.wikipedia.org/wiki/Limiting_density_of_discrete_points
Resulting Issues
If a forecaster reduces the uncertainty of $X \sim Uniform(100,200)$ by 30%, they would have a much higher score than one that reduces the uncertainty of $X \sim Uniform(1,2)$ by 30%.
If I have a variable $X \sim Uniform(1,2)$ I would like to understand how transformations to X result in information loss about X. The transformation $$Y = 2 X$$ should hypothetically lead to 0 information loss if specified correctly; but the differential entropy would obviously increase. The specification here may include the fact that one knows that this transformation occurred.
Say that that the information that “Y came from X“ is described by the variable $i$. Then, $$P(Y | i) \neq P(Y)$$
Related, if $H$ is the information entropy on a variable, then, $$H(X) = H(Y | i)$$
{kind=link}